版权信息 书名:大语言模型工程师手册 从概念到生产实践
ISBN:978-7-115-66737-3
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
版 权 著 [罗]保罗·尤斯廷(Paul Iusztin)
[英]马克西姆·拉博纳(Maxime Labonne)
译 孟凡杰 方佳瑞
责任编辑 贾 静
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线: (010)81055410
反盗版热线: (010)81055315
内容提要 AI技术已取得飞速发展,而大语言模型(LLM)正在引领这场技术革命。本书基于MLOps最佳实践,提供了在实际场景中设计、训练和部署LLM的原理与实践内容。本书将指导读者构建一个兼具成本效益、可扩展且模块化的LLM Twin系统,突破传统Jupyter Notebook演示的局限,着重讲解如何构建生产级的端到端LLM系统。
本书涵盖数据工程、有监督微调和部署的相关知识,通过手把手地带领读者构建LLM Twin项目,帮助读者将MLOps的原则和组件应用于实际项目。同时,本书还涉及推理优化、偏好对齐和实时数据处理等进阶内容,是那些希望在项目中应用LLM的读者的重要学习资源。
阅读本书,读者将熟练掌握如何部署强大的LLM——既能解决实际问题,又能具备低延迟和高可用的推理能力。无论是AI领域的新手还是经验丰富的从业者,本书提供的深入的理论知识和实用的技巧,都将加深读者对LLM的理解,并提升读者在真实场景中应用它们的能力。
推荐序1 正如Hugging Face联合创始人Clement Delangue常和我说的,AI正逐渐成为技术开发的标准方式。
过去3年间,LLM在技术领域已产生深远影响。展望未来5年,其影响力必将进一步扩大。我相信,这项技术不仅会融入越来越多的产品,更有望成为所有依赖知识和创造力的人类活动的核心驱动力。
例如,程序员已经开始利用LLM并改变他们的工作方式,他们与机器协作,将精力集中在更高层次的思考和任务上;录音室音乐人借助AI工具,加速了音乐创意的探索;律师则通过检索增强生成( retrieval-augmented generation , RAG )技术 和庞大的案例法数据库,提升自身的工作效率和影响力。
在Hugging Face,我们一直致力于推动一个更加开放的AI未来——打破由一家公司和少数科学家垄断AI模型的现状,让来自不同背景的、尽可能多的人能够深入理解并参与尖端机器学习模型的研究与应用。
保罗和马克西姆通过编写这本书,为LLM的普及和推广作出了重要贡献。他们致力于让更多人不仅能使用这些模型,还能对其进行定制、微调和量化,最终将其高效地应用于实际场景。
他们的工作意义重大,我很高兴他们能编写本书。这无疑拓展了人类知识的边界。
Julien Chaumond
Hugging Face联合创始人,首席技术官
推荐序2 作为一名深耕机器学习运维(machine learning operations,MLOps)领域的从业者,我由衷地推荐本书。在各行各业对LLM专业知识的需求呈暴发式增长的关键时刻,本书的出版可谓恰逢其时。
本书的独特之处在于其实践导向的端到端方法。通过带领读者从零构建LLM Twin项目,它巧妙地弥合了理论与实际应用间常常令人望而生畏的鸿沟。从数据工程和模型微调,到RAG流水线和推理优化,作者们不遗余力地进行了介绍。
本书对MLOps和LLMOps原则的深入阐述,让我印象深刻。随着各组织机构越来越依赖LLM,理解如何构建可扩展、可复现且稳健的系统变得至关重要。本书还包括编排策略和云集成的相关内容,这充分体现了作者致力于为读者提供真正可用于生产环境的技能的初心。
无论是希望专攻LLM的资深机器学习研究者,还是致力于突破这一前沿领域的软件工程师,都可以通过本书获得LLM相关的基础理论与前沿技术。通过清晰的阐释、实用的案例和对行业最佳实践的深入剖析,本书必将成为想要精通LLM工程的人的宝贵学习资源。
在AI以惊人速度重塑各个行业的时代,本书应运而生,为读者提供了一份应对LLM复杂性的权威指南。这不仅是一本普通的技术专著,更是在AI驱动的新兴领域中成为卓越工程师的路线图。
Hamza Tahir
ZenML联合创始人,首席技术官
推荐序3 本书是一本面向实践的宝贵指南,为希望深入了解LLM的读者提供了全面的知识。通过翔实的实例和对LLM Twin项目的深入剖析,本书巧妙地揭示了构建和部署企业级LLM应用的核心技术和复杂挑战。
本书的一个突出特点是以LLM Twin项目作为贯穿全书的案例。这个专门模仿特定人物写作风格的AI角色,生动地展示了如何将LLM应用在实际场景中。
作者精心梳理LLM开发的关键工具与技术,包括Hugging Face、ZenML、Comet、Opik、MongoDB和Qdrant等。通过对每个工具的详细阐述,帮助读者快速理解每个工具的功能特点及其在LLM流水线中的应用。
本书涵盖了LLM开发的诸多关键领域,包括数据采集、模型微调、性能评估、推理优化和MLOps等。值得注意的是,关于监督微调(supervised fine-tuning,SFT)、偏好对齐及RAG的章节,尤其深入剖析了LLM开发的核心技术。
本书的一大亮点在于注重实践应用。作者不仅给出了具体案例,还详细介绍了如何优化推理流程并有效部署LLM,使本书成为研究人员和工程师的宝贵参考资料。
对于渴望深入了解LLM及其实际应用的读者,我强烈推荐本书。作者全面阐述了LLM开发的工具、技术和最佳实践,为LLM工程师提供了一份极具价值的参考资料。
Antonio Gulli
谷歌高级总监
关于技术审稿人 Rany ElHousieny是一名解决方案架构师和工程管理者,在AI、NLP和机器学习领域拥有超20年的经验。在职业生涯中,他致力于推动AI模型的创新发展,并撰写了多篇AI系统架构和AI伦理相关的专业文章。在微软任职期间,他主导了自然语言处理领域的突破性项目,尤其在语言理解智能服务(language understanding intelligent service,LUIS)方面作出了卓越贡献。目前,他在Clearwater Analytics担任重要职位,专注于推动生成式AI在金融和投资管理领域的应用。
衷心感谢Clearwater Analytics,为我提供了一个充满支持、鼓励学习、促进成长和创新的工作环境。公司领导者的前瞻性视野和对新技术的敏锐洞察,始终是激励我前进的动力。他们对AI技术发展的坚定承诺,让我在审阅这本书的过程中收获颇丰、获益良多。同时,我要特别感谢我的家人,感谢他们在整个旅程中给予的无尽鼓励和支持。
——Rany ElHousieny
前 言 LLM 工程正迅速成为AI与机器学习的关键领域。LLM推动自然语言处理与生成技术不断革新,这使得市场对能够在实际场景中实现、优化和部署LLM的专业人才的需求呈指数级增长。LLM工程涉及多个专业领域,从数据准备、模型微调,到推理优化、生产环境部署等,这要求工程师们既要具备软件开发能力,还要精通机器学习并掌握相关的领域知识。
在LLM的生产环境部署中,MLOps 扮演着关键角色。MLOps将DevOps的原则扩展到机器学习项目中,目标是实现整个机器学习生命周期的自动化和精简化。由于LLM本身具有较高的复杂性和较大的规模,MLOps在其中显得尤为重要,它能够有效应对多个挑战,例如大型数据集的管理、模型版本的控制、结果的可复现性,以及模型性能的长期维护等。通过引入MLOps实践,LLM项目能够在效率、可靠性和扩展性等方面获得显著提升,从而实现更为成功和更具影响力的部署。
本书是一本面向LLM工程的实践指南,介绍了该领域的诸多最佳实践。本书围绕LLM生命周期的不同阶段,为读者提供了简明的核心概念、实用的技术方法和专家的建议指导。书中详细讲解了多个重要主题,包括数据工程、监督微调、模型评估、推理优化,以及RAG 流水线开发等。
为了讲解这些主题,本书将开发一个端到端项目LLM Twin——一个能够模仿特定人物写作风格和个性特征的系统。通过这个实例,读者可以学习如何运用LLM工程和MLOps的各项技术,从零开始构建一个能解决特定问题的最小可行产品(minimum viable product,MVP)。
通过本书,读者将深入理解LLM应用开发的全过程,包括数据采集与准备、特定任务的模型微调、推理性能优化和RAG流水线的具体实现。同时,读者还可以学习如何评估模型性能、实现模型与人类偏好的对齐,以及部署基于LLM的应用。本书还系统介绍了MLOps的基本原则和实践方法,帮助读者掌握如何构建可扩展、可复现且稳健的LLM应用。
适读人群 本书适合所有技术人员和对LLM实际应用感兴趣的人士阅读,特别适合那些想要投身AI项目开发的软件工程师。尽管有软件开发基础会更容易理解书中内容,但本书包含了许多基础概念的讲解,这使得AI和机器学习领域的入门者也能轻松阅读。
对于已经从事机器学习工作的读者,本书有助于提升开发和部署基于LLM的应用的专业技能。本书会深入讲解MLOps的基础知识,指导读者如何使用开源LLM一步步构建出能够解决实际问题的MVP。
本书内容 第 1 章:理解LLM Twin的概念与架构,介绍贯穿全书的项目LLM Twin——一个端到端的生产级LLM应用示例,定义用于构建可扩展的机器学习系统的特征、训练、推理(feature/ training/inference,FTI)流水线,并展示如何将其应用于LLM Twin项目。
第 2 章:工具与安装,介绍开发LLM应用所需的各类工具,包括Python工具、MLOps工具和云端工具,如编排工具、实验追踪系统、提示监控工具和LLM评估工具等。本章将详细说明如何在本地环境中安装和使用这些工具,以支持测试和开发工作。
第 3 章:数据工程,介绍数据采集流水线的实现,这个流水线从Medium、GitHub和Substack等多个网站抓取数据,并将原始数据存储在数据仓库中。本章特别强调,对于实际的机器学习应用而言,从动态数据源获取原始数据比使用静态数据集更为有效。
第 4 章:RAG特征流水线,介绍RAG的基本概念,包括嵌入、基础RAG框架、向量数据库,以及RAG应用的优化方法。本章将运用软件开发最佳实践,设计并实现LLM Twin的RAG特征流水线,展示RAG理论的实际应用。
第 5 章:监督微调,详细阐述如何通过指令-答案对为特定任务精细调整预训练语言模型。本章将重点介绍高质量数据集的构建、微调技术(如全量微调、LoRA和QLoRA等)的实现,并提供在自定义数据集上微调Llama 3 8B模型的实践案例。
第 6 章:偏好对齐微调,介绍将语言模型与人类偏好对齐的技术,并重点介绍直接偏好优化( direct preference optimization , DPO ) 技术,包括定制偏好数据集的构建、DPO技术的实现,以及通过Unsloth库与TwinLlama-3.1-8B模型进行对齐的实践案例。
第 7 章:LLM的评估方法,详细介绍评估语言模型和LLM性能的各种方法,介绍通用和特定领域的LLM评估,并讨论主流的基准测试。本章包括使用多个标准对TwinLlama-3.1-8B模型进行评估的实践案例。
第 8 章:模型推理性能优化,介绍投机解码、模型并行化和模型量化等关键优化策略,详细阐述如何在保证模型性能的同时,显著提高推理速度、降低系统延迟及优化内存使用,并介绍主流的推理引擎及其特性。
第 9 章:RAG推理流水线,探索了高级RAG技术,从零实现自查询、过滤向量搜索和重排序等方法。本章涵盖RAG推理流水线的设计与实现,以及构建类似LangChain等主流框架的自定义检索模块。
第 10 章:推理流水线部署,介绍机器学习部署策略,如在线实时推理、异步推理和离线批量转换,这将有助于构建LLM Twin的微调模型并将其部署到AWS SageMaker,同时构建一个FastAPI微服务以便将RAG推理流水线作为REST API进行暴露。
第 11 章:MLOps和LLMOps,介绍LLMOps的概念,追溯其在DevOps和MLOps中的发展历程。本章将介绍LLM Twin项目的云端部署实践,例如将机器学习流水线迁移至AWS,并介绍如何使用Docker进行代码容器化,以及构建持续集成、持续交付和持续测试(continuous integration/ continuous delivery/continuous training,CI/CD/CT)流水线。同时,本章还在LLM Twin的推理流水线顶层增加了提示监控机制。
附录:MLOps原则,阐述了构建可扩展、可复现和稳健的机器学习应用的6大关键原则。
充分利用本书 为了获得更好的学习效果,读者应该对软件开发的原则和实践有基本了解。本书的示例和代码主要使用Python,因此熟悉Python编程将特别有帮助。虽然事先了解机器学习概念会有优势,但这并非必需,因为本书将介绍AI和机器学习的许多基本概念。不过,建议读者能够熟悉基本数据结构、算法,并具备一定的API和云服务使用经验。
本书相关代码示例托管在GitHub仓库上,因此假定读者已经熟悉Git等版本控制系统。尽管本书面向AI和LLM的新手,但对于具有相关背景的读者而言,理解书中的高级概念和技术会更加轻松。
下载示例代码文件 本书的所有源代码均可从本书的GitHub仓库和出版社网站下载。本书配套GitHub仓库的目录简介如下。
llm_engineering/:实现LLM和RAG功能的主要Python包。文件夹内容如下。
• domain/:核心业务实体和结构。
• application/:业务逻辑、爬虫和RAG实现。
• model/:LLM 训练和推理。
• infrastructure/:外部服务集成(AWS、Qdrant、MongoDB、FastAPI)。
代码逻辑和导入流向为:infrastructure → model → application → domain。
pipelines/:包含 ZenML 机器学习流水线,作为所有机器学习流水线的入口,负责协调机器学习生命周期中的数据处理和模型训练阶段。
steps/:包含独立的ZenML步骤,这些步骤是构建和自定义ZenML流水线的可复用组件。每个步骤执行特定任务(如数据加载、预处理),可以在机器学习流水线中组合使用。
tests/:包含CI流水线示例的测试用例。
tools/:用于调用ZenML流水线和推理代码的实用工具脚本。文件夹内容如下。
• run.py:运行ZenML流水线的入口脚本。
• ml_service.py:启动REST API推理服务器。
• rag.py:演示 RAG模块的使用方法。
• data_warehouse.py:通过JSON文件导入、导出MongoDB数据仓库数据。
configs/:控制流水线和步骤执行的ZenML YAML配置文件。
code_snippets/:可独立执行的代码示例。
下载图片 本书中所有图片可在异步社区本书对应的网页中找到。
下载拓展阅读资料清单 本书中每章均提供了拓展阅读资料清单,读者可在异步社区本书对应的网页中找到。
排版约定 本书采用了多种文本排版约定。
(1)行内代码(CodeInText):用于标记文本中的代码、数据库表名、文件夹名、文件名、文件扩展名、路径名、示例URL、用户输入和X用户名。例如,在format_samples()函数中,为每条消息应用Alpaca聊天模板。
(2)代码块的样式如下:
def format_samples(example):
example["prompt"] = alpaca_template.format(example["prompt"])
example["chosen"] = example['chosen'] + EOS_TOKEN
example["rejected"] = example['rejected'] + EOS_TOKEN
return {"prompt": example["prompt"], "chosen": example["chosen"],
"rejected": example["rejected"]} 为了突出代码块中的关键部分,将相关行或元素以粗体突出显示:
def format_samples(example):
example["prompt"] = alpaca_template.format(example["prompt"])
example["chosen"] = example['chosen'] + EOS_TOKEN
example["rejected"] = example['rejected'] + EOS_TOKEN
return {"prompt": example["prompt"], "chosen": example["chosen"],
"rejected": example["rejected"]} (3)命令行的输入或输出将按以下格式显示:
poetry install --without aws (4)粗体(Bold ):用于标注新术语、重要词汇或截屏图片上的关键字。例如,菜单或对话框中的文字会以粗体形式呈现。举例说明:要完成此操作,请在GitHub中进入已复刻仓库顶部的Setting 选项卡,之后在左侧面板的Security 区域,点击Secrets and Variables 开关,最后点击Actions 按钮。
(5)警告或重要说明。
警告或重要说明将以此种形式呈现。
第1章 理解LLM Twin的概念与架构 我们深信,学习LLM和生产级机器学习应用的最佳方式之一是上手实践并搭建一个系统。因此,本书将展示如何构建LLM Twin——一个通过学习和融入特定人物的写作风格、语气和个性进而模仿他写作的AI智能体。通过这个具体案例,读者可以体验机器学习应用的完整生命周期,从数据采集、模型训练,到系统部署和性能监控。在实现LLM Twin的过程中涉及的大部分概念和技术都可以应用到其他基于LLM或机器学习的项目中。
从工程视角看,在开始构建一个新产品前必须经历3个关键的规划阶段。首先,理解要解决的问题和要构建的内容至关重要。于本书而言,LLM Twin究竟是什么,为什么要构建它,是需要发散思考并聚焦“为什么”的关键阶段。其次,为了贴近实际应用场景,我们将设计一个功能最小但可用的产品原型。在这个阶段,必须明确定义能够正常工作且有价值的产品所需的核心功能。这些选择将基于项目时间线、可用资源和团队能力来权衡。通过这个过程,我们将理想与现实对接,最终回答一个核心问题:要构建的系统究竟“是什么”?最后,进入系统设计阶段,列出用于LLM系统的核心架构和关键设计决策。需要说明的是,前两个阶段主要聚焦于产品层面,而最后一个阶段则深入技术细节,聚焦于“如何做”。
在构建现实世界的产品时,这3个阶段是自然而然进行的。尽管前两个阶段不需要太多的机器学习知识,但对于理解“如何”以一个清晰的愿景来构建产品至关重要。简单来说,本章将探讨以下主题:
• 理解LLM Twin的概念;
• 规划LLM Twin的MVP;
• 构建包含特征工程、训练和推理流水线的机器学习系统;
• 设计LLM Twin的系统架构。
1.1 理解LLM Twin的概念LLM Twin是一个全新的概念,在深入技术细节前需要先把握其本质:它是什么、对它有何期望,以及它应该如何运作。对最终目标有清晰的认知,将帮助读者更轻松地吸收本书中的理论、代码和技术架构。
1.1.1 什么是LLM Twin 简单来说,LLM Twin是一个将独特的写作风格、语气和个性“映射”到复杂AI模型的数字孪生体。与传统的通用语言模型不同,LLM Twin是基于个人数据进行微调的。正如机器学习模型天然会反映其训练数据的特征,这个LLM将呈现你自己的写作风格、语气和个性。之所以用“映射”,是因为这个过程与其他映射类似,难免会丢失很多信息。换句话说,这个LLM并不等同于真实的你,而是仅仅复制了你在训练数据中反应的某些侧面。
LLM会反映其训练数据的特征,理解这一点非常关键。如果用莎士比亚的作品作为训练数据,得到的LLM就会模仿莎士比亚的写作风格;如果用比莉·艾利什(Billie Eilish)的作品作为训练数据,得到的LLM就会以她的风格创作歌曲。这种现象被称为风格迁移,在图像生成领域同样广泛存在,例如生成一幅具有梵高风格的猫的图像。与其选择某个特定人物的风格,不如尝试为模型赋予你自己的个人风格。
为了使LLM更好地匹配特定的风格和语气,我们将结合微调和多种先进的RAG 技术,通过引入个人语言特征嵌入来优化自回归生成过程。第5章将深入探讨微调,第4和第9章将展开RAG的具体细节。
以下是几个通过微调LLM来打造专属的LLM Twin的场景。
• LinkedIn 动态和 X 平台的帖子 :让LLM擅长创作社交媒体内容。
• 与朋友和家人的对话 :让LLM呈现最真实、不加修饰的你。
• 学术论文和专业文章 :调教LLM撰写严谨、专业的学术内容。
• 写代码 :让LLM按照你的编程风格和习惯写代码。
这些场景本质上都遵循一个核心策略:收集你的数字数据(或其中的某部分),并通过不同算法将其输入LLM。最终,这些模型会呈现所收集数据的语气和风格。很容易,是不是?
不幸的是,这在技术和道德层面面临诸多挑战。第一,从技术层面看,首先要解决数据获取的问题:如何收集和整合能够充分代表个人特征的数字信息?究竟拥有多少有价值的个人数据,能否真正将自我“映射”到LLM中?第二,从道德层面看,这种做法更是引发深刻的伦理思考:是否真的应该创造一个“数字化的自己”?这个“复制品”是否能准确地传达我们的独特语言风格和个性,还是沦为一种肤浅的模仿?
请记住,本节的重点不在于探讨“是什么”和“如何做”,而是深入思考“为什么”。我们将探讨为何构建LLM Twin具有意义,它为什么有价值,以及在正确的问题框架下这种做法为什么是合理的。
1.1.2 为什么构建LLM Twin 对于工程师(或其他专业人士)而言,建立个人品牌已经远比传统简历更为重要。然而,在社交媒体平台(如LinkedIn、X或Medium等)写作需要花很多时间,这是建立个人品牌最大的挑战之一。即便热爱写作和创作内容,多数人最终也会因缺乏时间和灵感枯竭而需要一个创作助手。
我们想要构建一个LLM Twin,希望它能按照我们的个人风格,在LinkedIn、X、Instagram、Substack和Medium等平台上创作内容。它不会被用于任何不道德的场景,而只是作为我们的写作搭档。虽然你可以基于所学将LLM Twin创造性地应用到不同场景,但本书将聚焦于社交媒体内容和文章的生成。因此,我们无须从头开始写作内容,只需提供核心思路就能让LLM Twin来完成繁重的写作工作。
最终,我们需要检查LLM Twin生成内容的准确性,并按需进行格式调整(具体功能特性将在1.2节详细介绍)。为此,我们将把自己“映射”为一个专注于内容创作的LLM Twin,来实现写作流程的自动化。如果尝试在其他场景使用这个特制的LLM可能难以奏效,因为它是通过微调、提示工程和RAG技术定制的。
那么,为什么构建LLM Twin如此重要?它可以实现以下目标:
• 打造个人品牌;
• 实现写作流程自动化;
• 激发创新灵感。
Co-pilot 与 LLM Twin 有何不同?
Co-pilot和LLM Twin是两个不同的概念,它们能够协同工作,组合成一套强大的解决方案。
• Co-pilot是一个AI助手或工具,能在各种编程、写作和内容创作任务中提高用户的能力。
• Twin则使用AI来连接物理世界和数字世界,是现实世界中某个实体的1∶1数字化呈现。例如,LLM Twin就是一个学习模仿我们的声音、个性和写作风格的LLM。
根据上述定义,一个能模仿我们的风格进行写作和内容创作的AI助手,就是我们的LLM数字孪生体。
理解这一点至关重要:构建一个LLM数字孪生体完全符合道德规范。它仅会基于我们的个人数字数据进行微调,而不会收集和使用他人的数据来试图冒充他人的身份。我们的目标很明确:打造一个个性化的写作模仿者。每个人都可以拥有一个访问权限受限的LLM数字孪生体。
当然,这里涉及的诸多安全问题不会在此深入讨论,因为这个话题本身就足以成书。
1.1.3 为什么不使用ChatGPT(或其他类似的聊天机器人)
本节将讨论使用ChatGPT(或其他类似聊天机器人)来生成个性化内容的情况。
ChatGPT无法根据用户的写作风格和语气进行个性化调整,它非常通用,但可能存在表达模糊且较长的问题。在打造个人品牌的过程中,保持独特的个人风格是实现长期成功的关键。因此,直接使用ChatGPT或Gemini难以获得理想效果。即便用户不在意内容缺乏个性化,盲目使用ChatGPT也可能会带来以下问题。
• 幻觉引发的误导信息 :人工检查模型生成的内容或使用第三方工具评估生成结果,是一个既烦琐又低效的过程。
• 烦琐的手动提示编写 :用户必须手动设计提示并嵌入外部信息,这个过程非常枯燥。而且因为用户无法完全控制提示和嵌入数据,每次会话生成答案的一致性难以保持。尽管可以通过API和LangChain等工具部分解决这一问题,但需要一定的编程经验。
根据经验,如果想获得真正有价值的高质量内容,修改AI生成的文本花费的时间会比自己直接写这些文本需要的时间更多。
LLM Twin的关键在于以下几点:
• 收集数据的范围是什么;
• 如何对数据进行预处理;
• 如何将数据输入LLM;
• 如何将多轮提示组成一个提示链;
• 如何评估生成内容。
LLM本身很重要,但需要强调的是,通过ChatGPT的界面来管理和导入各类数据源及评估输出结果,可能每次都要手动地重复一些操作。解决方案是构建一个能够封装和自动化以下所有步骤的LLM系统:
• 数据采集;
• 数据预处理;
• 数据存储、版本管理与检索;
• LLM微调;
• RAG;
• 生成内容质量评估。
请注意,我们并非不推荐使用OpenAI的GPT API,只是要表达本书介绍的框架可以适配各类LLM。任何支持程序化调用且具备微调接口的模型,都可以整合进本书将要构建的LLM Twin系统中。大多数机器学习产品成功的关键在于以数据为中心和模型无关的架构。这样就可以基于特定数据快速尝试多个模型。
1.2 规划LLM Twin的MVP在了解了LLM Twin的概念及构建目的后,必须明确定义它的功能特性。本书将重点关注产品的第一个迭代版本,即MVP ,这也符合大多数产品的自然发展规律。我们的主要目标是基于可用资源,将产品理念与切实可行的业务目标结合起来。即便作为一名工程师,随着职责边界的扩大,也必须学会通过这些步骤来弥合业务需求与技术实现之间的差距。
1.2.1 什么是MVP MVP是指一个产品的初始版本,仅包含足够的核心功能来吸引早期用户,并在开发初期测试产品概念的可行性。通常情况下,MVP的主要目标是以最小的成本获得市场洞察。
MVP之所以成为一种行之有效的策略,主要基于以下几点原因。
• 缩短上市周期 :快速推出产品以获得市场先机。
• 验证创意 :在全面开发产品前,通过真实用户进行测试。
• 市场洞察 :深入了解目标用户群的需求偏好。
• 降低风险 :减少在可能无法获得市场成功的产品上投入的时间和资源。
坚持MVP中的“V(可行性)”至关重要,这意味着产品必须切实可用,即便是最小化的产品,也必须提供完整的端到端用户体验,不能出现半成品或残缺功能的情况。它必须是一个具有良好的用户体验、能正常运作的产品,让人们喜爱并愿意持续使用,关注如何充分发挥其潜力。
1.2.2 定义LLM Twin的MVP 想象一下,不是为了本书而开发LLM Twin项目,而是要开发一个真实的产品,在这种情况下,我们有什么资源呢?很遗憾,只有如下并不多的资源。
• 一个由两名机器学习工程师和一名机器学习研究员组成的3人团队;
• 笔记本电脑;
• 用于计算(如训练LLM)的个人资金;
• 热情。
可见,我们的资源十分有限。虽然这只是一个思想实验,但它确实反映了大多数创业公司起步阶段的真实处境。因此,在设计LLM Twin的MVP时,必须做到:使投入的资源和努力获得最大化的产品价值。
为了保持简单,将为LLM Twin实现以下功能特性。
• 收集你在LinkedIn、Medium、Substack和GitHub上的个人信息。
• 利用收集的数据对开源LLM进行微调。
• 使用个人数据构建向量数据库以支持RAG。
• 基于以下内容创作LinkedIn帖子:
✓ 用户输入的提示;
✓ 用于复用和引用旧内容的RAG技术;
✓ 作为LLM额外知识的新帖子、文章或论文。
• 搭建简单的Web界面与LLM Twin交互,并执行以下操作:
✓ 配置社交媒体链接并启动数据采集;
✓ 发送提示或外部资源链接。
这就是LLM Twin的MVP。尽管它的功能特性不算多,但请记住必须保证这个系统具备成本效益、可扩展性和模块化特性。
即使仅关注本节定义的LLM Twin的核心特性,在构建产品时也会考虑LLM的最新研究成果及软件工程和MLOps的最佳实践,因为我们的目标是展示如何构建一个经济高效且可扩展的LLM应用。
到目前为止,我们已从用户和业务视角审视了LLM Twin,下一步将从工程视角对其进行研究,并制定开发计划以了解技术实现方案。从此刻开始,本书将聚焦于LLM Twin的实现。
1.3 基于特征、训练和推理流水线构建机器学习系统在深入探讨LLM Twin架构的细节之前,需要了解其核心的一种机器学习系统模式——FTI 架构。本节将概述FTI流水线的设计原理,以及如何构建一个机器学习应用。
1.3.1 构建生产级机器学习系统的挑战 构建生产级机器学习系统远不止训练模型那么简单。从工程角度看,在大多数案例中,模型训练是最直接的步骤。然而,当需要确定正确的架构和超参数时,模型训练会变得复杂,这是一个研究问题而非工程问题。虽然训练出高精度的模型极其重要,但要实现稳健的生产部署,仅在静态数据集上进行训练远远不足,还必须考虑以下几个方面:
• 数据注入、清洗与验证;
• 训练与推理环境配置;
• 在合适环境中计算和生成特征;
• 经济高效地部署模型;
• 数据集和模型的版本管理、追踪与共享;
• 基础设施和模型监控;
• 在可扩展的基础设施上部署模型;
• 实现部署和训练流程自动化。
这些是机器学习或MLOps工程师必须考虑的问题,而研究团队或数据科学团队通常负责模型训练。
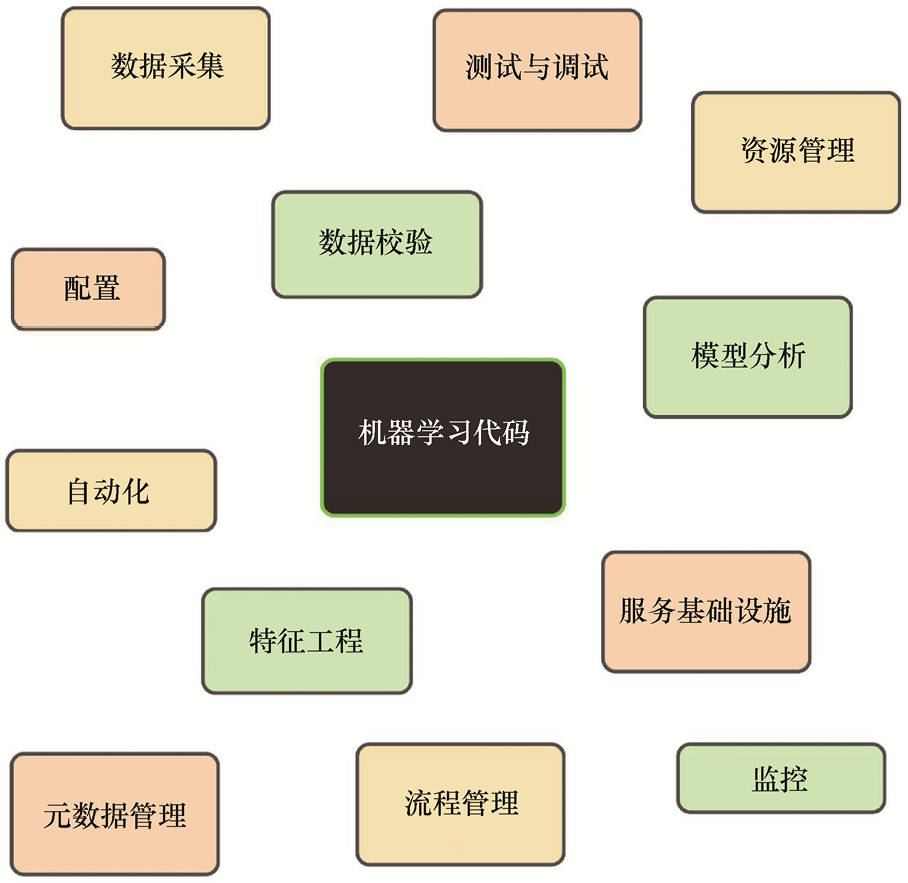
图1.1展示了谷歌云团队建议的成熟机器学习和MLOps系统所需的所有组件。除了机器学习代码,系统还包含多个协同运作的部分,如配置、自动化、数据采集、数据验证、测试与调试、资源管理、模型分析、流程管理、元数据管理、特征工程、服务基础设施和监控。这说明在将机器学习模型投入生产时,必须统筹考虑和设计众多相互关联的组件。
图1.1 机器学习系统的通用组件
因此,最关键的问题是:如何将这些组件连接成一个单一同构的系统?为了解答这个问题,需要创建一个标准化的机器学习系统设计框架。
传统软件也存在类似的解决方案。从宏观视角看,大多数软件应用都可以划分为数据库层、业务逻辑层和用户交互层。虽然每一层都可能根据需求不同而变得很复杂,但从整体架构来看,标准软件的框架本质上可以提炼为这3个基本层级。
对于机器学习应用,是否也存在类似的方法?下面先检查已有的解决方案,并分析为什么它们不适合构建可扩展的机器学习系统。
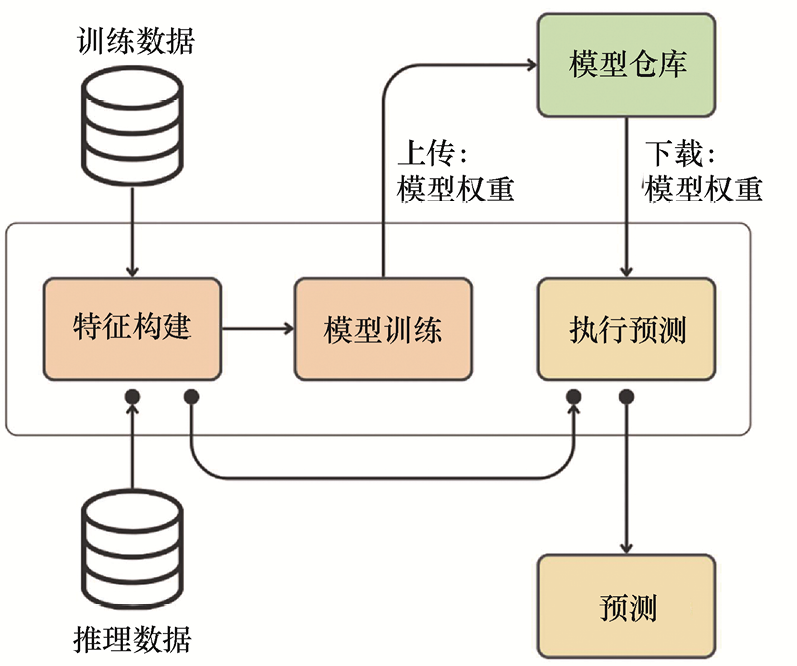
1.3.2 以往解决方案的问题 图1.2展示了机器学习应用的典型架构。这种架构基于单体批处理模式,将特征构建、模型训练和推理功能耦合在同一个组件中。这种设计可以快速解决机器学习领域中的一个关键问题——训练-服务偏差(training-serving skew)。训练-服务偏差是指模型在训练阶段和推理阶段使用不同方式计算特征时产生的偏差。
图1.2 单体批处理流水线架构
在这种架构下,特征构建使用相同的代码,从而解决了训练-服务偏差问题。这种模式在处理小规模数据时运行良好。系统会按计划以批处理方式运行流水线,并将预测结果输出给仪表盘等第三方应用程序使用。
遗憾的是,构建单体批处理系统会带来如下问题:
• 特征无法被当前系统或其他系统重复使用;
• 当数据量增大时,需要重构整个系统的代码以支持PySpark或Ray;
• 很难用C++、Java或Rust等更高效的编程语言重写预测模块;
• 难以在多个团队间合理分配特征工程、模型训练和预测模块的工作;
• 无法切换到流式技术来进行实时训练。
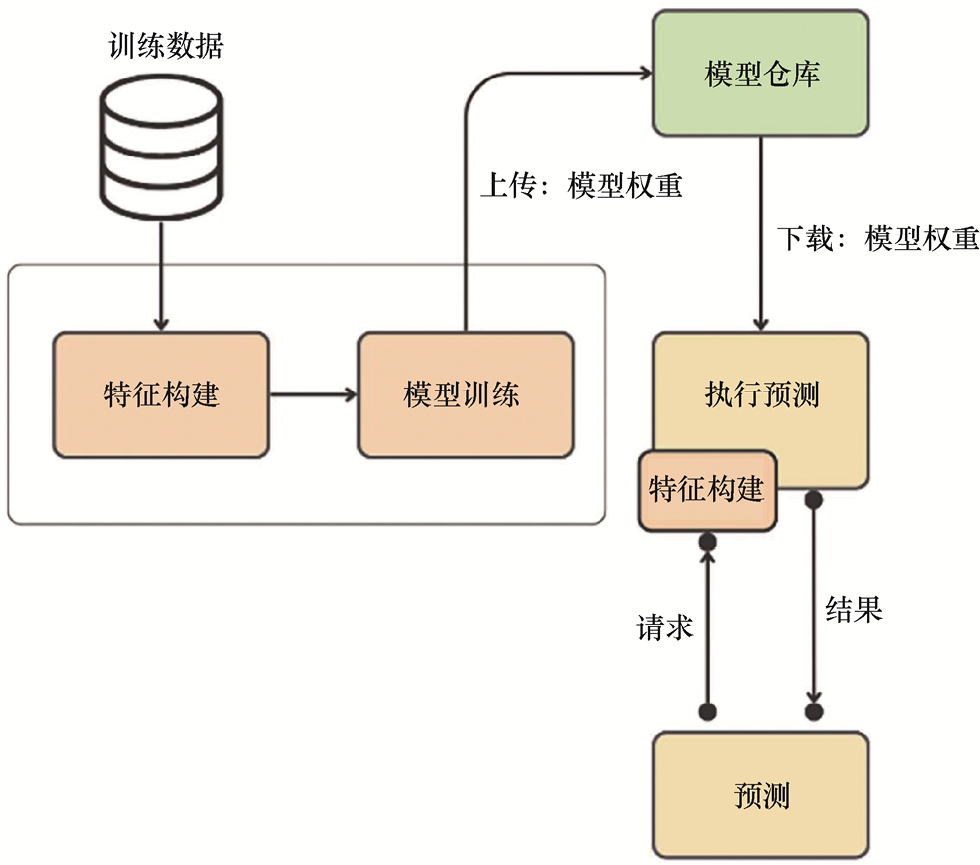
如图1.3所示,在实时系统架构中,除了上述问题,还引入了另一个问题——系统需要通过客户端请求传输完整的状态信息,以便计算特征并传递给模型进行预测。
以电影推荐系统为例,在图1.3所示的架构中,系统不仅需要传输用户ID,还必须传输用户的姓名、年龄、性别和观影历史等信息。这种架构设计存在较大风险,因为客户端必须了解如何访问这些状态,并且与模型服务紧密耦合。
再考虑一个支持RAG的LLM的场景。随查询一起添加的上下文文档代表了外部状态。如果没有将这些上下文文档存储在向量数据库中,就必须在每次查询时传递这些文档。这就要求客户端掌握上下文文档的查询和检索方法,但这是不可行的(让客户端应用程序负责特征的访问或计算是一种反模式设计)。RAG的相关内容,将在第4章和第9章介绍。
总结来说,我们面临的挑战是如何在不依赖客户端传入特征的情况下完成预测。以电影推荐系统为例,如何仅凭用户ID就能给出推荐内容?请记住这个问题,后面会回答。
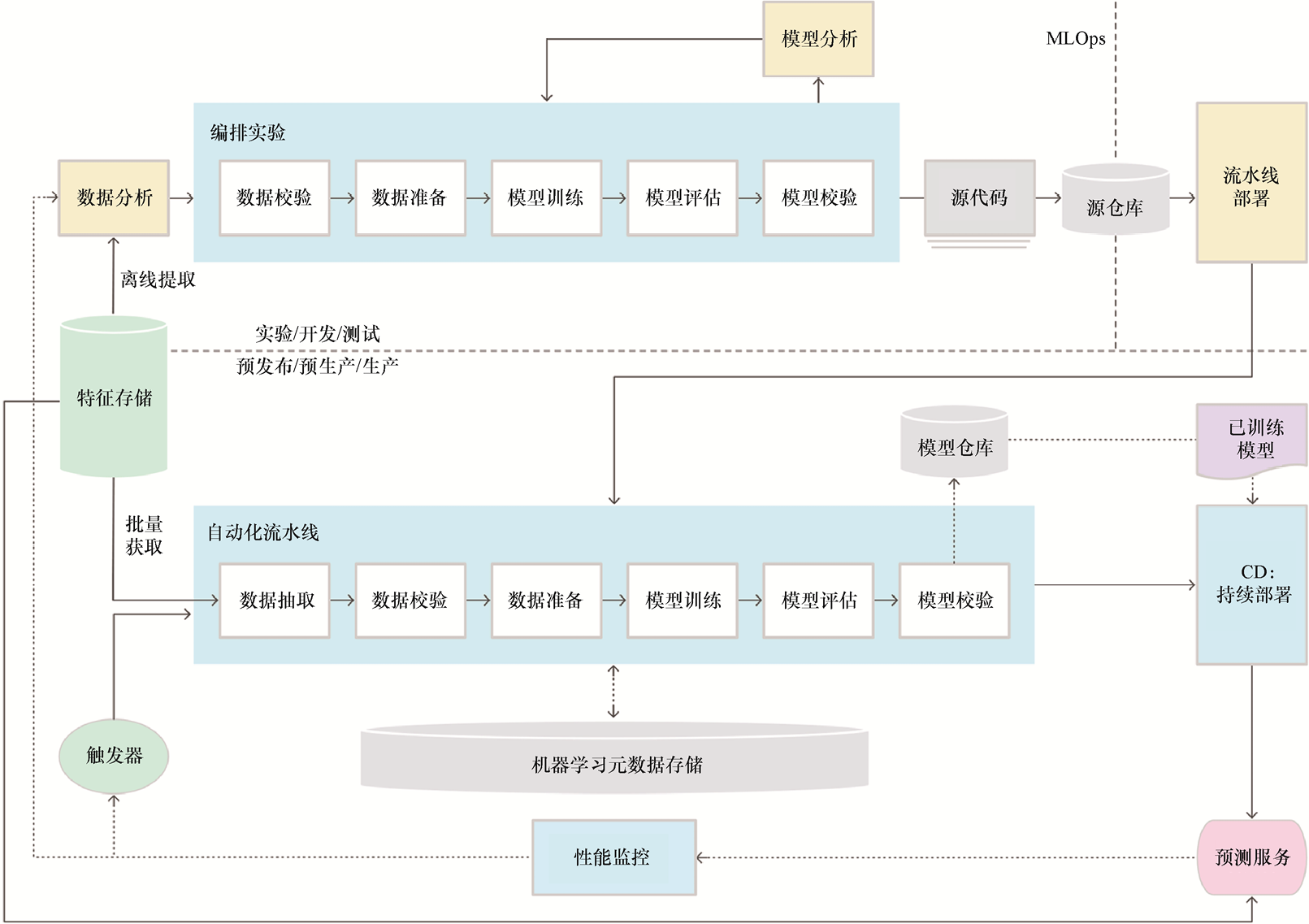
另外,谷歌云提供了一套面向生产环境的架构,如图1.4所示(转载自谷歌创建并分享的内容,按照知识共享署名4.0许可协议使用)。这套方案虽然可行,但对于缺乏在生产环境中部署和维护机器学习模型经验的开发者来说,这套架构比较复杂且不够直观。同时,要理解如何从小规模起步并随时间推移扩展系统也并不容易。
图1.3 无状态的实时系统架构
图1.4 面向持续训练的机器学习流水线自动化方案
但这正是FTI流水线架构的作用所在。1.3.3节将介绍如何通过一种直观的机器学习设计来解决这些基本问题。
1.3.3 解决方案:机器学习系统的流水线 解决方案是画一张清晰直观的思维导图,让任何团队或个人都能遵循它来完成特征计算、模型训练和预测。基于机器学习系统必需的3个关键步骤,这种模式被称为FTI流水线。
这种模式揭示了机器学习系统的本质:可以将其简化为特征、训练和推理3个流水线(与传统软件开发中的数据库、业务逻辑和用户界面层类似)。这种架构的强大之处在于,可以清晰地定义每个流水线的边界和接口,并且更方便理解各个流水线间的交互机制。相比图1.4中展示的20多个组件,3个流水线大大简化了系统设计,使得机器学习系统更加直观、易于理解和管理。
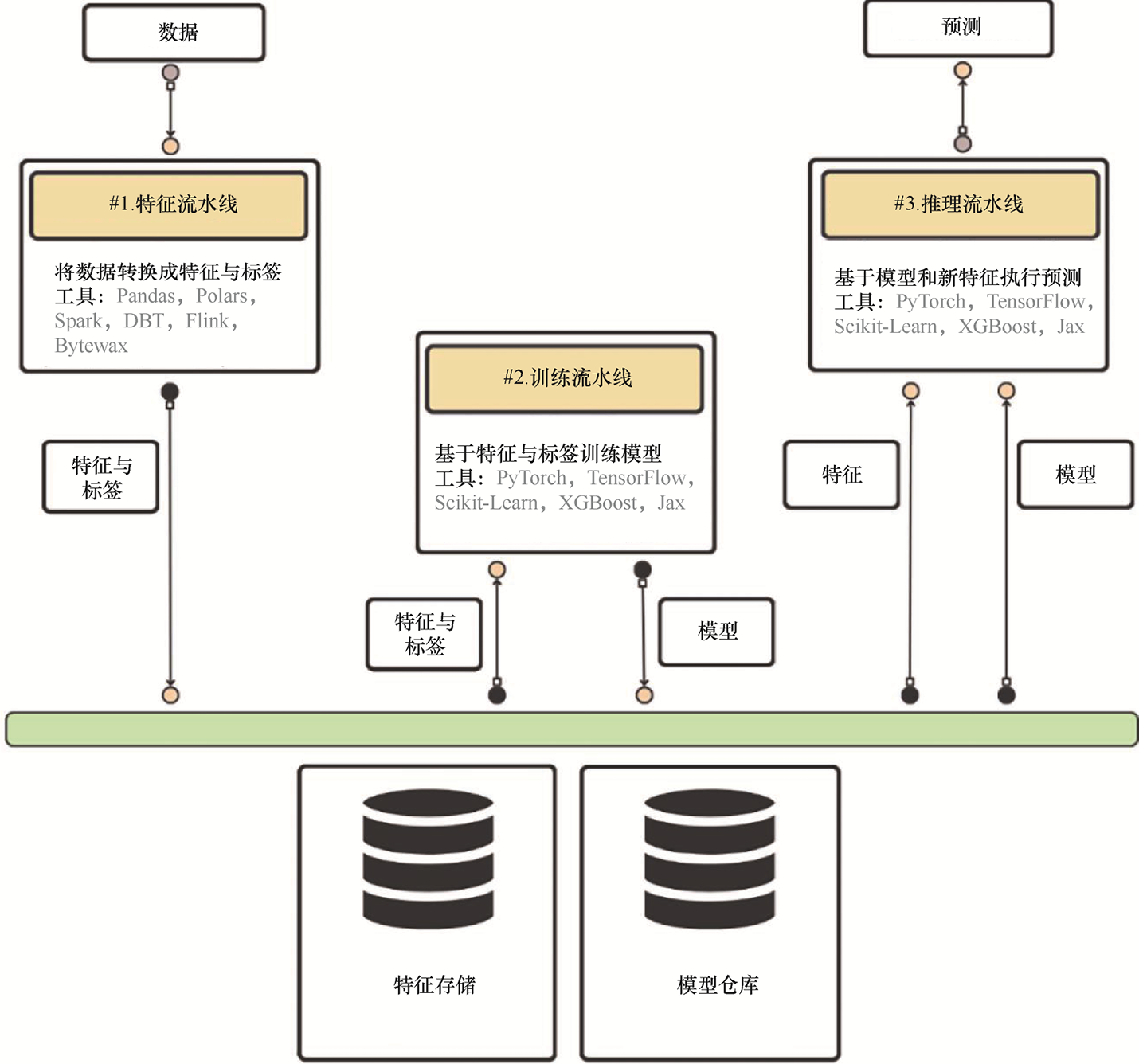
如图1.5所示,机器学习系统主要包含特征、训练和推理3个流水线。接下来将深入研究每个流水线,包括它们的范围和接口。
图1.5 FTI流水线的架构设计
在深入细节之前,理解每个流水线都是可以在不同进程或硬件上运行的独立组件至关重要。每个流水线可以使用不同的技术、由不同的团队开发,或采用不同的扩展方式。这种设计的关键在于它可以灵活应对团队需求,并可以作为构建系统架构的思维导图。
1.特征流水线 特征流水线将原始数据作为输入,经过处理后输出模型训练或推理所需的特征和标签。这些特征和标签并不直接传递给模型,而是存储在特征存储库中。特征存储库的职责是存储、版本控制、跟踪和共享特征。通过将特征保存在特征存储库中,我们始终能掌握特征的状态,进而可以轻松地将特征传递到训练和推理流水线。
由于数据采用版本化管理,可以始终确保训练和推理阶段的特征保持一致,从而避免训练-服务偏差问题。
2.训练流水线 训练流水线从存储的特征中获取特征和标签作为输入,并生成一个或多个训练模型。这些模型会被保存在模型仓库中。模型仓库的功能类似于特征存储,但在这里,模型是最重要的主体。因此,模型仓库负责模型存储、版本管理、追踪,并最终与推理流水线共享模型。
此外,大多数现代模型仓库都支持元数据存储功能,允许指定模型训练过程中的关键要素,包括用于训练模型的特征、标签及其版本,以确保模型的训练数据来源始终可知。
3.推理流水线 推理流水线以特征存储中的特征和标签,以及模型仓库中训练好的模型作为输入,来进行批量或实时模式的预测。
由于这是一种灵活的模式,因此我们可以自行决定如何处理预测结果。在批处理系统中,预测结果通常会被存储到数据库;而在实时系统中,则会直接返回给发出请求的客户端。系统对特征、标签和模型都实施了版本控制,这使得能够轻松地进行模型升级或回滚。例如,可以追踪到模型v1使用了F1、F2、F3这些特征,而模型v2使用了F2、F3、F4这些特征。因此,我们可以快速调整模型与特征之间的关联关系。
1.3.4 FTI流水线的优势 总结来说,在FTI流水线中,需要牢记的要点是如下所示的接口设计。
• 特征流水线接收数据,将特征和标签输出并保存到特征存储中。
• 训练流水线从特征存储中查询特征和标签,并将训练后的模型保存到模型仓库中。
• 推理流水线使用特征存储中的特征和标签,以及模型仓库中的模型来执行预测。
无论机器学习系统变得多么复杂,这些接口都将保持不变。
使用FTI流水线模式的优势主要有如下几点。
• 得益于只有3个组件,这个架构简单直观,便于理解和使用。
• 每个组件都可以采用独立的技术栈,这使我们能快速适应大数据、流式数据等特定需求,同时为每项任务选择最佳工具。
• 由于3个组件之间有清晰的接口,每个组件都可以由不同的团队开发(如有必要),这使得开发更易管理且具有可扩展性。
• 每个组件都可以独立部署、扩展和监控。
关于FTI模式,必须理解的最后一点是:系统不必只包含3个流水线。在大多数情况下,它会包含更多流水线。以特征流水线为例,它可能由计算特征的服务和验证数据的服务组成。同样,训练流水线也可以由训练组件和评估组件构成。
FTI流水线作为逻辑层,每个流水线都可以包含多个服务。但最关键的是要遵守统一的接口规范,确保FTI流水线之间能通过特征存储和模型仓库进行交互。这样,每个FTI组件就能独立演进,无须了解彼此的细节,也不会因新的变更而破坏系统。
有关FTI流水线的细节,可以阅读由Jim Dowling写作的From MLOps to ML Systems with Feature/Training/Inference Pipelines 文章。
1.4 设计LLM Twin的系统架构本节将列出LLM Twin应用的具体技术细节,并探讨如何通过FTI流水线设计LLM系统来解决这些问题。在深入讨论具体流程之前,需要强调的是,我们在这一步不会关注具体的工具和技术栈,而是专注于定义系统的高层架构,这种架构此时是与编程语言、开发框架、平台和基础设施无关的。我们将重点关注各个组件的职责范围、交互接口及它们之间的交互方式。具体的实现细节和技术栈将在后续章节中详细介绍。
1.4.1 列出LLM Twin架构的技术细节 到目前为止,我们从用户视角定义了LLM Twin需要提供的功能。现在,从纯技术角度来明确这个机器学习系统的需求。
• 在数据层面,需要完成以下任务:
✓ 从LinkedIn、Medium、Substack和GitHub自动并按计划收集数据;
✓ 对爬取的数据进行标准化处理并存入数据仓库;
✓ 清洗原始数据;
✓ 构建用于LLM微调的指令数据集;
✓ 对清洗后的数据进行分块和嵌入,将向量化数据存入向量数据库,以支持RAG。
• 训练过程需要执行以下步骤:
✓ 微调不同规模(7B、14B、30B或70B参数)的LLM;
✓ 在不同规模的指令数据集上进行微调;
✓ 在不同类型的LLM(如Mistral、Llama和GPT)之间切换;
✓ 跟踪和对比实验;
✓ 在生产部署前测试潜在的LLM候选模型;
✓ 当新的指令数据集可用时,自动开始训练。
• 推理代码将呈现以下特征:
✓ 为客户端与LLM Twin的交互提供REST API接口;
✓ 支持实时访问向量数据库以进行RAG;
✓ 使用不同规模的LLM进行推理;
✓ 根据用户请求进行自动弹性伸缩;
✓ 自动部署通过评估的LLM。
• 系统将提供以下LLMOps功能:
✓ 指令数据集的版本控制、溯源和复用;
✓ 模型的版本控制、溯源和复用;
✓ 实验追踪;
✓ CI/CD/CT;
✓ 提示与系统监控。
这些技术要求的相关介绍会在后续相关章节中详细展开。
以上需求列表包含了LLM Twin项目的核心功能。在实现每个组件时,必须问自己一个问题:如何应用FTI流水线设计来实现上述需求列表?
1.4.2 使用FTI流水线设计LLM Twin架构 我们将系统分为4个核心组件。为什么是4个,而不是FTI流水线设计中明确的3个?答案很简单:除了特征流水线、训练流水线和推理流水线这3个组件,还必须实现数据采集流水线。其根据是以下最佳实践:
• 数据工程团队负责数据采集流水线;
• 机器学习工程团队负责 FTI 流水线。
考虑到用小团队构建MVP的目标,必须实现整个应用系统,包括定义数据采集和FTI流水线。端到端地解决问题的情况在无力负担专门团队的初创公司中很常见,这就要求工程师必须根据产品状态承担多重职责。在任何情况下,了解端到端机器学习系统的工作原理对于更好地理解他人的工作都是有价值的。
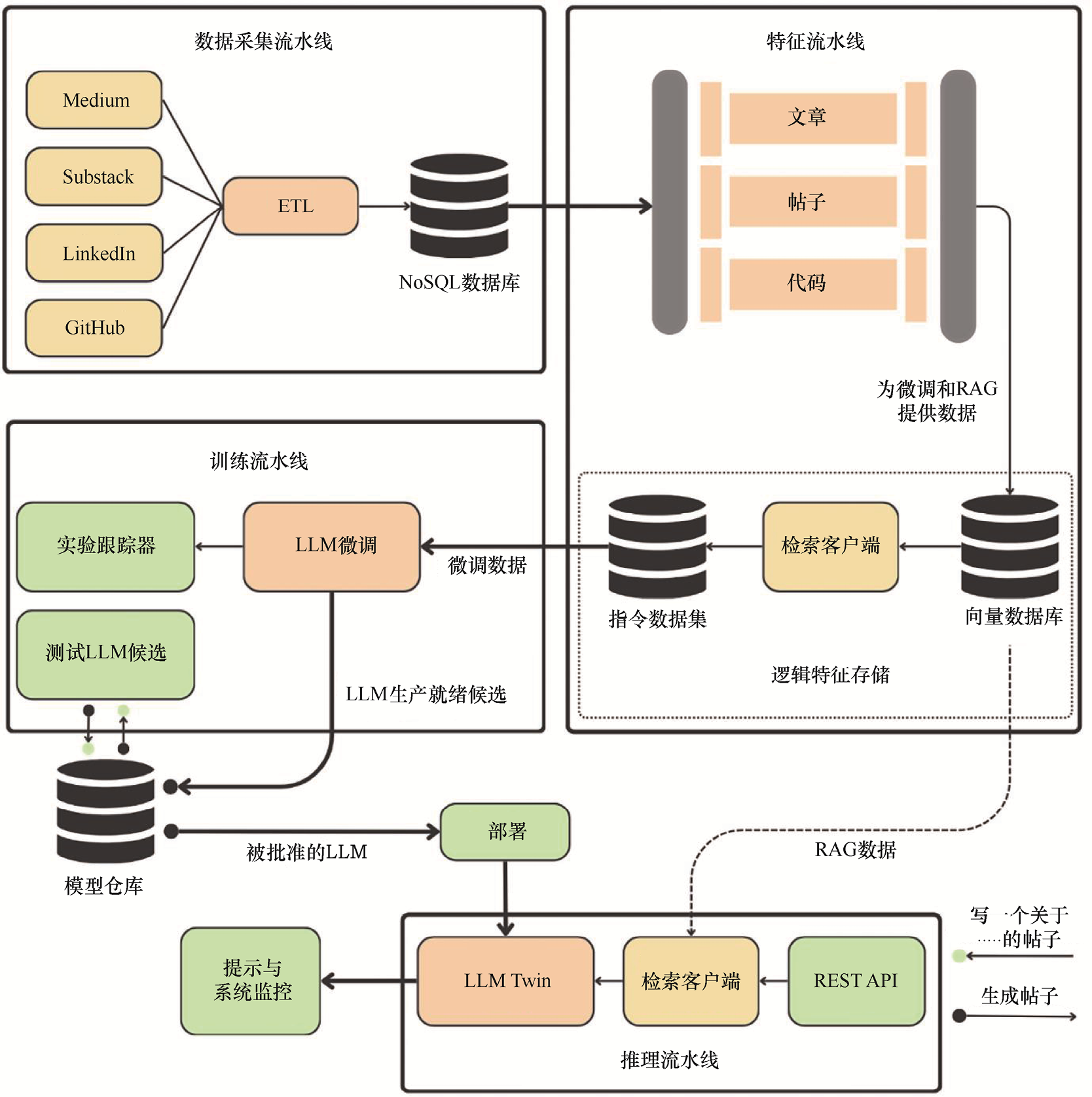
图1.6展示了LLM Twin系统架构。理解它的最佳方式是逐一审视这4个组件及其工作原理。
图1.6 LLM Twin系统架构
1.数据采集流水线 数据采集流水线主要用于从 Medium、Substack、LinkedIn 和GitHub等平台爬取你的个人数据。遵循提取、转换、加载(extract/transform/load,ETL)模式构建数据采集流水线,从社交媒体平台提取数据、进行数据标准化,并将处理后的数据加载到数据仓库中。
需要特别强调的是,数据采集流水线的设计仅限于抓取我们自己在社交媒体平台上的数据,而不会访问其他人的信息。作为示例,我们同意将收集的数据用于学习目的,否则未经他人同意使用其数据是不道德的行为。
这个组件的输出是一个NoSQL数据库,它将作为我们的数据仓库。由于处理的是非结构化的文本数据,NoSQL数据库完全符合需求。
尽管MongoDB等NoSQL数据库通常不被视为数据仓库,但它实际承担了数据仓库的作用。为什么?因为它存储了经过各类ETL流水线收集的标准化原始数据,这些数据已为接入机器学习系统做好准备。
收集的数字数据被划分为以下3类:
• 文章(Medium、Substack);
• 帖子(LinkedIn);
• 代码(GitHub)。
我们需要将数据源平台抽象化。例如,在向LLM输入文章时,知道它来自Medium还是Substack并不重要,只需将源URL作为元数据保留以供参考。然而,从数据处理、模型微调和RAG的角度来看,了解输入数据的类型至关重要,因为每个类型都必须采用不同的处理方式。例如,对帖子、文章和代码片段的分块策略会有所不同。
此外,通过按类型而非来源对数据进行分组,可以快速将其他平台的数据纳入系统,例如将X平台的数据插入到帖子集合中,或将GitLab的数据插入到代码集合中。作为一个模块化系统,只需在数据采集流水线中添加一个额外的ETL处理逻辑,其他部分就能继续运行,无须任何代码修改。
2.特征流水线 特征流水线的作用是从数据仓库中获取原始的文章、帖子和代码数据,对其进行处理,然后将其加载到特征存储中。
至此,FTI模式的特征已经显现。
以下是LLM Twin特征流水线的定制属性:
• 能够以不同方式处理文章、帖子和代码这3类数据;
• 微调和RAG所需的3个主要处理步骤——数据清洗、分块和嵌入;
• 创建两个数字数据快照——清洗后的快照用于微调,嵌入后的快照用于RAG;
• 使用逻辑特征存储,而非专用特征存储。
在基于RAG的系统中,向量数据库是基础设施的核心组件之一。本项目没有集成另一个专门的特征存储数据库,而是选择直接使用向量数据库,并通过添加额外的逻辑来确保满足系统对特征存储的所有需求。
在向量数据库中并没有训练数据集的概念,但它可以用作NoSQL数据库,这意味着可以通过数据点的ID和集合名称来访问数据。因此,在不使用任何向量搜索逻辑的情况下,可以轻松地从向量数据库中查询新的数据点。最终,将检索到的数据封装成一个带版本、可追踪和可共享的工件(artifact,将在第2章中介绍)。目前,读者只需知道这是MLOps的一个概念,用于封装数据并为其添加上述属性。
系统的其他组件将如何访问逻辑特征存储?训练流水线会将指令数据集作为工件使用,而推理流水线则会通过向量搜索技术从向量数据库中查询以获取其他上下文。
这已满足需求,原因主要包括以下几点:
• 这些工件在训练等离线使用场景中表现出色;
• 向量数据库是为在线访问构建的,这正是在推理时所需要的。
后续章节将解释如何对文章、帖子和代码这3类数据进行清洗、分块和嵌入处理。
总之,我们会获取原始的文章、帖子或代码数据点,对其进行处理后保存在特征存储中,使训练和推理流水线能够访问这些数据。值得注意的是,当去除所有复杂性而只关注接口时,这与FTI模式完美匹配。很优雅,对吧?
3.训练流水线 训练流水线从特征存储中获取指令数据集,用其对LLM进行微调,并将微调后的模型权重存储在模型仓库中。具体来说,当逻辑特征存储中有新的指令数据集可用时,将触发训练流水线来获取该数据集,并对LLM进行微调。
在项目初期,这一步骤由数据科学团队负责。他们通过自动超参数调优或手动方式运行多组实验,以寻找最合适的模型和超参数。为了比较和选择最佳超参数组合,将使用实验跟踪器记录有价值的信息,并在不同实验间进行对比。最终,团队将选定最佳超参数和经过微调的LLM,将其作为LLM生产就绪候选模型。这个候选模型随后会被存储在模型仓库中。在实验阶段结束后,存储并复用这些最佳超参数,以消除流程中的手动限制。现在,就能实现完全自动化的训练过程了,这就是所谓的持续训练(CT)。
测试流水线会执行比微调阶段更为详尽的分析。在将新模型推送到生产环境前,需要通过一系列更严格的测试评估,以确保最新的候选模型优于当前生产环境中的模型。通过测试后,该模型会被标记为“已接受”并部署到生产推理流水线中。即便在全自动化的机器学习系统中,在接受新的生产模型前,仍建议保留一个人工步骤。这类似于在执行一个具有重大后果的重要操作前按下“红色按钮”。在这个阶段,专家会审阅测试组件生成的报告。如果一切看起来都很好,专家将批准该模型,随后自动化流程继续执行。
该组件主要关注LLM的以下几个特定问题。
• 如何构建一个LLM无关的通用流水线?
• 应该采用哪些微调技术?
• 如何在不同规模的LLM和数据集上优化微调算法?
• 如何从多轮实验中筛选最佳的LLM生产就绪模型?
• 如何通过测试来评估LLM是否具备生产部署的条件?
最后要阐明的是CT 。通过模块化设计,可以迅速运用机器学习编排工具来调度和触发系统的各个组件,例如配置数据采集流水线每周自动抓取数据。
进一步地,当数据仓库中有新数据时,可以触发特征处理流水线;当有新的指令数据集时,则触发训练流水线。
4.推理流水线 推理流水线与模型仓库和逻辑特征存储相连,从模型仓库中加载经过微调的LLM,同时通过逻辑特征存储访问用于RAG的向量数据库。该流水线通过REST API接收客户端查询请求,并利用微调后的LLM和向量数据库来执行RAG并回答查询。
系统会将所有客户端查询、使用RAG增强的提示及生成的答案发送至提示监控系统,用于分析、调试和更好地理解系统。监控系统可根据具体需求触发告警,以便手动或自动采取行动。
在接口层面,该组件完全遵循FTI流水线架构,但当深入观察时可以看到LLM和RAG系统的如下一些独有特征:
• 用于执行RAG向量搜索的检索客户端;
• 用于将用户查询和外部信息映射至LLM输入的提示模板;
• 提示监控专用工具。
1.4.3 关于FTI流水线架构和LLM Twin架构的最终思考 FTI模式本质上是一个用于指导机器学习系统设计的工具,无须仅仅因为遵循常规做法就使用专用的特征存储产品。在本书的LLM Twin架构中,使用基于向量数据库和工件的逻辑特征存储不仅更简单,而且成本更低。需要关注的是,特征存储提供的必要属性,如可版本化和可复用的训练数据集。
最终简要说明各个组件的计算需求。数据采集流水线和特征处理流水线主要基于CPU运算,对硬件配置要求不高。训练流水线需要配备强大GPU的机器,以支持LLM的加载和微调。推理流水线的计算需求介于两者之间,它仍需要性能强大的机器,但计算强度低于训练阶段。由于推理流水线直接与用户交互,因此必须经过仔细测试,确保延迟控制在良好用户体验所需的参数范围内,不过使用FTI流水线架构并不是问题,可以根据每个组件的有特点配置适当的计算资源。
此外,各流水线的扩展方式分别为:数据采集流水线和特征流水线将根据CPU和内存负载进行水平扩展;训练流水线将通过增加更多GPU进行垂直扩展;推理流水线将根据客户端请求数量进行水平扩展。
总之,LLM Twin架构满足了1.4.1节列出的所有技术要求:按要求处理数据,训练过程模块化,可以快速适应不同的LLM、数据集或微调技术;推理流水线支持RAG并通过REST API接口提供服务;在LLMOps方面,系统支持数据集和模型的版本控制、版本回溯追踪和可复用性;系统配备了监控服务,整个机器学习架构的设计都考虑到了CI/CD/CT。
1.5 小结作为一本面向产品的书籍,本书将介绍如何构建端到端的机器学习系统,因此首先介绍了LLM Twin的概念。随后,介绍了MVP的概念,并讲解如何基于可用资源规划LLM Twin的MVP。接着,将这个概念转化为具有明确需求的实用技术方案。在此背景下,介绍了FTI模式,并展示了它在设计模块化和可扩展系统中的实际应用。最终,成功应用FTI模式设计出了满足所有技术需求的LLM Twin架构。
在构建系统时,对全局有清晰的认识至关重要。在开发某个组件时,理解它如何集成到应用程序的其他部分可以带来很大的回报。因此,本章从LLM Twin架构的抽象介绍开始,重点讲解每个组件的职责范围、接口及它们之间的交互机制。
后续章节将继续探讨各个组件的实现和部署方法。在MLOps方面,本书将介绍如何使用计算平台、任务编排、模型仓库、制品管理等工具,以支持MLOps的所有最佳实践。