版权信息 书名:深入浅出AI智能体:基于DeepSeek的AI Agent开发实战
ISBN:978-7-115-69262-7
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
版 权 著 饶 侠
责任编辑 杨海玲
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线: (010)81055410
反盗版热线: (010)81055315
内 容 提 要 本书以DeepSeek大模型为核心,系统介绍AI智能体全栈技术。全书共14章,采用“基础理论-开发实践-前沿技术-企业落地”的递进结构,首先阐述AI智能体的核心概念、技术架构与DeepSeek大模型原理,详解提示词工程、RAG、向量数据库等关键技术;随后深入讲解扣子、Dify等平台的开发方法,以及单智能体开发、多智能体系统开发的技巧;进而探讨通用AI智能体、MCP/A2A等智能体协议、上下文工程、多模态AI智能体等前沿方向;最后聚焦企业级部署和行业落地实践。本书紧跟技术前沿,整合LangChain、RAGFlow、LangGraph等主流框架与项目,直面私有化、安全性、合规性等真实挑战,全面覆盖从AI智能体的基础概念到企业级落地的完整知识体系。
本书适合具有一定Python编程基础的读者阅读,可供从事AI应用开发、算法研究、企业智能化转型等工作的技术人员和项目经理使用,也可作为人工智能、计算机科学相关专业学生的参考书。
前 言 近年来,人工智能 (artificial intelligence,AI)技术,尤其是大语言模型 (large language model,LLM,本书中简称大模型)及其衍生的AI智能体 (artificial intelligence agent,AI Agent)技术迅猛发展,深刻改变了我们与数字世界交互的方式。从自动化任务处理到复杂决策支持,从单智能体独立工作到多智能体协作系统,AI智能体已成为推动产业智能化变革的核心力量。在这一背景下,深入理解并掌握AI智能体的开发与实战应用显得尤为重要。
本书立足于当下技术前沿,系统介绍AI智能体的基础理论、关键技术、开发方法与实战案例。书中内容以DeepSeek大模型为核心,结合多个主流开发框架及平台,旨在为读者提供一条从入门到精通的高效学习路径。
全书共14章,内容涵盖AI智能体与DeepSeek、AI智能体开发环境、提示词工程、知识库与RAG、单智能体开发与多智能体系统开发、通用AI智能体构建、AI智能体协议、AI智能体进阶技术、大模型的企业级部署与企业级知识库搭建、企业级AI智能体的开发与部署,以及AI智能体的行业落地与前沿探索。每章都融合了理论讲解与代码实战,力求在阐明原理的同时提升读者的动手能力。
DeepSeek作为全球领先的开源大模型之一,不仅具备卓越的推理与生成能力,还拥有开放的生态和成本优势,非常适合用于AI智能体的开发与实验。本书强调“基于DeepSeek”的实战导向,提供了大量完整可运行的示例代码,涵盖API调用、AI智能体开发、RAG应用搭建、多智能体协作等典型场景,帮助读者在真实环境中巩固知识。
本书适合具有一定Python编程基础的读者阅读,可供从事AI应用开发、算法研究、企业智能化转型等工作的技术人员和项目经理使用,也可作为人工智能、计算机科学相关专业学生的参考书。
人工智能时代正在加速到来,AI智能体作为连接人与机器、数据与决策的关键桥梁,必将发挥越来越重要的作用。希望本书能为读者打开一扇窗,帮助读者在智能体的世界中探索、实践与创新,最终成为推动技术变革的参与者与创造者。
谨向所有致力于AI技术推广与开源的开发者、研究者和企业致敬。
愿读者在阅读本书的过程中有所收获,与我一起走向更智能的未来。
第1章 AI智能体与DeepSeek 在当今科技飞速发展的时代,人工智能(AI)已经成为一个热门话题。AI智能体作为AI领域的一个重要概念,正逐渐改变着我们的生活和工作方式。
本章将详细介绍AI智能体的定义、技术架构和应用等。
1.1 什么是AI智能体智能体 (agent)是由被誉为“人工智能之父”的计算机科学家马文·明斯基(Marvin Minsky)在20世纪60年代提出的,他将其定义为一种自主运行的计算或认知实体,具备感知环境、推理决策和执行任务的能力。他在1986年出版的著作《心智社会》(The Society of Mind )中把思维描述为由大量相互作用的智能体构成的复杂系统,每个智能体都执行特定的任务,并通过特定方式协作完成复杂的认知活动。这一思想为智能体的研究奠定了理论基础。
在这一概念提出后的近40年时间里,许多计算机领域的人才都致力于智能体的研究,相继诞生了许多出色的成果,如IBM的深蓝、谷歌的AlphaGo等。但直到最近几年,随着以GPT(generative pretrained transformer)为首的一批大模型的诞生,智能体才在AI领域发扬光大,AI智能体的热度也随之攀升。(特别说明,本书主要介绍AI智能体的开发,书中后续提及的智能体均指AI智能体。)
1.1.1 AI智能体简介 简单来说,AI智能体是一种自主软件工具,能够智能且理性地执行任务、做出决策,并与所处环境进行交互。AI智能体利用AI技术,基于实时反馈和不断变化的条件进行学习、适应并采取行动。AI智能体既可以独立工作,也可以作为更大系统的一部分,根据所处理的数据进行学习和变化。
AI智能体与其他AI技术的不同之处在于它具有自主行动的能力。与其他需要持续人工输入的大模型不同,AI智能体可以主动发起行动,根据预定义的目标做出决策,并实时适应新环境。这种独立运行的能力使AI智能体在软件开发等复杂、动态的环境中极具价值。
AI智能体结合了先进算法、机器学习技术和决策过程。AI智能体通常包含以下3个组成部分。
(1)架构和算法 。AI智能体构建于复杂系统架构之上,机器学习算法帮助AI智能体从经验中学习,并随着时间的推移不断改进,这使其能够处理大量数据并做出明智决策。
(2)工作流程 。AI智能体的工作流程通常始于特定的任务或目标,然后它会制订行动计划,执行必要的步骤,并根据反馈进行调整。这一过程使AI智能体能够不断提升性能。
(3)自主行动 。AI智能体可以在无人工干预的情况下执行任务,这使其成为自动化软件开发中执行重复性操作(如代码评审或漏洞检测)的理想选择。
1.1.2 AI智能体的类型 AI智能体可以分为很多种类型,每种类型适用于不同的应用场景,下面是AI智能体的几种主要类型。
• 简单反射智能体 。这类智能体仅根据当前环境状态采取行动,通过预定义规则做出决策。
• 基于模型的反射智能体 。与简单反射智能体不同,这类智能体会维护一个世界的内部模型,能够考虑过去的行动并预测未来状态。
• 基于目标的智能体 。这类智能体在工作时有特定目标,做出的决策会使它们更接近于实现这些目标。
• 基于效用的智能体 。这类智能体会考虑不同的结果及其发生的可能性,最终选择能最大化其效用或收益的行动。
• 学习型智能体 。这类智能体可以从环境和经验中学习,随着时间的推移提高自身性能。
多个AI智能体可以协同部署,以处理复杂任务。协同工作使AI智能体在软件开发和其他行业中更加高效。
1.1.3 AI智能体的应用 AI智能体已经对很多领域产生重大影响,主要如下。
在医疗保健领域 ,AI智能体用于自动化执行日常任务、分析医疗数据,并辅助诊断和治疗。
在制造领域 ,AI智能体可优化生产流程、监测设备健康状况,并预测维护需求,从而减少停机时间并提高效率。
在金融服务领域 ,AI智能体可帮助金融机构检测欺诈活动、自动化交易,并通过个性化交互提升客户服务的质量。
在零售和电子商务领域 ,AI智能体可优化供应链、管理库存并提升客户体验。例如,AI智能体可以预测需求趋势、制定个性化营销策略,并通过聊天机器人自动化客户服务交互,从而帮助零售商降低成本、提高效率,并更好地满足客户需求。
在能源和公用事业领域 ,AI智能体可用于优化电力的生成和分配、管理智能电网,并预测设备维护需求。它们还在能源交易和需求预测中发挥作用,帮助公用事业公司更有效地平衡供需并降低运营成本。
在运输和物流领域 ,AI智能体可以优化路线、管理车队运营,并预测车辆的维护需求。它们也可用于自动驾驶汽车,使自动驾驶汽车能够做出实时决策。AI智能体还能改善仓库管理并简化供应链运营。
在电信领域 ,AI智能体用于网络优化、客户服务自动化和基础设施的预测性维护。它们能帮助电信公司更高效地管理大规模网络、减少停机时间,并提供个性化的客户服务。
在教育领域 ,AI智能体正变得越来越重要。它们可提供个性化学习服务、自动化执行行政任务,并为学生提供实时反馈。AI驱动的课程辅导系统可以适应不同学生的学习风格和节奏,提供定制化支持以提高学生的学习效率。
1.2 AI智能体的技术架构为了理解智能体内部的工作机制,我们需要探讨AI智能体的核心模块、设计模式和推理引擎等。
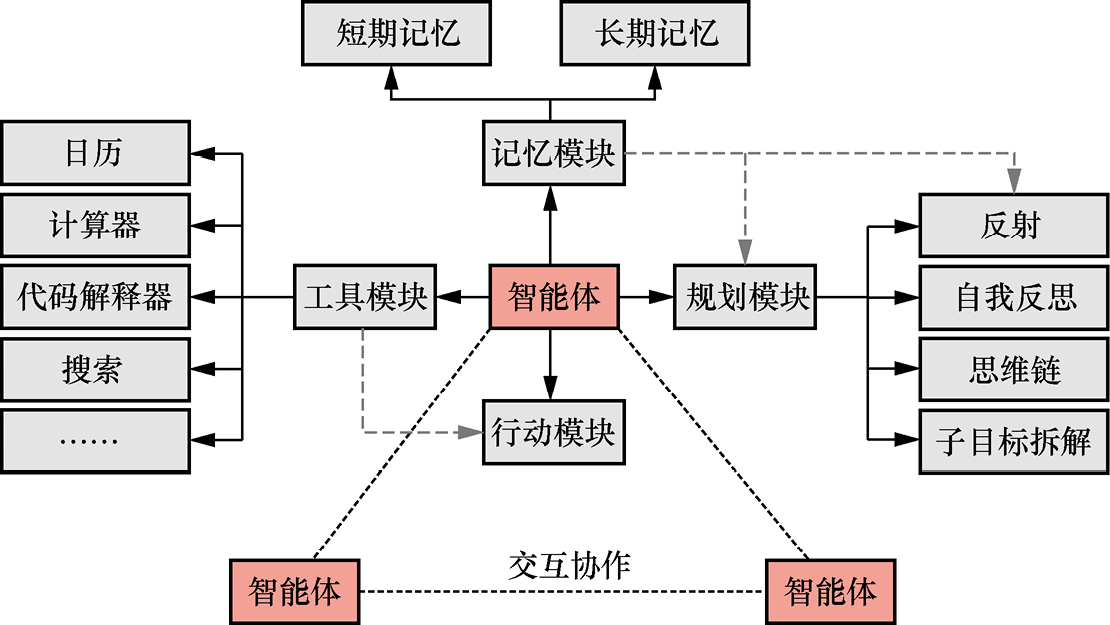
1.2.1 AI智能体的核心模块 在基于大模型的AI智能体中,大模型充当着AI智能体的“大脑”。一般来说,AI智能体包含记忆模块、规划模块、工具模块和行动模块4个核心模块,如图1-1所示。
图1-1 AI智能体的核心模块
(1)记忆模块 负责存储信息,信息既包括AI智能体过去的交互和学习到的知识,也包括临时的任务信息。有效的记忆机制对AI智能体来说至关重要,使其能够在遇到新的或复杂问题时调用过往的经验和知识。记忆又分为短期记忆和长期记忆两种,短期记忆用于上下文学习 (in-context learning),而长期记忆则通过外部数据库和快速检索,为AI智能体提供长时间保留和回忆信息的能力。
(2)规划模块 包括事前规划和事后反思两个阶段。事前规划涉及对未来行动的预测和决策,可帮助AI智能体高效地规划步骤和行动以实现目标。事后反思则让AI智能体能够检查和改进规划,从错误中学习并将学习成果加入长期记忆,从而更新对世界的认知。规划的方法包括反射、自我反思、思维链和子目标拆解。
(3)工具模块 使AI智能体能够利用外部资源或工具执行任务。例如,它们可以调用外部应用程序接口 (application program interface,API)来获取模型数据中缺失的信息,或者使用特定软件分析大量数据。这提升了AI智能体的工作效率和任务完成能力。
(4)行动模块 是AI智能体实际执行决策和响应的部分。AI智能体拥有一系列行动策略,可以根据不同任务选择相应的行动,如记忆检索、推理、学习和编程等。
1.2.2 AI智能体的设计模式 2024年3月26日,吴恩达教授在红杉资本的人工智能峰会上发表了主题为“Agentic Reasoning”的演讲。他在演讲中表达了自己对AI智能体未来发展的观点、思考和展望,并分享了当下AI智能体的4种主流设计模式,即反馈(reflection)、工具使用(tool use)、规划(planning)和多智能体协作(multi-agent collaboration)。
(1)反馈设计模式 是一种让大模型通过自我反思和迭代改进来提高任务执行能力的方法。在这种模式中,大模型不仅会生成初始解决方案,还会通过多次反馈和修改,不断优化输出。
(2)工具使用设计模式 是一种让大模型通过调用外部工具或库来增强任务执行能力的方法。在这种模式中,大模型不只依赖自身的知识和能力,还会利用各种外部资源完成任务,从而提高任务执行效率和准确性。
(3)规划设计模式 是一种通过提前计划和组织任务步骤来提高任务执行效率和准确性的方法。在这种模式中,大模型将复杂任务分解为多个步骤,并依次执行每个步骤,以实现预期的目标。
(4)多智能体协作设计模式 是一种通过多个智能体之间的合作来提高任务执行效率和准确性的方法。在这种模式中,多个智能体分担任务,并通过相互交流和协作,共同完成复杂任务。
1.2.3 AI智能体的推理引擎 AI智能体的推理引擎(也称认知框架或推理框架)是其规划和制定决策及调用工具执行行动的核心。推理引擎利用快速发展的提示词工程技术及相关框架指导推理和规划,使AI智能体能够更有效地与环境互动并完成任务。
当前,提示词工程框架和大模型任务规划领域的研究正在迅速发展,产生了多种有前景的推理引擎,如推理与行动 (Reason and Act,ReAct)、思维链 (Chain of Thought,CoT)和思维树 (Tree of Thoughts,ToT)等。
(1)ReAct是一种提示词工程框架,提供了一种思考过程策略,可帮助大模型推理并根据用户输入采取行动,无论是否有上下文示例。ReAct框架已被证明在多个关键指标上优于很多先进的基线模型,还增强了人类与大模型之间的互操作性,并提高了大模型的可信度。
(2)CoT是一种通过中间步骤实现推理能力的提示词工程框架。CoT包括各种子技术,如自我一致性、主动提示和多模态CoT,每种技术在具体应用中都有其优势和劣势。
(3)ToT是一种非常适合探索或战略性前瞻任务的提示词工程框架。它扩展了CoT的概念,允许模型探索多种可能的思维路径,作为解决通用问题的中间步骤。
AI 智能体可以利用上述一种或多种推理引擎,针对给定的用户请求制定最佳的下一步行动策略。
其中,ReAct框架脱颖而出,被LangChain和LlamaIndex等多种AI应用开发工具作为推理引擎。它提供了一个强大而灵活的结构,可用于开发能够进行复杂推理和有效行动的AI智能体。
1.2.4 AI智能体与外部交互 尽管大模型在处理信息方面表现出色,但它们缺乏直接感知和影响现实世界的能力,这限制了它们在需要与外部系统或数据交互的情况下的实用性。从某种意义上说,大模型的性能仅限于其训练数据涵盖的内容,无论向模型投入多少数据,它们依然缺乏与外部世界互动的基本能力。那么,如何赋予大模型与外部系统进行实时交互和感知上下文的能力呢?可以通过函数调用、插件扩展和数据存储等来实现。
1.函数调用 函数调用 是一种实现大模型与外部工具连接的机制。通过API调用大模型时,用户可以描述函数,包括函数的功能描述、请求参数说明、响应参数说明,让大模型根据用户的输入选择调用哪个函数,同时理解用户的自然语言,并将之转换为调用函数的请求参数(以JSON格式返回)。用户使用大模型返回的函数名和参数调用函数并得到响应,然后把函数的响应传给大模型,让大模型组织成自然语言回复用户。
2.插件扩展 插件扩展 可以独立于AI智能体创建,但应作为AI智能体配置的一部分提供。AI智能体在运行时使用模型和示例来决定哪个插件扩展最适合解决用户的问题。这突出了插件扩展的一个关键优势,即它们内置的示例类型允许AI智能体动态选择最适合某项任务的插件扩展。插件扩展能够通过调用外部API等方式,赋予AI智能体其原本不具备的功能,极大地扩展了AI智能体可执行操作的范围。
插件扩展一般可分为3类:一是信息增强插件 ,可以帮助用户获取实时信息和专业信息,如股票价格、最新新闻等;二是服务增强插件 ,可以帮助用户自动化执行一些常见的任务,如预订航班、订餐等;三是交互增强插件 ,可以接收知识库、PDF文件、图片、语音等多模态输入,并生成表格、思维导图等多模态输出。
3.数据存储 数据存储 提供了一种机制,使模型能够访问最新信息,确保其响应基于最新的事实并具有相关性。数据存储通过将用户传入的原始文档转换为一组向量 (vector)来工作,这些向量可以被智能体用来提取所需的信息,从而为其下一步行动或对用户的响应决策提供补充。
数据存储通常实现为向量数据库 (vector database)。向量数据库是一种特殊的数据库,专为存储高维向量数据而设计。它使AI智能体能够在运行时快速检索和使用相关信息。检索增强生成 (retrieval-augmented generation,RAG)技术使AI智能体可以快速访问各种格式的数据(如网站内容,PDF、CSV文件等),从而扩展模型知识的广度和深度。
以上这些机制可能有不同的名称,它们共同构成了连接基础大模型与外部世界的桥梁,使AI智能体不仅能执行各种任务,还能更准确、可靠地完成任务。例如,AI智能体可以调整智能家居设置、更新日历、从数据库中获取用户信息,或者根据特定的指令集发送电子邮件。
1.2.5 智能体工作流 传统意义上的工作流是指一系列按照预定义规则和顺序执行的任务或步骤,通常用于描述业务流程或操作的结构化执行路径,强调的是过程的标准化和自动化,确保任务按部就班地完成。
传统工作流通常基于流程图或状态机,使用流程管理工具(如BPMN、Airflow等)实现,适用于结构化、可重复的任务。例如,在软件开发中,一个典型的工作流可能是“代码提交→代码评审→测试→部署”,每个步骤都有明确的前后依赖和触发条件。
在AI时代,工作流和AI智能体并非对立,而是融合为智能体工作流 (agentic workflow)。作为新兴的工作流程管理方法,智能体工作流将传统工作流与AI智能体结合来自动化和优化业务流程。智能体工作流以大模型为技术基础,通过多个AI智能体的协作,将复杂任务分解为可管理的子任务,并通过迭代细化实现目标系统。
简单来说,工作流是蓝图,AI智能体是执行者。工作流提供清晰的步骤和秩序,适合可预测的任务,AI智能体则赋予系统智慧和灵活性,使其能应对复杂多变的环境。二者的界限正在模糊,结合使用往往能带来更大价值。
工作流实现标准化的3种典型模式是链式工作流 (chain workflow)、并行化工作流 (parallelized workflow)和路由工作流 (routing workflow),而AI智能体通过动态决策能力扩展了工作流的应用边界。
1.链式工作流模式 链式工作流模式将多个步骤按线性顺序组织,一个步骤的输出作为下一个步骤的输入,形成连续的处理链,通过明确的步骤顺序简化了复杂任务的处理流程。每个步骤都依赖于上一步的输出,确保了数据的准确性和一致性。
链式工作流模式适用于任务具有明确顺序且每个步骤都依赖于前一步骤的输出的场景,如新闻推荐系统中的内容筛选和排序。
2.并行化工作流模式 并行化工作流模式通过同时执行多个任务或处理多个数据集,提高数据密集型操作的效率,显著缩短整体处理时间,这样就可以合理分配计算资源,提高系统的吞吐量,使系统易于扩展以处理更大规模的数据集和任务。
并行化工作流模式适用于任务可以独立执行,需要快速处理大量数据或多个请求的场景,如大数据分析、实时监控和复杂决策支持系统。
3.路由工作流模式 路由工作流模式根据输入条件动态选择执行路径,使系统能够在没有预定义序列的情况下适应不同情况。这种工作流模式能够根据不同的输入条件选择不同的处理路径,将任务路由到最合适的节点,提高了资源利用率。
路由工作流模式适用于任务处理依赖于输入特征,且不同特征需要不同的处理流程的场景,如金融服务平台根据用户感兴趣的主题将请求路由到不同的API端点。
1.3 什么是DeepSeekDeepSeek是由杭州深度求索人工智能基础技术研究有限公司研发并开源的大模型系列,其长期目标是迈向通用人工智能 (artificial general intelligence,AGI)。(杭州深度求索人工智能基础技术研究有限公司成立于2023年7月,隶属于幻方量化,其目标是通过高性能、低成本的开源大模型技术,推动AI技术在多领域的普及与应用。)
2025年初杭州深度求索人工智能基础技术研究有限公司基于DeepSeek大模型发布了一款推理型AI聊天机器人产品,其名称也是DeepSeek,这一产品一经发布便迅速攀升至140多个国家的苹果App Store下载排行榜首位,在Android应用市场中同样占据榜首位置。DeepSeek应用发布两周,全平台用户数就达到1亿,超过ChatGPT,成为全球用户数增长最快的AI应用。若无特别说明,本书提及的DeepSeek均指DeepSeek大模型系列。
1.3.1 DeepSeek的核心特点 DeepSeek大模型有以下4个核心特点。
(1)模型性能卓越 :DeepSeek-R1模型在多项基准测试中与OpenAI o1模型性能相当,且在中文理解与生成任务中表现更优。
(2)成本优势显著 :相比同类模型,DeepSeek大模型的训练成本和推理成本大幅降低,从而大大降低了企业应用门槛。
(3)开源生态繁荣 :完全开源模型架构及训练细节,吸引全球开发者参与优化,形成了活跃的技术社区。
(4)多场景应用 :覆盖教育、政务、医疗、电子工程等领域,可辅助教师备课、生成文旅宣传文案、解析电路图纸等。
DeepSeek主要有以下两个具有代表性的模型。
(1)DeepSeek-V3 :支持 128K(128000 token)上下文窗口的对话模型,擅长多轮交互与复杂推理。
(2)DeepSeek-R1 :基于强化学习的推理模型,专攻代码生成与数学问题求解,支持实时知识更新。
1.3.2 DeepSeek的模型架构创新与训练优化策略 DeepSeek的技术路线以效率与精准性为核心,结合了多项模型架构创新与训练优化策略。
DeepSeek的模型架构创新有以下3点。
(1)混合专家 (mixture of expert,MoE)模型 :采用稀疏激活的MoE架构,每个词元(token)仅激活8个专家,减少了计算资源消耗。
(2)多头潜在注意力 (multi-head latent attention,MLA):通过低秩压缩技术减少键值缓存 (key-value cache)内存占用,提升长文本处理效率。
(3)多词元预测 (multi-token prediction,MTP):同时预测多个未来词元,增强生成连贯性,提升推理速度。
DeepSeek融合了预训练、监督微调(supervised fine-tuning,SFT)、强化学习及模型蒸馏等多种技术手段,通过分阶段、多轮次的训练迭代,最终构建了既具备强大推理能力,又能与人类偏好高度对齐的开源对话模型。
DeepSeek的训练优化策略有以下4种。
(1)混合并行策略 :结合数据并行与模型并行,通过梯度压缩、异步通信及计算与通信重叠技术,降低节点间通信延迟,提升图形处理单元 (graphics processing unit,GPU)利用率。
(2)双向管道并行策略 :优化数据传输与计算流程,实现前向和后向计算与通信的完全重叠,减少流水线中的空闲时间,提升训练效率。
(3)专家并行与负载均衡策略 :智能分配计算任务,通过动态调整路由偏置或复制高负载专家,避免节点过载,提升系统资源利用率。
(4)FP8混合精度训练策略 :采用8位量化技术,降低存储与通信成本,大幅提升训练效率。
1.3.3 DeepSeek的调用方式 为了满足不同场景下的需求,DeepSeek提供了灵活多样的调用方式,主要有以下两种。
(1)云端调用 :通过官方或第三方(如阿里云、火山引擎)API快速接入,适合轻量化需求。
(2)本地部署调用 :支持下载满血版模型(671B)或蒸馏版模型(如7B),需配置高性能GPU服务器,适用于数据敏感场景。
1.云端调用 要实现云端调用,需要先申请官方API密钥。官方API密钥的申请过程如下。
打开DeepSeek官网,其首页如图1-2所示。
图1-2 DeepSeek官网首页
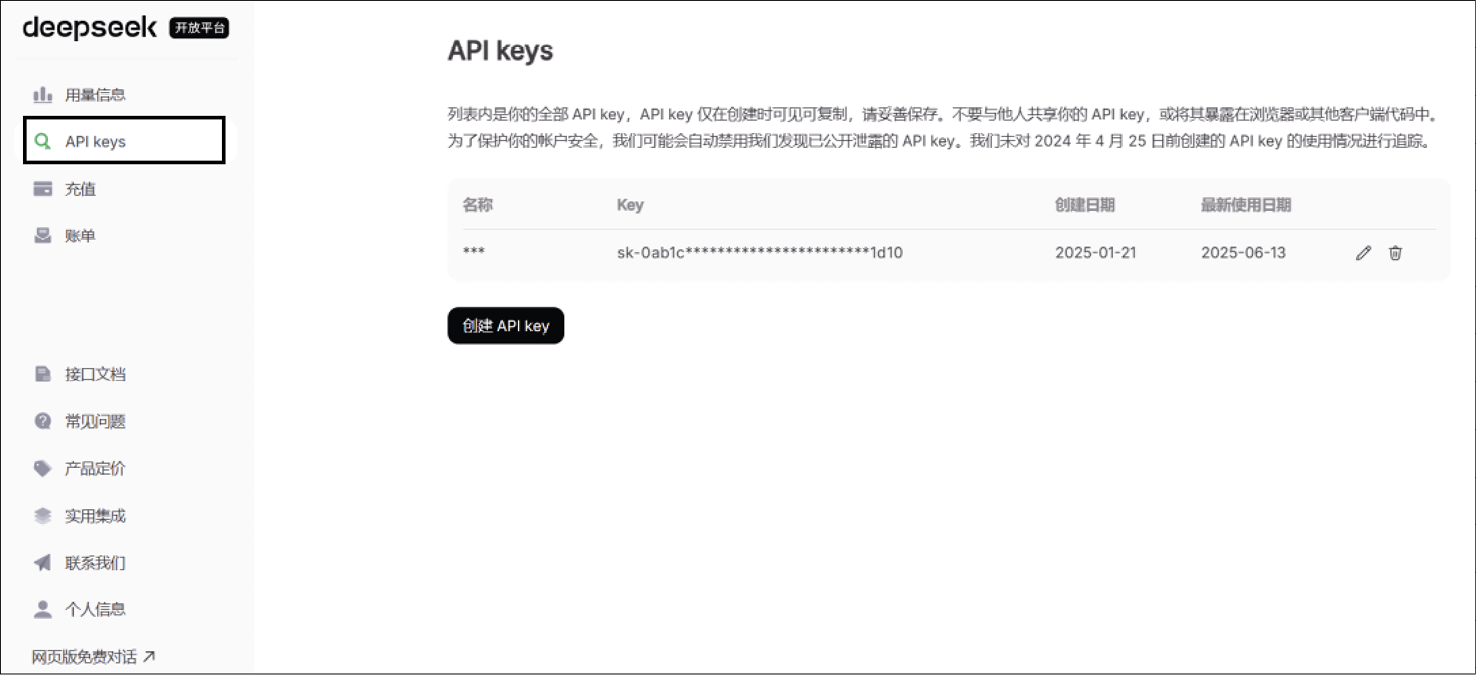
单击首页正中的“API开放平台”按钮,登录后选择左侧菜单中的“API keys”,如图1-3所示。
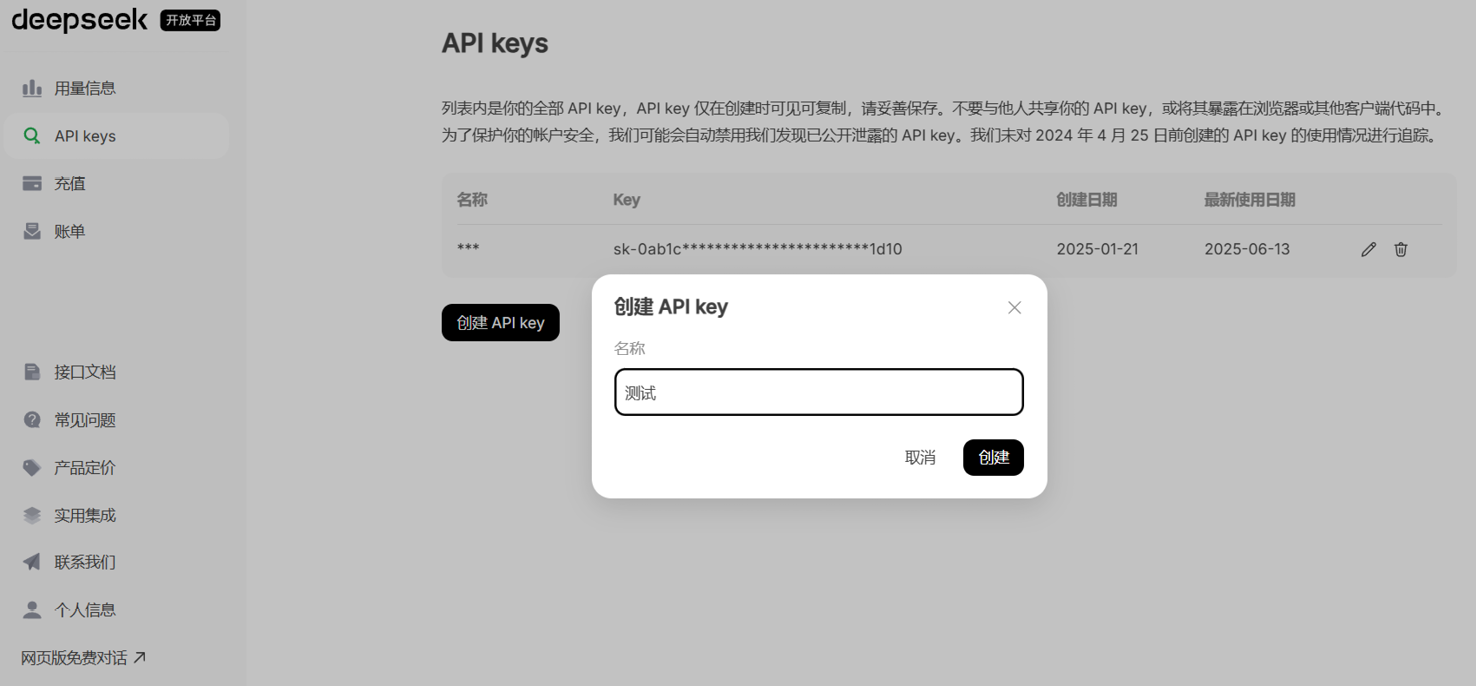
单击“创建API key”按钮,弹出“创建API key”对话框,如图1-4所示。
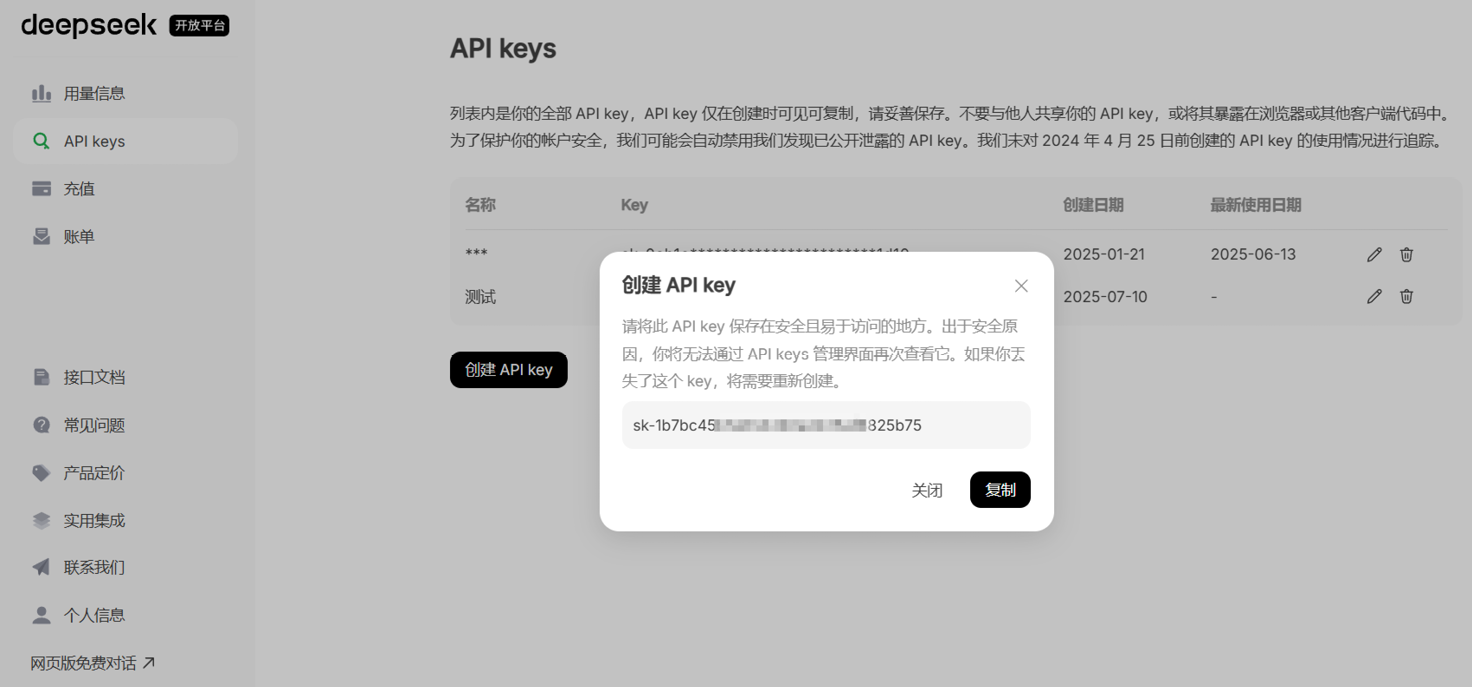
输入API密钥名称,单击“创建”按钮,即可成功创建API密钥。成功创建API密钥后弹出的对话框如图1-5所示。单击弹出的对话框中的“复制”按钮,就可以复制API密钥。
图1-3 DeepSeek的“API keys”页面
图1-4 “创建API key”对话框
图1-5 成功创建API密钥后弹出的对话框
很多第三方厂商(如字节跳动、硅基流动等)基于DeepSeek开源版本搭建了模型,并对外提供API服务。下面以字节跳动的火山引擎为例,介绍第三方API密钥的申请过程。
先打开火山引擎官网,进入火山引擎的登录页面,如图1-6所示。
图1-6 火山引擎的登录页面
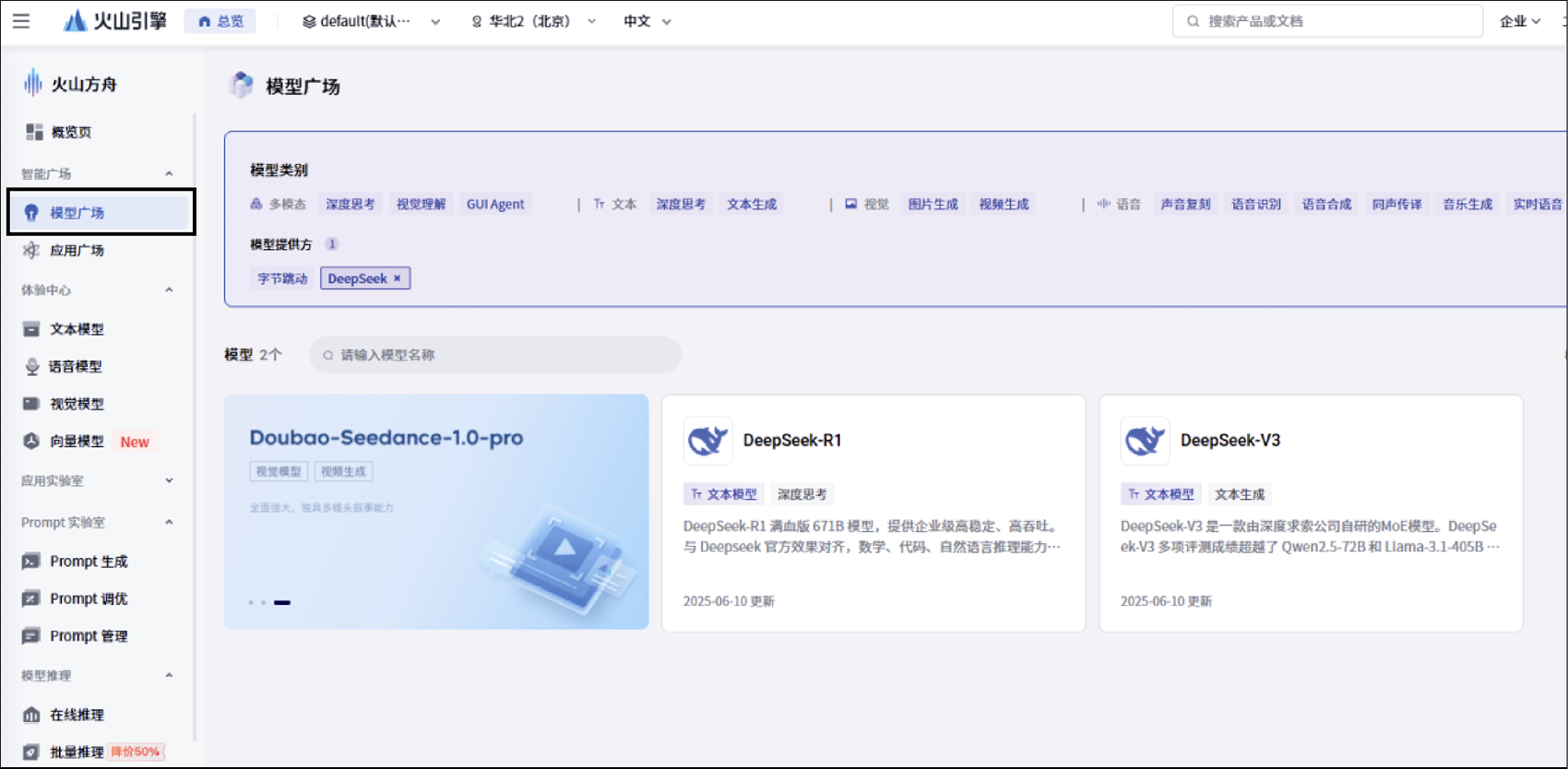
登录后选择页面左侧的“模型广场”,可看到其目前支持的所有模型,如图1-7所示。
图1-7 火山引擎的“模型广场”页面
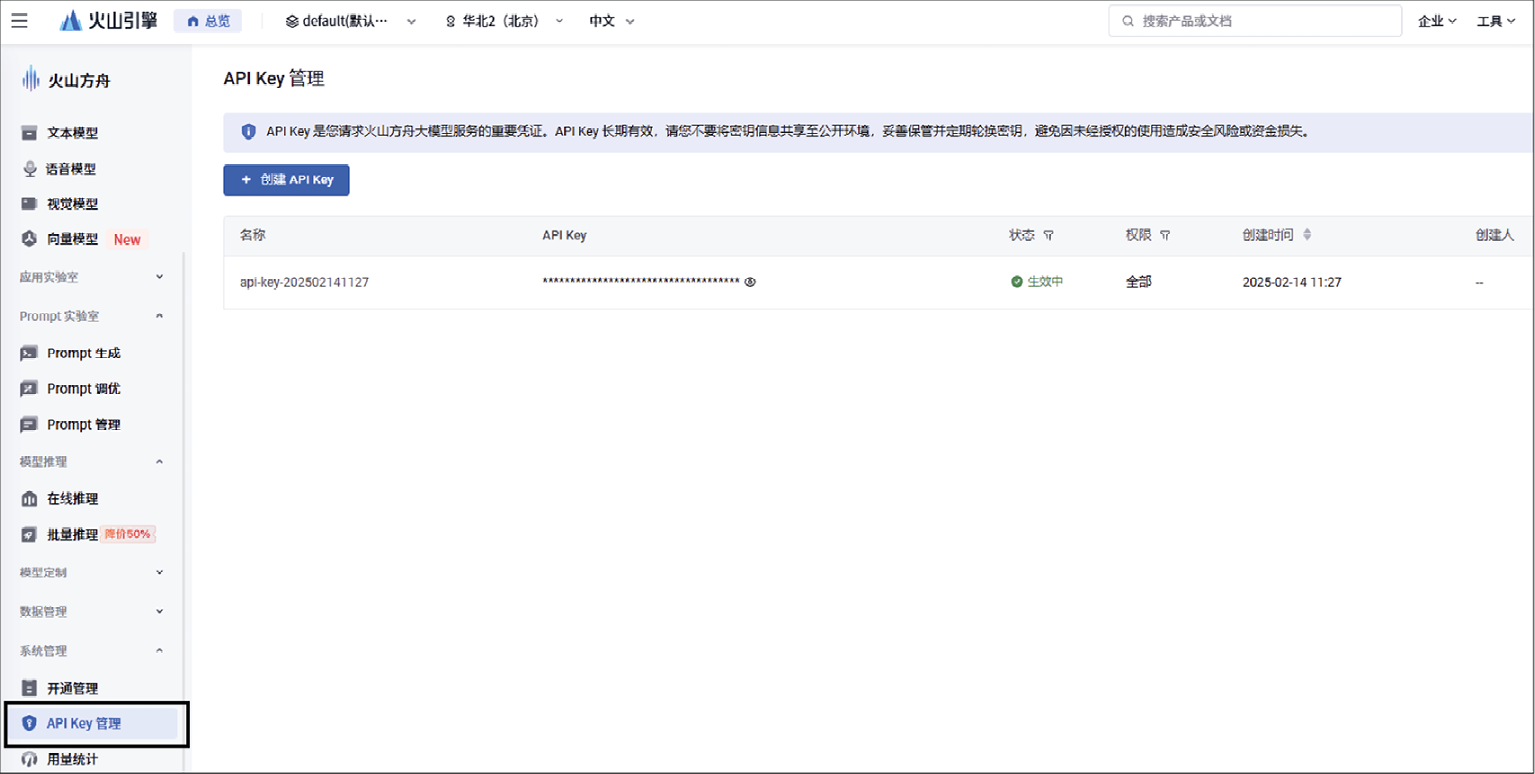
选择页面左侧的“API Key管理”,可创建API Key,如图1-8所示。
图1-8 火山引擎的“API Key管理”页面
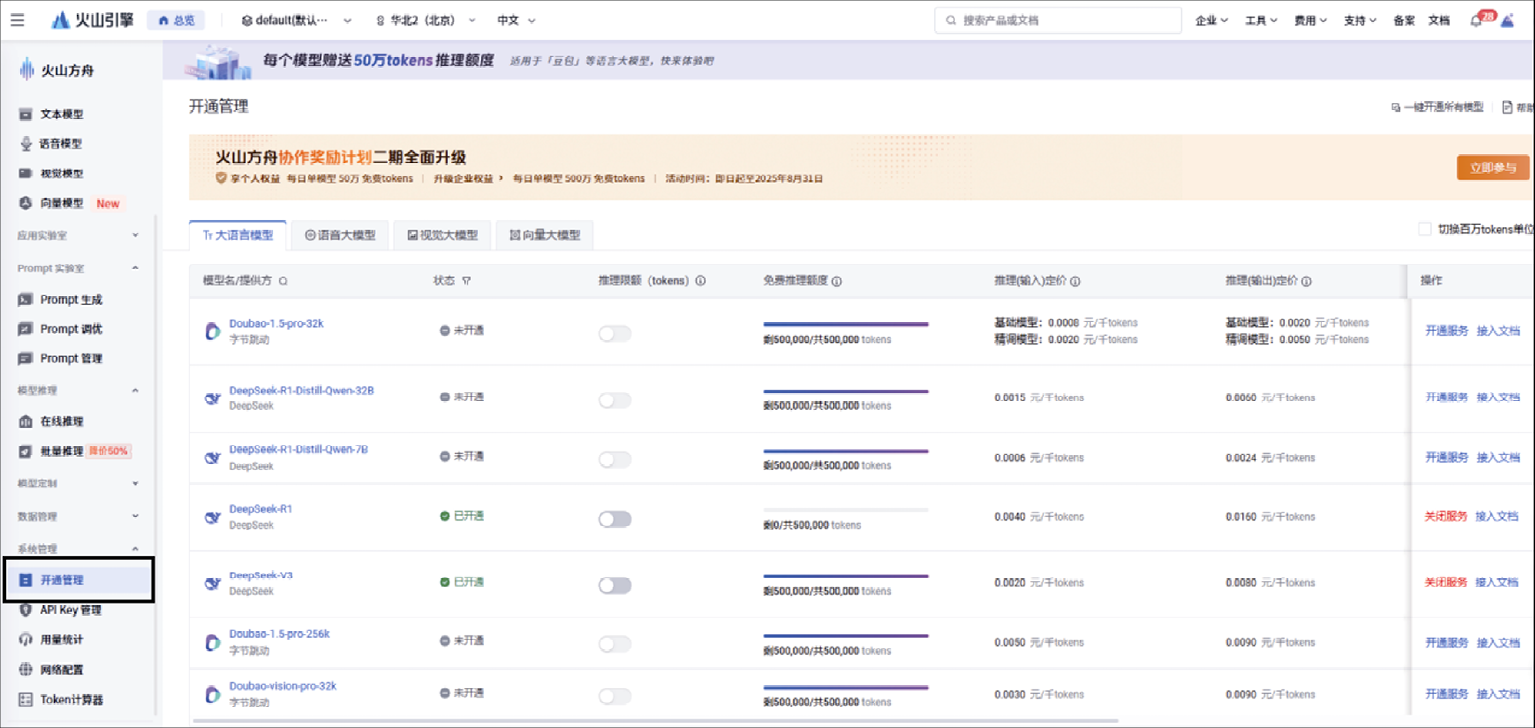
选择页面左侧的“开通管理”,可开通需要的模型服务,如DeepSeek-R1,如图1-9所示。
图1-9 火山引擎的“开通管理”页面
2.本地部署调用 在本地部署DeepSeek大模型需要有一定的技术基础,涉及硬件支持(如GPU)、Python环境安装、深度学习框架(如PyTorch或TensorFlow)使用等。
下面是本地部署DeepSeek大模型的GPU方案(推荐)。
• 1.5B模型:大于或等于8 GB的显存(如NVIDIA RTX 3060)。
• 7B模型:大于或等于10 GB的显存(如NVIDIA RTX 3080)。
• 70B模型:大于或等于40 GB的显存(如NVIDIA RTX A6000)。
目前高性能GPU比较昂贵,如果想在普通计算机上部署DeepSeek大模型,也可以采用CPU方案运行轻量级版模型。但这类模型速度较慢,仅适合处理轻量级任务。
本地部署DeepSeek大模型还需要跨平台工具Ollama(支持Windows、macOS、Linux,可一键安装管理模型)和Python环境(Python 3.8以上版本)的支持。
本地部署DeepSeek大模型的流程(Ollama方案)如下。
(1)安装Ollama。打开Ollama官网,进入下载页面,如图1-10所示。选择与所用操作系统匹配的版本下载,然后进行安装即可。
图1-10 Ollama的下载页面
(2)搜索DeepSeek模型。在Ollama官网搜索“deepseek”,结果如图1-11所示。
图1-11 在Ollama中搜索“deepseek”的结果
(3)选择要拉取的模型,以代表DeepSeek-R1模型的“deepseek-r1”为例,如图1-12所示。
图1-12 Ollama的DeepSeek-R1模型页面
然后,在命令行窗口中执行拉取和运行命令。以拉取deepseek-r1:1.5b模型为例,命令如下:
ollama run deepseek-r1:1.5b 该命令执行成功后,DeepSeek的本地部署完成,开发者就可以通过在某些AI桌面客户端(如Chatbox)配置Ollama或通过Ollama提供的API来调用DeepSeek。(DeepSeek大模型的企业级部署方案将在第10章中介绍。)
1.3.4 DeepSeek的生态 DeepSeek在Hugging Face、GitHub累计被140多个国家的开发者下载,注册量破亿。DeepSeek用“极致开源+极致成本”把大模型从“烧钱重工业”变成“随手可用的水电煤”,并正在通过端云协同和行业深耕,重塑国产乃至全球大模型生态格局。
由于核心模型永久免费,因此DeepSeek未来可通过企业级技术支持、订阅服务、行业定制解决方案实现可持续盈利,实现商业闭环。目前DeepSeek在政务、金融、医疗、教育、交通等行业通过概念验证 (proof of concept,POC)持续落地,让中小企业无须自建算力即可调用百亿参数模型。
DeepSeek的生态可以用“开源内核+低成本杠杆+端云协同”来概括。
(1)开源内核 。DeepSeek已将模型、代码、训练方法全部开放。
• 主模型 :DeepSeek-R1(对标OpenAI o1)和DeepSeek-V3(位于开源模型排行榜首)已向全球开放权重和训练脚本,采用宽松MIT协议,允许免费商用与二次开发。
• 专业分支 :DeepSeek-Prover-V2-671B(数学定理证明)、DeepSeek-Coder(代码生成)等场景化模型持续开源,形成覆盖通用与垂直任务的矩阵。
• 蒸馏小模型 :6个尺寸(1.5B至70B)的小模型全部放出,API定价仅约为OpenAI的3%,直接降低了开发者接入门槛。
(2)低成本杠杆 。DeepSeek的架构创新极大地降低了训练成本,对国产算力的适配已跑通华为昇腾、沐曦、天数智芯、摩尔线程、壁仞等国产GPU,实现了“用得起、跑得动”。凭借架构创新和对国产算力的适配,DeepSeek将训练与推理成本压缩至行业低位。
(3)端云协同 。DeepSeek支持端侧部署和云侧服务,一端一云、随处可用。
• 端侧部署 :通过模型压缩与量化,把7B~30B轻量级模型塞进PC、手机、车载设备、智能家居,实现了本地推理和低延时,保护用户隐私。
• 云侧服务 :多个国产云平台已上架DeepSeek全系列模型,提供一键调用、弹性扩缩容等功能,并支持私有化落地方案。
DeepSeek凭借其创新的技术架构、低成本优势与开源生态,正加速推动AI技术的普惠化。未来,随着多模态支持与因果推理能力的突破,DeepSeek或将成为AGI发展的重要里程碑。
实战:DeepSeek API调用示例 在DeepSeek官网创建API密钥之后,就可以使用下面的样例脚本调用DeepSeek API了。以下样例使用的是非流式输出,将stream设置为true便可以使用流式输出。
通过curl调用DeepSeek API的方式如代码清单1-1所示。
代码清单1-1
curl <DeepSeek官方API地址>/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <DeepSeek API Key>" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}' 通过Python调用DeepSeek API的方式如代码清单1-2所示。
代码清单1-2
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="<DeepSeek官方API地址>")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content) 通过Node.js调用DeepSeek API的方式如代码清单1-3所示。
代码清单1-3
// 请先安装OpenAI SDK: `npm install openai`
import OpenAI from "openai";
const openai = new OpenAI({
baseURL: '<DeepSeek官方API地址>',
apiKey: '<DeepSeek API Key>'
});
async function main() {
const completion = await openai.chat.completions.create({
messages: [{ role: "system", content: "You are a helpful assistant." }],
model: "deepseek-chat",
});
console.log(completion.choices[0].message.content);
}
main(); 这段代码可扩展为支持多轮对话循环,以适合智能客服、教育辅导等场景。
在第三方(如火山引擎)API 网站创建 API 密钥之后,就可以使用下面的样例脚本来调用DeepSeek API。
通过Python调用火山引擎DeepSeek API的方式如代码清单1-4所示。
代码清单1-4
import os
# 升级方舟SDK到最新版本:pip install -U 'volcengine-python-sdk[ark]'
from volcenginesdkarkruntime import Ark
client = Ark(
# 从环境变量中读取您的方舟API Key
api_key=os.environ.get("ARK_API_KEY"),
# 深度思考模型耗费时间会较长,请您设置较大的超时时间,避免超时,推荐30分钟以上
timeout=1800,
)
response = client.chat.completions.create(
# 替换<MODEL>为Model ID,可在官方文档模型列表获取所需Model ID
model="deepseek-r1-250528",
messages=[
{"role": "user", "content": "我要研究深度思考模型与非深度思考模型区别的课题,怎么体现我
的专业性"}
]
)
# 当触发深度思考时,输出思维链内容
if hasattr(response.choices[0].message, 'reasoning_content'):
print(response.choices[0].message.reasoning_content)
print(response.choices[0].message.content) 实战:基于DeepSeek API实现函数调用 函数调用是一种使大模型能够识别何时应该调用外部函数并生成符合函数要求的参数的技术。这项技术允许模型与外部工具、API和服务进行交互,搭建了大模型与现实世界系统之间的桥梁。简而言之,函数调用让模型能够通过调用外部工具来增强自身能力。
代码清单1-5以获取用户当前位置的天气信息为例,展示了基于DeepSeek API实现函数调用的完整Python代码。
代码清单1-5
from openai import OpenAI
def send_messages(messages):
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools
)
return response.choices[0].message
client = OpenAI(
api_key="<your api key>",
base_url="<DeepSeek官方API地址>",
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather of an location, the user should supply a
location first",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
}
},
"required": ["location"]
},
}
},
]
messages = [{"role": "user", "content": "How's the weather in Hangzhou?"}]
message = send_messages(messages)
print(f"User>\t {messages[0]['content']}")
tool = message.tool_calls[0]
messages.append(message)
messages.append({"role": "tool", "tool_call_id": tool.id, "content": "24℃ "})
message = send_messages(messages)
print(f"Model>\t {message.content}") 这个示例的执行流程如下。
(1)用户询问现在的天气。
(2)模型返回function get_weather({location: 'Hangzhou'})。
(3)用户调用function get_weather({location: 'Hangzhou'}),并将函数的输出传给模型。
(4)模型返回The current temperature in Hangzhou is 24℃ .。
注意,上述代码中的get_weather()函数需由用户提供,模型本身不提供也不执行具体函数。