版权信息
书名:大学生豆包全场景攻略 学业、生活、求职一本通
ISBN:978-7-115-69408-9
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
版 权
著 北京大学朱郑州团队
责任编辑 王旭丹
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线:(010)81055410
反盗版热线:(010)81055315
序 言
从工业时代、信息时代到今天的智能时代,大学学习的形态一直在演进。工业时代,课堂是中心,教材是载体,教师是主要信息源;信息时代,线上线下混合学习成为常态,学习突破了时空边界;而当下,以大模型为代表的人工智能,正在深刻重构知识的组织与获取方式——资料整合即时完成,文本结构快速生成,复杂问题迅速拆解。越来越多学生在学习、科研和实践中主动使用AI工具,这已非局部现象,而是鲜明的时代趋势。
我在北大主讲《软件工程技术专题》课程时,每年都会邀请若干领域专家来做讲座。近年来,分享的内容日益聚焦于人工智能,信号十分清晰。去年开设的新课《基于多智能体技术的软件开发方法》,反响出乎意料,让我真切感受到同学们对AI技术的高度接纳。借助AI,一些以往只有本专业研究生或资深专家才能完成的任务,现在普通本科生也能高质量完成。
然而,人工智能并非旨在取代学习本身,它真正改变的是学习的方式。如果学习仅停留于机械完成任务,那么工具越强大,深度思考反而越容易被弱化。学习的核心,始终在于理解问题本质、构建知识结构、形成独立判断,并实现迁移与创新。工具可以压缩重复性劳动,却无法替代人的价值判断。真正的差距,不在于谁更早使用技术,而在于谁能在技术环境中依然保持方法的清晰与能力的稳定。
在长期教学实践中,我始终坚信:教育的终极目的,不是培养会使用某种工具的人,而是发现并唤醒人的内在潜能。这样的人,在环境剧变时依然能准确识别问题、重建认知框架、提出创新方案,不会因工具迭代而茫然无措。
人工智能正使“人机协同学习”成为新常态。协同的关键在于合理分工:信息处理与初步计算可交由工具高效完成,而价值权衡、方向抉择与伦理判断必须由人承担。提示词设计、复杂任务拆解、结果校验与反思,本质上都是思维能力的体现。工具是思维的放大器,而非决策主体。《道德经》有云:“朴散则为器。”工具固然便利,但若失去对根本问题的把握,便容易迷失于手段而忘了目的。《论语》进一步点明:“君子不器。”真正有学养的人,不应像器具那样功用固化。教育的使命,正是引导人超越“器”的局限,成为能够应对变化、整合资源、创造价值的“君子”。
本书围绕大学生的真实场景展开:课程学习、考试准备、科研训练、社团实践、求职规划、日常生活管理。我们试图回答的核心问题,并非“如何操作某个工具”,而是“在新技术条件下,如何保障并提升学习的内在质量”。每一章都以问题为起点,以能力养成为目标,正所谓“天下难事必作于易,天下大事必作于细”——无论是驾驭新技术,还是锤炼真本领,都需要从易处入手,于细处深耕,在持续实践中构建稳定可靠的方法体系。
技术发展越快,教育越需明确自身方向。我们希望培养的,绝非依赖工具完成任务的人,而是能够“勤学、修德、明辨、笃实”,在变幻莫测中保持清醒判断力,在复杂环境中持续学习、洞察真问题并勇于创新创业的人。人工智能的兴起,不仅没有削弱学习的意义,反而对学习的质量提出了更高层次的要求。
中国科学院院士、北京大学教授杨芙清先生曾精辟指出,教师应“传道授业启惑”,点明教育精髓在于启发学生提出真问题;王阳元院士亦直言“学问就是学会问问题”。杨先生还强调,人才培养须“面向产业、面向领域,培养高层次、实用型、复合交叉型、国际化人才”,并分享秘诀——“主动、自主、质量”。这些真知灼见,深刻揭示了教育中历久弥新的核心:技术会更新,工具会迭代,但判断力、自主学习力与创新思维,终究深植于人本身。这正是“君子不器”在当代的回响。
2026年3月
前 言
随着人工智能技术的快速发展,大学生的学习方式、能力结构和成长路径正在发生深刻变化。工具不再只是辅助手段,而逐渐成为学习、科研、创作与职业发展的重要组成部分。在技术快速演进的背景下,如何正确理解并高效使用智能工具,已成为大学生成长过程中无法回避的现实课题。
本书正是在此背景下,为大学生量身打造的一本实用指南。全书以场景为主线,以问题解决为导向,系统介绍如何将豆包这一智能工具融入大学学习与生活的关键环节,帮助读者在真实任务中提升效率、深化理解,并逐步形成可迁移的能力。
全书结构清晰,由入门到进阶、由学习到应用、由当下到未来,层层递进。第一篇从认知层面切入,阐释为什么需要学会使用豆包,并系统讲解提示词设计、AI幻觉控制与智能体构建等基础能力,为后续应用奠定方法论基础。第二篇与第三篇聚焦大学生核心的学习场景,涵盖日常课程学习、练习与考试、课程大作业以及英语与外语学习,重点阐述如何借助智能工具提升理解深度、发现薄弱环节、构建系统化复习框架。
第四篇围绕文献检索、长文阅读、论文写作与定性分析等科研关键环节展开,帮助有科研需求的大学生建立更加高效、规范的研究流程。第五篇与第六篇则将视角拓展至课堂之外,系统介绍智能工具在方案策划、文案撰写、PPT 制作、考研、公务员考试、求职准备以及实习与职场工作中的实际应用,突出能力转化和场景迁移。
在此基础上,本书第七篇~第九篇还覆盖编程、绘画和日常生活等多个方向,展示人工智能工具在技术学习、创意表达和生活管理中的多样化应用。最后的第十篇从人机协作的角度,对未来学习方式和职业形态进行理性思考,引导读者建立长期视角,理解工具演进背后所需的能力变革。
需要说明的是,本书由北京大学朱郑州团队联合撰写。团队成员包括多位本科生与研究生,来自人工智能、教育技术、信息科学等多个学科方向,在不同章节中贡献了各自的实战经验与方法论总结。部分章节紧密结合当代大学生真实学习与应用场景,增强了本书的实用性与可迁移性。
本书并非一本简单的工具操作说明书,而是始终围绕一个核心目标展开:帮助大学生在人工智能时代形成更高效、更主动、更可持续的学习方式。书中反复强调工具的边界与人的主体性,倡导在使用智能工具的同时,保持清晰的问题意识、结构化思维能力和自我反思能力。
本书适合希望提升学习效率的在校大学生学习,也适合正在进行科研训练、求职备考或探索多元能力发展的读者阅读。通过大量具体场景与可操作方法,本书力求让人工智能真正成为大学生成长过程中的助力,而不是负担。
本书编委会
主编 朱郑州
编委 黄昱然 北京大学区域经济学博士
苏小文 北京大学软件工程硕士
潘 江 北京大学软件工程硕士
翟自洋 北京大学电子信息硕士
付楚君 北京大学工程管理硕士
祝学居 北京大学软件工程硕士
贾一萌 北京大学软件工程硕士
金靓瑶 北京大学电子信息硕士
荆 菁 北京大学软件工程硕士
王雨生 北京大学软件工程硕士
曾 通 北京大学电子信息硕士
王永民 北京大学电子信息硕士
徐 斌 北京大学软件工程硕士
石一鹏 北京大学电子信息硕士
余绍鹏 北京大学工程管理硕士
陈勃翰 北京大学工程管理硕士
贾政童 北京大学软件工程硕士
程翔瑞 北京大学信息科学技术学院本科生
贾富淼 北京大学经济学院本科生
王奕涵 北京大学工学院本科生
第一篇 入门篇
几年前,如果一个大学生在自习室里同时摊开三本教材、一本笔记本、一个平板和一台电脑,大多数人并不会觉得奇怪;而今天,在同样的场景下,你更可能看到的是:一个屏幕、一段对话,以及不断被拆解和重组的问题。学习的外在形态,正在悄然发生变化。
这种变化并不是突然出现的。最初,只是有人用智能工具查资料、改语法;随后,有人开始用它梳理概念、生成提纲;再后来,它逐渐进入课程学习、考试复习、科研写作的核心环节。到今天,越来越多的学生已经意识到:不使用智能工具,并不意味着更认真;不会使用,反而意味着效率和视野的双重受限。
但真正的分水岭,并不在于“用不用”,而在于“会不会”。同样是使用AI,有人只是把它当作答案机器,有人却能借助它把问题拆得更清楚、把知识连得更紧密、让学习成为一种可持续的过程。差距,正在这里迅速拉开。在进入具体技巧之前,更重要的是先回答三个问题:为什么现在需要学会使用豆包?豆包在学习中究竟扮演什么角色?怎样使用,才不会被工具牵着走?
第1章 为什么现在需要学会使用豆包
每一代人都会经历技术跃迁,但并非每一次跃迁都能直接重塑学习本身。今天正在发生的变化,恰恰属于后者。人工智能已不再只是提高效率的工具,而是开始承担理解、生成与推演等原本只属于人的认知工作。当智能可以被随时调用,学习就不再等同于记忆与训练,而转向判断、协作与选择能力的竞争。豆包正是在这一背景下出现的:它不是为了替你完成作业,而是正在改变你如何获取知识、组织信息和形成观点的方式。如今,学会与AI协作,已经不是选择题。
1.1 未来已来,你不能缺席
历史并非总是连续、平缓地向前推进。它更像一条漫长的河流,大多数时候缓慢流淌,但在某些关键节点,会突然发生断裂式跃迁——旧世界在短时间内崩塌,新世界迅速成型。而这些节点,往往由一种“新生产力”触发。
1.1.1 新生产力的降维打击
如果把时间拉长到几百年尺度,人类社会的结构性变化几乎都源自同一个源头:工具对人的替代。
18世纪中叶,第一次工业革命爆发。在那之前,纺纱是一项高度依赖熟练工人的手工劳动。一个熟练纺纱工需要多年训练,才能稳定、高质量地完成工作。纺纱工人因此形成了相对稳定的职业群体,拥有议价能力,也构成了当时制造业的核心。
1764年,珍妮纺纱机(见图1-1)出现。它的意义并不是“稍微提高了一点效率”,而是一个普通工人借助机器,就能完成过去几十个熟练工人才能完成的产量。结果并不温和:大量传统纺纱工迅速失业,技能贬值,社会结构被迫重组。反抗机器的卢德运动并未能阻止历史进程,机器最终胜出,因为它代表的是更高层级的生产力。

图1-1 卢德运动期间,愤怒的纺纱工人正在砸毁珍妮机
类似的例子不断重复出现:马车夫被内燃机取代、打字员被计算机取代、胶片冲洗师被数码摄影取代、收银员被自动结算系统取代……
这些变化有一个共同的规律:不是“人被机器淘汰”,而是旧能力被新生产力降维打击。
历史从不关心个人是否努力、是否勤奋、是否品德高尚。它只关心一件事:谁掌握了更高效的生产方式。
1.1.2 第四次工业革命:智能开始替代认知
前三次工业革命,本质上都发生在“体力”和“信息传递”层面。蒸汽机、电力、计算机,解决的是力量、速度、规模和连接问题。
而正在发生的第四次工业革命,性质则完全不同。
这一次,被替代的不再是肌肉,也不仅是简单操作,而是认知本身。
在前三次工业革命中,人类至少还可以通过再教育进入新的岗位;而在AI革命中,许多岗位本身正在被彻底消除,连转型的空间都在迅速收窄。
历史一再证明:当一种新生产力出现时,问题从来不是要不要接受,而是——谁先适应,谁就活在新世界;谁拒绝学习,谁就被留在旧时代。
而对大学生而言,这一规律正在以最快的速度逼近。
如果说前几次工业革命改变的是生产方式,那么这一轮人工智能革命,正在直接改变学习本身的形态。更准确地说,它正在摧毁过去两百年逐步形成的一整套学习逻辑。
可以预见的是,在同一所大学、同一个专业、同一个年级中,学生之间的差距将以前所未有的速度拉开。一部分人将借助AI快速建立起自己的能力飞轮,理解更深、视野更广、行动更快;另一部分人则会发现,自己即便付出了努力,也始终跟不上节奏,逐渐被边缘化。这种差距并不源于天赋,而源于是否站在新生产力一侧。
1.2 豆包,你的全能助手
豆包是字节跳动基于Seed大模型自主研发的AI产品,是大学生的实用智能助手。它适配学习备考、论文构思、创意创作等多元场景,能够精准解答知识问题,提供结构化面试与学习指导,还能完成文案撰写、图片设计、文档处理等任务。在内容生成上,豆包兼顾逻辑严谨与表述精准,能按需求迭代优化输出结果,为大学生的学习、备考和日常创作提供高效、个性化的智能支持。
1.2.1 极速成长:豆包的技术发展历程
从内部测试到成为国民级AI助手,豆包(见图1-2)仅用了短短几年时间,便完成了从0到1、从1到亿的跨越式发展。其迭代节奏之快、覆盖范围之广,远超行业同类产品,成为字节跳动“亿级App”产品矩阵中成长最快的明星产品。其发展历程不仅是功能的不断丰富,更是用户认可度、市场影响力的持续攀升。每一步升级都紧扣用户需求,每一次迭代都带来更便捷的使用体验。
图1-2 豆包
豆包的发展最早可追溯到2023年。当年6月,字节跳动在内部测试一款AI对话类产品——Grace;经过两个月的优化打磨,同年8月,Grace新版本正式更名为“豆包”。
1.2.2 硬核底座:豆包的核心技术支撑
字节跳动推出的Doubao-1.5-pro大模型,在多个国际评测基准中跻身世界一流水平,如图1-3所示。
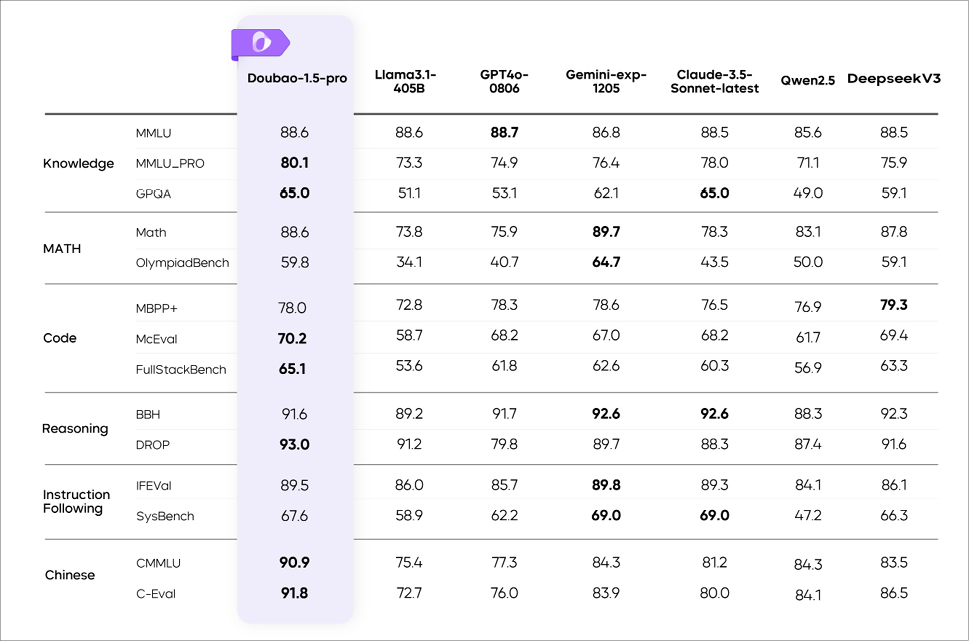
图1-3 Doubao-1.5-pro在多个基准上的测评结果
架构创新是豆包大模型的核心竞争力,Doubao-1.5-pro采用稀疏MoE架构,并从预训练阶段就坚持训练与推理一体化设计,如图1-4所示这是其能够以较低成本实现高性能的关键。
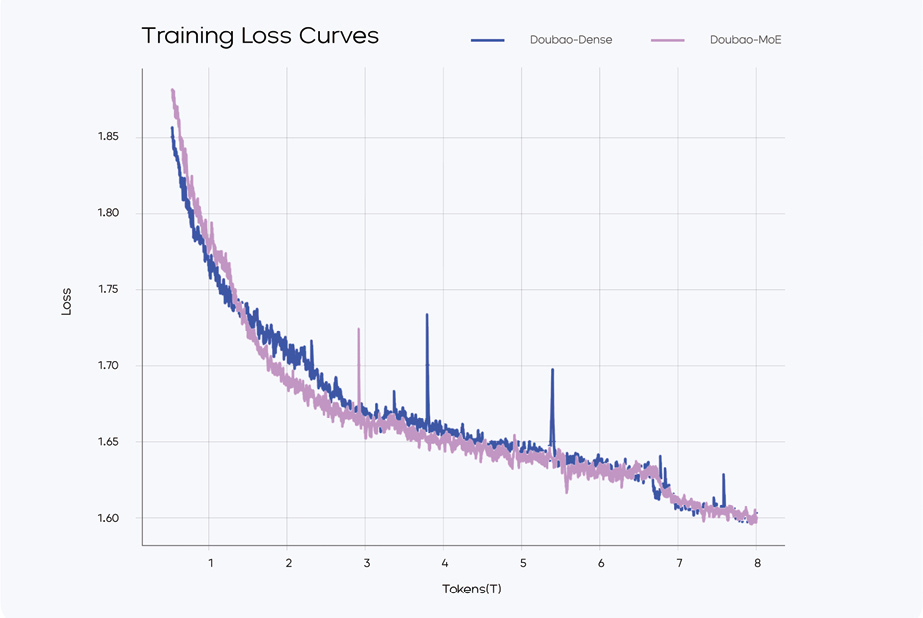
图1-4 训练Loss图
在GPQA、MMLU_PRO等多个核心任务的性能对比中,MoE模型的优势也得到了精准印证,如图1-5所示。此外,研发团队还设计了模型参数动态调整算法,能根据应用需求,从模型深度、专家数量等维度灵活调参。这一设计既能满足高难度任务的需求,也能降低普通任务的推理成本,还提升了模型迭代效率,使技术能更快落地到各类产品中。
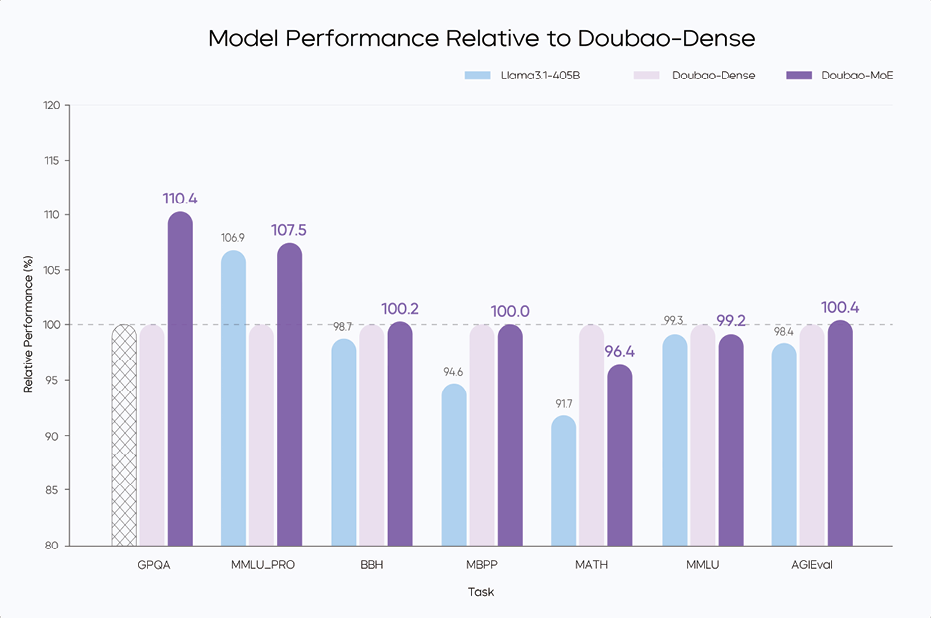
图1-5 Performance对比图
从架构创新到推理优化,从数据训练到多模态融合,再到推理能力的持续突破,Doubao-1.5-pro构建了一套完整的技术支撑体系。这也是豆包能在MMLU、CMMLU、MathVista等多个评测中取得优异成绩的根本原因。这些技术让豆包实现了性能与效率的极致平衡,也为大模型的产业化应用奠定了坚实基础。未来,随着对通用智能研究的不断深入,豆包的技术底座还将持续进化,在探索智能边界的同时,让人工智能更好地服务于普通用户和各行各业,实现技术与应用的双向驱动。
1.2.3 多模态全能
豆包已实现文字、视觉、语音、创意创作等多模态能力的全面覆盖,形成了“能听、会说、善思、巧创”的全能优势。每一项能力都精准适配大学生的学业、社团、生活等场景,帮助用户无需切换多个工具。
文字能力作为豆包的基础核心,早已实现全方位升级。它不仅能完成基础的文本生成与编辑,更能适配大学生的高阶文字需求。例如,豆包可一次性读取大量学术论文和文献资料,快速提炼核心观点、梳理逻辑脉络,帮助大学生节省大量阅读时间。
视觉能力的升级,让豆包实现了“睁眼看世界”,完美适配大学生线下学习与创意创作的需求。豆包能够精准识别任意分辨率、任意长宽比的图像,支持图文结合理解、图片编辑、海报生成等多种功能。
语音能力的突破,让豆包的交互更便捷、更贴近日常。它能够适配大学生行走、休息、双手忙碌等多种场景,听懂20种以上夹杂方言的对话,即使是带有吞音、口音的表达,也能精准识别。
创意创作能力的全面覆盖,使豆包成为大学生社团实践、个人展示的“创意伙伴”,真正实现“一个AI就是一个创作团队”。
1.3 提示词入门:让豆包准确理解需求
提示词的有效性,直接决定了大模型输出的质量上限。很多人认为觉得模型不行,其本质原因不是模型能力不足,而是提问方式过于含糊。
1.3.1 常见无效提示词
第一类:目标缺失型。例如:帮我写一个总结。
这句话没有交代总结的对象、使用场景、输出长度和判断标准。模型只能按照默认顺序生成:先铺陈背景,再泛泛概括,最后简单收尾。如果改为:为部门周会汇报用,先给3条结论,每条不超过40字,再用一段话说明依据。
模型便不再猜测“写到什么程度算完成”,而是围绕明确的交付目标组织内容,输出结果可直接使用。
第二类:任务边界不清型。例如:分析这个问题。
模型无法判断你要的是背景介绍、原因拆解,还是可执行的建议。它通常会选择最稳妥的方式:多角度铺陈,但不下判断、不作取舍。如果改为:从执行层面分析该问题,先给出明确结论,再指出当前最大的阻碍和一个最现实的突破口。
由于判断顺序被明确限定,模型就会压缩背景、强化结论,生成的内容明显更具针对性和实用性。
1.3.2 提示词是一条从目标到结果的逻辑链
很多人在学提示词时会走一个弯路,认为只要写得足够细致、足够长,输出就一定更好。实践恰恰表明:真正决定质量的,是判断顺序是否清晰。
这里有一个关键点:判断顺序不等于输出顺序。不妨看下面这组对比——两者信息量相差无几,但可用性差距很大。
提示词A:写一篇总结,要求语言正式、结构清晰、重点突出结论,并说明背景。
提示词B:先给结论,用不超过3段说明背景与理由,语言正式,最后给一句可复制到PPT的金句。
几乎在任何情况下,提示词B的效果都更好,因为它把顺序固定了下来。很多人抱怨模型喜欢铺垫,其实问题在于你没有规定先结论还是先背景,没有规定段落数量,也没有指定最后需要可复制的交付件。模型不会替你做这些决定。
1.3.3 结构化提示词
结构化提示词的核心价值,在于它为每次撰写提示词提供了一个可复用的逻辑框架。一个最小可复用结构通常包含5个要素:任务目标、使用语境、完成标准、执行方式、交付形式,如表1-1所示。
表1-1 结构化提示词要素
| 要素 |
作用 |
| 任务目标 |
明确最终要完成什么 |
| 使用语境 |
说明给谁用,用在什么场景 |
| 完成标准 |
规定长度、深度、重点与禁区 |
| 执行方式 |
是否分步骤,是否先提问澄清 |
| 交付形式 |
是否可直接复制使用,是否需要表格或清单 |
你可以用一个最直观的例子理解这个框架。同样是写活动方案,非结构化提示词往往是“帮我写一个活动方案”,模型必须猜规模、目的、预算、分工、风险,结果大概率泛泛而谈。
结构化版本只需要把五要素补齐,输出便会变得清晰可控,例如:为学院迎新晚会写活动方案,规模300人,预算3000元,目标是拉新与氛围,输出包含流程表、岗位分工、物资清单、风险预案,语言正式,可直接发到工作群。
1.4 提示词进阶:显著提升豆包输出质量
当你掌握了基础提示词之后,豆包在大多数情况下都能给出“看起来没什么问题”的结果。但同样使用豆包,有些人的输出明显更成熟、更像人写的,而自己的内容却总是差一点。差在哪里?并非信息不够,而是思路不对。
1.4.1 从一次性指令到分阶段协作
许多大学生初次用AI写作业或撰写材料时,往往会不自觉地把“最终成果”当成一个任务丢给模型。例如:帮我写一篇关于人工智能伦理的课程论文;给我做一份完整的社团活动方案;帮我生成一份期末复习计划。
高阶提示词的第一个转变,就是不再要求豆包一次性交付成品,而是让它分阶段参与。
举一个非常贴近大学生的例子:AI辅助写课程论文。初级提示词写法通常是:帮我写一篇关于人工智能伦理的课程论文,3000字。
这种提示词下,豆包往往会写得“像论文”的内容,但使用者自己可能难以说清这篇论文的核心观点究竟是什么。
而高阶写法则会采用以下三步协作策略。
第一步,只让豆包做判断,不写正文:给我3个适合本科课程论文的人工智能伦理研究角度,每个角度用一句话说明中心论点。
第二步,选定一个角度后,再让它搭结构:围绕这个论点,给我一个详细写作提纲,标明每一部分要回答什么问题,不要写正文。
第三步,最后才进入写作阶段:按这个提纲写正文,语言偏学术风格,但避免空话,每一节控制在500字左右。
采用这种方式,最终写出来的内容,并不一定更“华丽”,但论点更清晰、结构更稳固、更容易获得老师的高分评价。原因只有一个:豆包在每一步只需要处理一种判断,而不必同时应对多重复杂决策。
1.4.2 把“思考顺序”写进提示词里
即便你已经学会了分阶段协作,仍然可能遇到一个问题:豆包生成的内容逻辑上没有错,但总是“不按你想要的顺序来”。比如,你明明想要结论先行,它却先铺了两百字背景;你想要一个可执行的方案,它却反复讲原则和意义;你想让它像老师一样讲课,它却像教材一样下定义。
问题出在哪里?不在于信息量,而在于思考顺序没有明确被指定。
高阶提示词的第二个核心技巧,就是把思考路径显性化。
以作业中常见的分析题为例。普通的提示词是:分析大学生使用AI工具的利弊。
豆包通常的回复是“背景+优点+缺点+总结”,看起来内容完整,但更像是在拼接标准答案。如果你稍微改一下提示词,把思考顺序写出来:先给出你的总体判断,再分别从学习效率、思维能力和公平性三个角度给出理由,最后指出一个最值得警惕的问题。
你会发现,输出立刻变得更像是一个人在表达观点,而不是在罗列信息。
再看一个例子。如果你只是说:解释一下什么是机会成本。
豆包大概率会给出一个偏教材式的解释。但如果你这样提问:先用一句话给出定义,再用一个大学生日常生活的例子加以解释,最后给出一个容易混淆的反例。
它就会立刻切换到“像老师讲课”的模式。这里有一个非常重要,但常被忽略的点:你不一定需要让豆包把思考过程写出来,但你一定要把思考顺序写进提示词里。
你甚至可以在提示词里加一句:“请按以上步骤思考,最终只输出整理后的结果。”这样既能保证逻辑质量,又不会让内容显得啰唆。
1.4.3 去掉“AI味”
当你已经能让豆包把事情“做对”之后,接下来几乎所有人都会遇到同一个问题:内容是正确的,但不像人写的。很多人会简单地把这种现象称为“AI味”。要解决这个问题,关键不在于让它“写得更像人”,而在于让它知道:现在是“谁”在写,以及“以什么方式”在写。也就是说,你需要开始使用人设和风格约束。
举一个常见的作业场景为例。如果你的提示词是:谈谈你对大学生使用AI工具的看法。
豆包往往会写出一篇“正确但安全”的小论文,优缺点兼顾,语气温和,很难挑出错处,但也很难出彩。
如果你在提示词中加入人设和表达立场:你是一名已经使用AI工具两年的理工科高年级学生,请结合真实学习经历,谈谈你对大学生使用AI工具的看法,语气偏经验总结,允许有明确判断。
输出立刻会发生改变。它不再急于追求“面面俱到”,而是开始像一个人那样进行取舍:哪些是真的有用,哪些其实被夸大了,哪些风险在现实中更常见。
再举一个写总结的例子。普通的提示词是:总结这次课程的学习收获。
加入人设和风格后,可以这样写:你是一名准备期末考试的学生,请用偏复盘式的语气,总结这门课最重要的三点收获,每一点都说明“如果不懂会有什么后果”。
这种提示词的本质,并非在“限制模型”,而是在替模型完成它最难做的那一步判断:我现在应该站在什么位置说话,用什么语气,说到什么程度。这些看似细微的限制,恰恰是“去掉AI味”的关键。因为人类写作本身就是不完全规则化的,而默认状态下的模型,反而显得过于规整了。
1.5 如何降低AI幻觉
在真正将豆包应用于学习和工作之后,几乎每个人都会遇到类似的问题:你让它解释一个概念,它讲得头头是道;你让它列举政策、案例、数据,它也能迅速给出答案。但当你稍微查一查,就会发现:有的内容根本不存在,有的案例被拼接过,有的数据来源模糊不清。
这种现象,通常被统称为AI幻觉。
1.5.1 联网检索,把猜测变成参考
在降低AI幻觉的所有方法中,最直接、最有效的一种,就是让豆包在回答前,先接触真实世界的信息。你可以这样理解:不是给它一个封闭考场,而是允许它“翻书”。
如果你直接提问:给我列举3篇关于人工智能伦理的经典论文。
在未联网的情况下,豆包很可能会给出3条看起来非常“像论文”的条目,但其中可能存在作者错配、期刊不存在、年份不准确的问题。
如果你换一种问法,并明确要求联网:请联网检索,列举3篇真实存在的人工智能伦理相关论文,并给出作者、年份和期刊来源。
输出的可靠性会显著提高。因为此时模型不再需要完全依靠语言概率来“想象”论文,而是以外部信息为锚点。
但这里有一个非常重要的使用原则:联网检索不是万能的,它只是降低幻觉发生的概率,而不是自动保证结果的正确。
所以,更稳妥的做法是:明确告诉豆包你需要的是事实信息,而不是分析结论;要求它区分“引用信息”和“模型总结”;对关键信息提出可核查的输出要求,例如标注来源、时间、出处。
例如:请联网检索,并在每一条信息后标注来源网站或机构名称。
这种要求,会显著抑制模型“编得很顺”的冲动。
1.5.2 上传附件,给AI一个确定的事实边界
上传附件是降低AI幻觉最容易被低估、但效果极其显著的方法之一。以一个再真实不过的场景为例:你让豆包总结一篇你正在读的论文。如果你只是简单地说:总结一篇关于某主题的论文。
它只能依靠泛化的经验来总结,内容看似合理,但很可能与你手中那篇论文并不相符。
如果你上传了论文的PDF文件,并明确指示:请只基于我上传的这篇论文进行总结,不要引入外部信息。
模型的AI幻觉空间就会被大幅压缩。因为此时模型不需要“猜作者想说什么”,而只需要“从已给材料中提取信息”。
这里有一个非常实用的技巧:在使用附件时,明确写出“允许”和“不允许”的事项。
例如,允许总结、重组、改写;不允许添加未在原文中出现的观点,不允许自行扩展背景知识。这种清晰的边界声明,会显著改变模型的生成策略。
1.6 智能体,你的第二大脑
先说大模型。大模型可以理解为一个能力极强的“语言大脑”。它通过大量数据学习语言规律,擅长理解问题、组织文字、进行推理。你问它一道题、让它写一段话、解释一个概念,它都能迅速给出答案。大模型能力强大,但其运作完全依赖当下这一次指令。
智能体并不是一个新模型,而是一个“被提前设定好角色和任务的系统”。在真正开始使用之前,你已经告诉它:你希望它长期干什么事、面对什么人、遵循什么规则、输出要满足哪些标准。
可以把两者类比成现实中的两种帮手。大模型就像一个你随时咨询的“全能路人专家”;智能体更像一个长期配合你的助理。你每次问路人专家,都要从头说明背景;而助理早就知道你的习惯、目标和标准,你只要一句简短指令,他就知道该怎么做。
再举一个生活化的例子。如果你走进一家打印店,只说:“帮我打印一份材料。”店员只能猜:彩色还是黑白?单面还是双面?打印多少页?结果往往“能用”,但未必是你最想要的。但如果你是老顾客,早已明确规则:学习资料用A4纸,黑白双面打印。以后你只需要说一句:“按老规矩来。”事情就会自动指向正确的结果。
智能体,本质上做的就是这样一件事:把你脑子里那些反复出现的判断,提前设定为默认规则。当你只是偶尔使用AI时,大模型已经足够;当你发现自己反复处理同一类任务、反复解释同样的要求时,其实就已经走到了需要智能体的阶段。所以,智能体并不神秘,也不遥远。它只是让AI从一次次的临时应答,变成了一个长期可靠的执行者。







