版权信息 书名:百页大模型原理
ISBN:978-7-115-68343-4
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
版 权 著 [加]安德烈·布可夫(Andriy Burkov)
译 彭文华 于冰冰
责任编辑 卜一凡
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线: (010)81055410
反盗版热线: (010)81055315
版权声明 Simplified Chinese translation copyright © 2026 by Posts and Telecom Press.
ALL RIGHTS RESERVED.
The Hundred-Page Language Models Book: hands-on with PyTorch, ISBN 978-1778042720.
Published by arrangement with Andriy Burkov.
Copyright © 2025 Andriy Burkov.
本书中文简体字版由作者Andriy Burkov授权人民邮电出版社出版。未经出版者书面许可,对本书的任何部分不得以任何方式或任何手段复制和传播。
版权所有,侵权必究。
内容提要 大模型经历了从统计语言模型到基于神经网络的语言模型,再到Transformer架构的演进过程,如今已在各领域广泛应用且备受关注。本书围绕大模型展开,共分为6章。首先介绍机器学习基础,包括人工智能、模型、神经网络等概念;接着阐述语言建模基础,涵盖统计语言模型及其评估技术;随后聚焦循环神经网络,讲解其实现与训练过程;继而深入解析Transformer架构,涉及自注意力机制等关键组件;然后探讨与大模型相关的议题,如微调预训练模型、减少幻觉现象等;最后总结全书并延伸介绍混合专家模型、模型压缩等前沿拓展内容。全书语言精练,配有实操代码示例。
本书适合软件开发者、数据科学家、机器学习工程师,以及对大模型感兴趣、具备一定编程经验(最好熟悉Python语言)和大学数学基础,希望理解大模型的数学基础、探究其运作原理、自行实现核心组件或学习高效运用大模型的方法的读者阅读。
以爱为名,献给家人
译者序 遇到问题就打开手机问问DeepSeek,梳理工作思路时找豆包聊一聊,代码出了Bug也让通义千问帮忙看看。如今,人工智能已不再是高高在上的“新贵”,而成了陪伴我们日常学习与工作的好帮手。与此同时,很多人心中也藏着好奇与困惑:这一切究竟是如何发生的?想要学习新知识,却往往被“语言模型”“Transformer”等术语吓退;动辄厚如砖头的技术专著、满页令人望而生畏的公式,更提高了入门的门槛;好不容易找到一些资料,却发现不是过于浅显、流于表面,就是晦涩难懂、难以真正落地。
本书正是破解这些困境的钥匙。其英文原版The Hundred-Page Language Models Book 虽仅百页,却因内容专业精练,成为无数AI学习者推崇的“封神级”入门佳作。中译本特别采用了小巧的开本设计,最终呈现为这本既专业实用又便于携带的精致小书。
本书最打动我的,是安德烈·布可夫(Andriy Burkov)将复杂技术化繁为简的“魔力”。不同于传统技术图书堆砌理论的写法,本书把实际业务问题和技术原理有机地融合在一起。每个知识点都采用“原理+案例”的形式展开;在阐述计算过程时,总能借助贴切的类比或图像化的方式拆解核心逻辑。更难得的是,书中还提供了完整的可运行的Python代码,从数据处理到模型调试,每一步都清晰可循,让人一看就懂,懂了就能用。
本书的创作理念,是通过系统性的认知建构与循序渐进的数学引导,让读者自然领悟技术精髓,而非强求令人望而生畏的“跨越式”学习。这也正是我想与大家分享的:学习大模型不必畏惧那些艰深的术语,不妨直接动手实践,在探索中逐步深入,开卷自有收获。
无论你是希望入门AI的学生,还是正寻求转型或夯实基础的开发者,这本小书都能成为你得力的向导。
我与好友于冰冰在翻译本书时,始终秉持着原作者“简洁明了”的初心,遵循精准而不失通俗、专业亦兼顾易懂的原则精心打磨。希望这本译作能在你学习大模型的路上点亮一盏小灯,驱散前行中的技术迷雾。愿你翻开本书时,能卸下对技术的畏惧,在简明精练的文字中感受AI的魅力,快速掌握大模型的核心原理,从而在AI的浪潮中乘风破浪、稳步前行。
彭文华
2026年1月
序 我第一次涉足语言建模领域已经是20年前的事了。当时,我想改进自己的一些数据压缩算法,偶然发现了n 元组统计方法。这是一个非常简单的概念,但很难被超越!很快,我又有了另一个动机—自童年起,我就对人工智能充满了兴趣。我曾幻想机器能够理解我们这个世界中人类有限心智所无法察觉的模式。如果能和这样的超级智能对话,该多么令人兴奋啊!而且,我意识到语言建模或许是实现这种人工智能的一条途径。
我开始寻找与我有相同愿景的人,并发现了Solomonoff和Schmidhuber的研究成果,以及由Matt Mahoney组织的Hutter竞赛。他们都曾撰文论述语言建模对人工智能完备性的意义,我深知自己必须让语言模型发挥作用。但那时的世界与如今大不相同,语言建模被认为是一个没有发展前景的研究方向。我无数次听到别人劝我放弃,因为当时普遍认为,在处理大量数据时,没有什么能比得上n 元组模型。
我完成了关于神经语言模型的硕士论文,因为这些模型与我之前为数据压缩开发的模型非常相似,而且我坚信,可应用于任何语言的分布式表示是正确的研究方向。这激怒了当地的一位语言学家,他宣称我的想法纯属无稽之谈,理由是语言建模必须从语言学角度处理,且每种语言都必须区别对待。
然而,我没有放弃,而是继续致力于实现人工智能完备的语言模型这一愿景。在我开始攻读博士学位前的那个夏天,我萌生出利用这些神经模型生成文本的想法。我惊讶地发现,它们生成的文本比n 元组模型生成的文本好得多。那是2007年夏天,我很快意识到,在布尔诺理工大学,真正对这件事感到兴奋的似乎只有我自己。但无论如何,我都没有放弃。
在接下来的几年里,我开发了许多使神经语言模型更加实用的算法。为了向他人证明其优越性,我在2010年发布了开源工具包 RNNLM。它首次实现了神经文本生成、梯度裁剪、动态评估、模型适配(即现在的“微调”),并引入了softmax 或将不常见单词拆分为子词单元等其他技巧。然而,最让我感到自豪的成果是,我在博士论文中证明了神经语言模型不仅在大型数据集上超越了n 元组模型(这在当时被认为是不可能的事情),而且随着训练数据量的增加,其性能实际上也在不断提高。这是语言模型领域历经约50年后的首次研究突破。我至今仍记得,当我向一些知名研究人员展示我的研究成果时,他们脸上那难以置信的表情。
一晃大约15年过去了,世界发生的巨大变化令我惊叹不已。人们的观念彻底转变了——一种曾经被视为“没有前景”的鲜为人知的技术,如今正蓬勃发展,并吸引了全球各大型企业首席执行官的关注。如今,语言模型无处不在。在如此热潮之下,我认为现在比以往任何时候都更有必要切实了解这项技术。
那些想要学习语言建模的年轻学生正被海量的信息所淹没。因此,当得知安德烈计划写一本只有大约百页篇幅、涵盖最重要理念的简明手册时,我非常高兴。我认为对任何刚接触语言建模并渴望在该领域取得突破的人来说,本书都是一个很好的起点。如果有人告诉你,语言建模领域的所有发明发现都已经实现,千万不要相信。
托马斯·米科洛夫(Tomáš Mikolov)
捷克信息学、机器人学和控制论研究所高级研究员
word2vec 和FastText 的核心发明者
前 言 我对文本处理的兴趣始于20世纪90年代末,那时正值青少年的我已经开始使用Perl和HTML语言创建动态网站了。早期编程和将文本组织成结构化格式的经历,激发了我对文本处理和转换的浓厚兴趣。随着时间的推移,我的研究方向逐渐深入至构建网络爬虫和文本聚合器,开发从网页中提取结构化数据的系统。处理和理解文本的挑战促使我探索更复杂的应用,包括设计能够理解并满足用户需求的聊天机器人。
提炼文字含义的挑战令我痴迷。这项任务的复杂性反而激发了我利用一切工具和手段“战胜”它的决心——我使用了所有可用的工具,从正则表达式、脚本语言,到文本分类器和命名实体识别模 型 。
大语言模型 (以下简称大模型)的兴起带来了颠覆性的变革。这是计算机第一次能够与人类流畅对话,并且能以极高的精准度执行口头指令。当然,与其他工具一样,大模型虽功能强大,也有其局限性。有些局限显而易见,但有些则更为隐蔽,需要具备深厚的专业知识才能妥善应对。不理解图纸就建设摩天大楼,最后只能得到一堆混凝土和钢材的混合物。大模型亦如此。处理大规模文本任务或为付费用户开发可靠的产品都需要专业知识和周密实施,纸上谈兵是行不通的。
本书的目标读者 本书献给所有与我一样,痴迷于挑战“机器语言理解”难题的人。大模型 本质上是数学函数,但仅从理论上进行研究,无法充分认识其真正潜力。唯有上手实操,我们才能感受到大模型的威力,见识到它们的能力如何随着规模的扩大而不断提升。这就是我决定将本书设计为实操型图书的原因。
本书适合软件开发者、数据科学家、机器学习工程师,以及所有对大模型感兴趣的读者阅读。无论读者的目标是将现有模型集成到应用程序中,还是训练自己的模型,都能在本书中找到理论基础和实践指导。
本书对读者有一定的要求:读者应该具备一定的编程经验,因为所有的实操示例都使用Python语言编写。
虽然熟悉PyTorch和张量(PyTorch的基础数据类型)对阅读本书会有帮助,但这不是必需的。如果读者对这些工具还不熟悉,本书的维基页面(thelmbook.com/wiki)提供了介绍,并附有示例和进一步学习的资源链接。维基形式能确保内容与时俱进,并在图书出版后持续回应读者提出的问题。
具备大学水平的数学知识有助于理解本书,但读者不必记住所有细节内容,也无须具备机器学习经验。本书将系统性地介绍相关概念,从符号表示、定义及基本的向量和矩阵运算开始,逐步深入简单的神经网络 ,进而拓展到更高级的内容。书中以直观的方式呈现数学概念,并配有清晰的图表和示例,以帮助读者理解。
本书不涵盖的内容 本书英文原版仅有百页左右的篇幅,重点是理解和实现大模型,以下内容不在本书的讨论范围内。
• 大规模训练: 本书不会详述如何在分布式系统上训练超大规模的模型,也不涉及训练基础设施的管理方法。
• 生产部署: 本书不涉及诸如模型服务、API开发、高流量扩展、监控和成本优化等内容。书中的代码示例旨在帮助理解概念,而非用于实际生产。
• 企业应用: 本书不会指导如何构建商业化的大模型应用、处理用户数据,以及与现有系统集成。
如果读者希望理解大模型的数学基础,探究其运作原理,自行实现核心组件,或学习高效运用大模型的方法,本书将是理想选择。但如果读者的核心诉求是在生产环境中部署模型,或创建一个可扩展的应用,那么建议结合其他资料辅助学习。
全书结构 为帮助读者建立系统认知并增加阅读深度,本书以大模型为核心框架,涵盖当今文献中常被忽视的传统方法。尽管目前基于Transformer的大模型已经占据主导地位,但统计语言模型、循环神经网络 (Recurrent Neural Network,RNN) 等传统方法对特定的任务仍然有效。
对初学者而言,从零开始理解Transformer架构的数学原理可能令人望而却步。为此,本书通过回顾这些传统方法,帮助读者逐步建立直觉认知与数学理解,使读者的知识体系更新到 Transformer 架构的过程水到渠成,而非令人望而生畏的大跨越。
全书共分6章,内容由浅入深逐步展开。
• 第1章 涵盖机器学习的基础知识,包括人工智能、模型、神经网络和梯度下降 等关键概念。即使读者很熟悉这些内容,为便于后续理解大模型,本章仍会提供其核心内容以供参考。
• 第 2章 介绍语言建模的基本原理,探讨文本的表示方法(如词袋模型 、词嵌入 ),以及统计语言模型 及其评估技术。
• 第3章 聚焦于循环神经网络,详解其实现方式、训练过程和在语言模型中的应用。
• 第4章 深入解析Transformer架构,包括自注意力机制 、位置编码 等关键组件和实现方法。
• 第5章 探讨大模型,详述规模效应的重要性、微调技术 、实际应用场景,以及幻觉 、版权与伦理等关键议题。
• 第6章 总结全书,并延伸至混合专家模型 、模型压缩 、偏好对齐 、视觉大模型 等进阶方向,为后续学习提供路径指引。
本书大部分章提供实操代码示例供读者运行或修改。因篇幅有限,书中仅呈现核心代码片段,读者可根据“资源与支持”页的指引获取完整的代码。所有代码均兼容 Python、PyTorch 及其他依赖库的最新稳定版本。
代码基于 Google的Colab 设计。撰写本书时,Colab仍为用户免费提供 GPU、TPU 等计算资源。当然,免费资源存在配额限制,并且可能被动态调整,部分示例需长时间占用 GPU,因此可能需要排队等待。如果免费资源不足,Colab 也提供按需计费服务,用户可以自行购买算力券(compute credit) ,以获得可靠的 GPU 访问权限。按北美的收费标准,目前的算力券费用比较实惠,但实际费用可能因读者所在地区不同而存在较大差异。
熟悉 Linux 命令行的读者,也可考虑按时计费的 GPU 云服务,租用一个配置单卡或者多卡的虚拟机实例。本书的维基页面会持续更新免费/付费的 Notebook 服务及GPU租赁平台的最新信息。
本书排版遵循技术文档惯例,使用Courier New 字体用于标明代码、代码片段或代码的输出,黑体 用于强调术语,有时也用于突出显示算法步骤。
为统一环境配置,本书使用 pip3 来确保更新至Python 3 安装包。在大多数已配置Python 3的开发环境中,也可以直接使用 pip 。
致谢 本书的高质量出版离不开众多编辑的倾力付出。特别感谢 Erman Sert、Viet Hoang Tran Duong、Alex Sherstinsky、Kelvin Sundli和Mladen Korunoski的系统性贡献。
感谢 Alireza Bayat Makou、Taras Shalaiko、Domenico Siciliani、Preethi Raju、Sriku-mar Sundareshwar、Mathieu Nayrolles、Abhijit Kumar、Giorgio Mantovani、Abhinav Jain、Steven Finkelstein、 Ryan Gaughan、 Ankita Guha、 Harmanan Kohli、 Daniel Gross、 Kea Kohv、 Marcus Oliveira、Tracey Mercier、Prabin Kumar Nayak、Saptarshi Datta、Gurgen R. Hayrapetyan、Sina Ab-didizaji、Federico Raimondi Cominesi、Santos Salinas、Anshul Kumar、Arash Mirbagheri、Roman Stanek、Jeremy Nguyen、Efim Shuf、Pablo Llopis、Marco Celeri、Tiago Pedro和Manoj Pillai 等伙伴的帮助。
如果这是你首次接触大模型,我甚至有点羡慕你—了解机器如何通过自然语言理解世界,真的是一种奇妙的体验。
我希望你能享受阅读本书的过程,就像我享受创作本书的过程一样。
现在,沏一壶热茶或咖啡,让我们启程吧!
资源与支持 资源获取 本书提供如下资源:
• 配套代码文件;
• 本书思维导图;
• 异步社区7天VIP会员。
要获得以上资源,您可以扫描右上方二维码,根据指引领取。
提交勘误信息 作者、译者和编辑尽最大努力来确保书中内容的准确性,但难免会存在疏漏。欢迎您将发现的问题反馈给我们,帮助我们提升图书的质量。
当您发现错误时,请登录异步社区(https://www.epubit.com),按书名搜索,进入本书页面,单击“发表勘误”,输入勘误信息,单击“提交勘误”按钮即可(见下图)。本书的作者、译者和编辑会对您提交的勘误信息进行审核,确认并接受后,您将获赠异步社区的100积分。积分可用于在异步社区兑换优惠券、样书或奖品。
与我们联系 我们的联系邮箱是contact@epubit.com.cn。
如果您对本书有任何疑问或建议,请您发邮件给我们,并请在邮件标题中注明本书书名,以便我们更高效地做出反馈。
如果您有兴趣出版图书、录制教学视频,或者参与图书翻译、技术审校等工作,可以发邮件给我们。
如果您所在的学校、培训机构或企业,想批量购买本书或异步社区出版的其他图书,也可以发邮件给我们。
如果您在网上发现有针对异步社区出品图书的各种形式的盗版行为,包括对图书全部或部分内容的非授权传播,请您将怀疑有侵权行为的链接通过邮件发送给我们。您的这一举动是对作者权益的保护,也是我们持续为您提供有价值的内容的动力之源。
关于异步社区和异步图书 “异步社区”是由人民邮电出版社创办的IT专业图书社区,于2015年8月上线运营,致力于优质内容的出版和分享,为读者提供高品质的学习内容,为作译者提供专业的出版服务,实现作译者与读者在线交流互动,以及传统出版与数字出版的融合发展。
“异步图书”是异步社区策划出版的精品IT图书的品牌,依托于人民邮电出版社在计算机图书领域40余年的发展与积淀。异步图书面向IT行业以及各行业使用IT的用户。
第1章 机器学习基础 本章将介绍机器学习的基础理论框架。首先从人工智能的发展历程切入,明确定义模型概念,并阐述机器学习的4个核心步骤。接着讲解向量和矩阵等必备数学基础知识,在探讨神经网络之前夯实根基。最后重点讲解梯度下降和自动微分两大关键优化技术。
1.1 人工智能和机器学习人工智能(Artificial Intelligence,AI) 一词最早于1955年在John McCarthy主持的一次研讨会上被提出。参加该研讨会的研究人员旨在探索机器如何使用语言、形成概念、像人类一样解决问题,以及如何随着时间的推移不断改进。
1.1.1 人工智能萌芽期 该领域的首次重大突破出现在1956年,其标志是“逻辑理论家”(Logic Theorist)的诞生。它由Allen Newell、Herbert Simon和Cliff Shaw共同开发,是第一个被设计用于执行自动推理的程序,后称为“第一个人工智能程序”。
Frank Rosenblatt 在1958年发明的感知机(perceptron) 是一种早期的神经网络(neural network) ,它通过根据样本调整其内部参数来识别模式。如图1-1所示,感知机能学习一个决策边界(decision boundary ) —一条用于区分不同类别(例如,垃圾邮件与非垃圾邮件)的分界线。
图1-1 利用感知机进行垃圾邮件分类
大约在同一时期的1959年,Arthur Samuel 创造性地提出了机器学习(machine learning) 这一术语。在他的论文《利用跳棋游戏进行的机器学习研究》(Some Studies in Machine Learning Using the Game of Checkers)中,他将机器学习描述为“对计算机进行编程,使其能够从经验中学习”。
20世纪60年代中期的另一项值得关注的研究成果是 ELIZA 。它是由 Joseph Weizenbaum 于1967年开发出来的历史上首个聊天机器人(chatbot)。它通过匹配用户文本中的模式并生成预编程的回复,营造出一种它能理解语言的假象。尽管其原理很简单,但它展示了构建能够表现出思考或理解能力的机器所具有的吸引力。
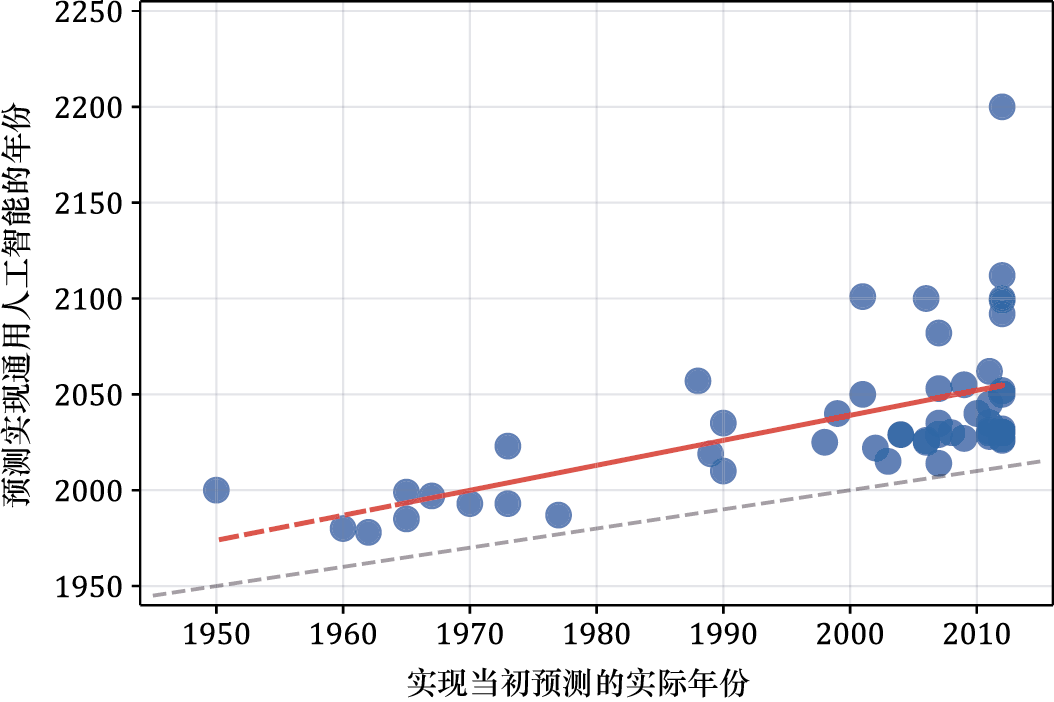
这一时期,人们对短期内取得重大突破充满了乐观。后来的图灵奖得主Herbert Simon就是一个典型代表。他在1965年曾经预测:“未来20年内,机器将能够完成人类所能做的任何工作。”许多专家都持有同样的乐观态度,预测真正达到人类水平的人工智能——通常称为通用人工智能(Artificial General Intelligence,AGI ) ——仅需几十年就能实现。有趣的是,这些预测呈现出一种一致的模式:通用人工智能似乎始终还需25年才能实现。图1-2展示了人们对通用人工智能的预测结果。
图1-2 人们对通用人工智能的预测结果
1.1.2 人工智能寒冬 当研究人员试图兑现早期的承诺时,他们遇到了始料未及的复杂情况。许多备受瞩目的项目均未能实现当初雄心勃勃的目标。因此,在1975年至1980年间,资金投入和公众热情大幅减退,这一时期被称为第一次人工智能寒冬(AI winter) 。
在第一次人工智能寒冬期间,就连“人工智能”这个词也在一定程度上成为禁忌。许多研究人员将他们的研究工作重新命名为“信息学”“基于知识的系统”或“模式识别”,以避免与人工智能的失败形象联系起来。
20世纪80年代,专家系统(一种基于规则,旨在复制人类专业知识的软件)重新引起了人们的兴趣,这种系统有希望获取特定领域的专业知识并使其实现自动化应用。这些专家系统属于广义人工智能的一个研究分支,称为符号人工智能(symbolic AI) ,也称为传统人工智能(Good Old-Fashioned AI,GOFAI)。 自人工智能诞生之初,它就一直占据主导地位。传统人工智能依赖于明确编码的规则和符号来表示知识和逻辑,虽然它们在定义明确的垂直领域表现良好,但在可扩展性和适应性方面却面临挑战。
从1987年到2000年,人工智能进入第二次寒冬。在此期间,符号方法的局限性导致资金投入锐减,这再次导致众多研发项目被搁置或取消。
尽管遭遇了诸多挫折,新的技术仍在不断发展。尤为值得一提的是决策树(decision tree) ,它于1963年由 John Sonquist 和 James Morgan首次提出,随后在1986年由 Ross Quinlan提出的迭代二叉树 3 (Iterative Dichotomiser 3,ID3) 算法进一步发展。决策树通过树状结构将数据分割成若干子集。决策树中的每个节点代表一个关于数据的问题,每个分支是一个答案,而每个叶节点则提供一个预测结果。虽然决策树易于解释,但它们容易出现过拟合现象,即模型对训练数据的拟合过于紧密,从而降低了其在新的、未见过的数据上的表现能力。
1.1.3 人工智能新纪元 到了20世纪90年代末和21世纪初,硬件的逐步发展及更大规模数据集的可获取性(得益于互联网的广泛使用)开始让人工智能摆脱第二次寒冬。Leo Breiman 在2001年提出的随机森林(random forest) 算法,通过在数据的随机子集上创建多个树结构,然后组合它们的输出结果,解决了决策树存在的过拟合问题,从而大大提高了预测准确性。
1992年,Vladimir Vapnik 和他的同事提出的支持向量机 (Support Vector Machine,SVM) 是人工智能领域又一次意义重大的进步。支持向量机能够识别出最优超平面(optimal hyperplane),以最大间隔将不同类别的数据点分隔开来。核方法(kernel method) 的引入使支持向量机能够通过将数据映射到更高维度的空间来处理复杂的非线性模式,从而更容易找到合适的分隔超平面。这些创新使支持向量机在21世纪初成为机器学习研究的重点。
转折点出现在2012年前后,当时一种更为先进的神经网络版本——深度神经网络( deep neural network ) 开始在语音和图像识别等领域超越其他技术。与只使用单一“层”可学习参数的简单感知机不同,这种深度学习( deep learning ) 方法堆叠了多个层来解决更为复杂的问题。计算能力的显著提升、丰富的数据和算法上的进步共同促成了人工智能领域的重大突破。随着学术界和商业界对人工智能兴趣的飙升,人工智能受到的关注和获得的资金也大幅增加。
如今,人工智能和机器学习仍然紧密相连。科研界和产业界仍在不断努力,以寻求更强大的模型,使其能够从数据中学习复杂的任务。尽管“在短短25年内”实现人类水平人工智能的预测一直未能成真,但人工智能对日常应用的影响是毋庸置疑的。
在本书中,人工智能泛指那些能让机器解决曾被认为只能由人类才能解决的问题的技术,而机器学习是其关键的子领域,专注于创建从一系列样本中学习的算法。这些样本可以源自大自然、由人类设计,也可以由其他算法生成。该过程涉及收集数据集并从中构建模型,然后利用该模型解决实际问题。
为了节约字数,我会交替使用“学习”和“机器学习”这两个词。
让我们来探究一下,我们所说的模型到底是什么,以及它是如何奠定机器学习基础的。
1.2 模型模型(model) 通常由函数(function) 是一种有名字的规则,它描述了一组值与另一组值的关系。从形式上讲,函数域(domain) 中的输入映射到共域(codomain) 中的输出,确保每个输入都有且仅有一个输出。该函数使用特定的规则或公式将输入转换为输出。
在机器学习中,目标是收集一组样本数据集(dataset of example), 并使用它们来构建函数
例如,我们需要根据房屋的面积来估算其价格,数据集可能包含诸如{(150,200),(200,600),…}这样的(面积,价格)对。在这里,面积的单位是平方米(m2),而价格的单位是千美元。
大括号表示一个集合。包含从N 个元素的集合表示为
设想我们有一套面积为250平方米(约2 691平方英尺)的房子。我们想要找到一个函数
让我们将函数
这是关于线性函数(linear function)。 式子线性变换(linear transformation) 。
符号
对于线性函数而言,确定函数只需要两个值:b 。这些值称为该模型的参数( parameter) 或权重(weight) 。
在其他文献中,斜率(slope) 、系数(coefficient) 或权重项( weight term) 。同样,截距(intercept) 、常数项(constant term) 或偏差(bias) 。在本书中,我们将w 称为“权重”,b 称为“偏差”,因为这些术语在机器学习中被广泛使用。当含义明确时,“参数”和“权重”可以互换使用。
例如,当
图1-3 线性函数权重-偏差关系示意图
在这里,偏差项使图像在竖直方向上发生位移,所以这条直线在
从数学角度来讲,函数仿射变换(affine transformation) ,而不是线性变换,因为真正的线性变换要求
即便使用像
设我们的数据集为输入(input) ,对应的目标值(target) 。当样本既包含输入又包含目标值时,称这种学习过程为监督学习(supervised learning) 。本书主要关注有监督机器学习。
其他类型的机器学习包括无监督学习(unsupervised learning) 和强化学习(reinforcement learning) 。在无监督学习中,模型仅从输入数据中学习;在强化学习中,模型通过与环境交互,并因其行为获得奖励或惩罚来学习。
当
上式称为平方误差(squared error) ,当
我们将
让我们通过展开每个
我们将上式命名为
(1.3)
在定义
式(1.3)称为线性回归(linear regression) 机器学习问题的损失函数( loss function) 。在这种情况下,损失函数就是均方误差(Mean Squared Error,MSE) 。
为了找到函数的最优值(最小值或最大值),我们需要计算它的一阶导数(first derivative) 。当达到最优值时,一阶导数等于零。对于像损失函数偏导数(partial derivative) 。我们用
为了确定
我们将偏导数设为零,因为当这种情况发生时,我们就处于该函数的最优值点。
幸运的是,均方误差函数的结构和模型的线性性质使我们能够通过解析的方法来求解这个方程组。为了说明这一点,假设我们有一个包含 3 个样本的数据集:
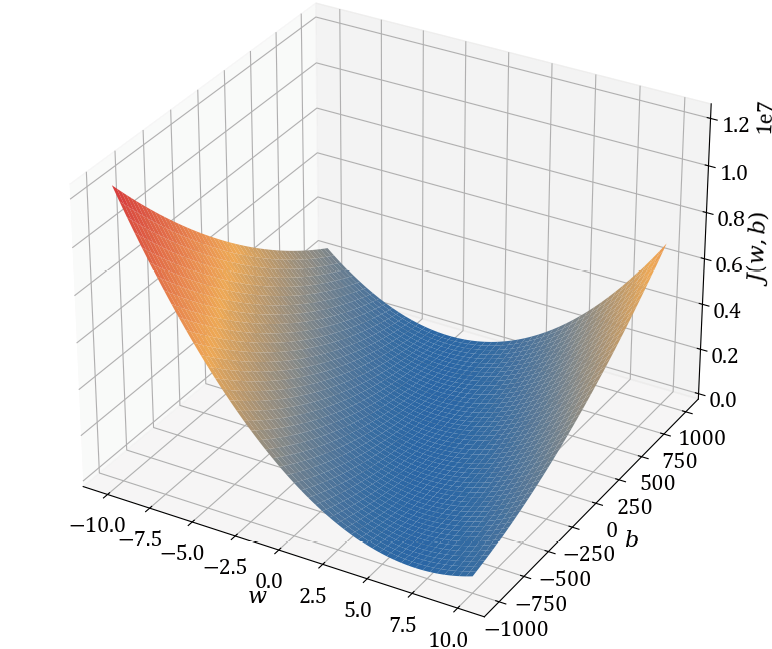
让我们来绘制一下图形,如图1-4所示。
图1-4 损失函数可视化
用于生成图1-4的代码可以从配套资源的quadratic_loss.py文件中找到。运行代码,并旋转图形以观察最小值。
现在我们需要推导
• 函数
• 函数
• 函数
函数的复合( composition of function) 意味着一个函数的输出成为另一个函数的输入。例如,对于两个函数
在我们的损失函数
利用求导的加法法则和常数倍法则,
其中,
求导的加法法则(sum rule) 表明,两个函数之和的导数等于它们各自导数的和,即常数倍法则(constant multiple rule) 表明,一个常数与一个函数相乘所得结果的导数,等于该常数乘以这个函数的导数,即
通过应用求导的链式法则,
求导的链式法则(chain rule) 表明,复合函数(composite function)
然后
因此
同样,我们发现:
将偏导数设置为0,会得到以下方程组:
化简该方程组,并使用代入法求解变量,可得到最优值:
由此得到的模型蓝色 圆点)、模型曲线本身(红色 实线),以及对一套面积为240平方米的新房价格预测(橙色 点线)。
图1-5 基于房屋面积的房价预测趋势图
图1-5中,竖直的蓝色 虚线对比显示了模型预测误差的平方根与房屋实际价格。误差越小,意味着模型对数据的拟合效果越好。损失函数将这些误差汇总起来,用于衡量模型与数据集的契合程度。
当我们使用模型的训练数据集,也就是训练集(training set) 来计算损失时,我们得到的是训练损失(training loss) 。对于我们的模型而言,这种训练损失由式(1.3)定义。现在,利用此前学习到的参数值,就可以计算出训练损失:
经过上述计算,所得结果15 403.19的平方根约为124.1,表明平均预测误差约为124 100美元。训练损失值是高还是低,取决于具体的业务场景和比较基准。本章稍后探讨的神经网络和其他非线性模型,通常能实现更低的损失值。
1.3 机器学习4步流程到这一步,你应该清楚地理解监督学习的4个步骤。
1)收 集数据集: 例如,
2)定义模型结构: 如
3)定义损失函数: 如式(1.3)所示。
4)最小化损失: 在数据集上最小化损失函数。
在上述例子中,我们通过手动求解一个二元方程组来最小化损失。这种方法适用于简单的系统。然而,随着模型复杂度的增加,例如,拥有数十亿参数的大语言模型(以下简称“大模型”),手动求解方法就无法实现了。现在,我们引入一些新的概念,以帮助我们应对这一挑战。
1.4 向量要预测房价,仅仅知道房屋的面积是不够的。建造年份、卧室和浴室的数量等因素也很重要。假设我们使用两个属性:面积和卧室数量。在这种情况下,输入特征向量(feature vector) 。该向量包含两个特征(feature) ,也称为维度(dimension) 或分量(component) :
在本书中,向量用小写粗斜体字母表示,如
一个向量通常表示为一列数字,称为列向量(column vector) 。然而,在文本中,它通常被写成其转置( transpose)形式 行向量(row vector) 。例如,
向量的维度(dimensionality) 或大小(size) 是指它包含的分量数量。在这里,
该线性模型有两个特征,因此有3个参数:权重
这样,线性模型可以简洁地写成:
其中,点积(dot product ) ,也称为标量积(scalar product) 。其定义如下:
点积运算将两个相同维度的向量组合起来,得到一个标量(scalar) —类似于线性变换(linear transformation) 的概念推广到了向量。
上式使用了大写西格玛表示法(capital-sigma notation) ,其中
尽管大写西格玛表示法让人觉得点积运算可能是通过循环来实现的,但现代计算机的处理方式要高效得多。像BLAS(Basic Linear Algebra Subprogram)和cuBLAS这样经过优化的线性代数库(linear algebra library),会使用底层的、高度优化的方法来计算点积。这些库利用硬件加速和并行处理技术,实现了远超简单循环的运算速度。
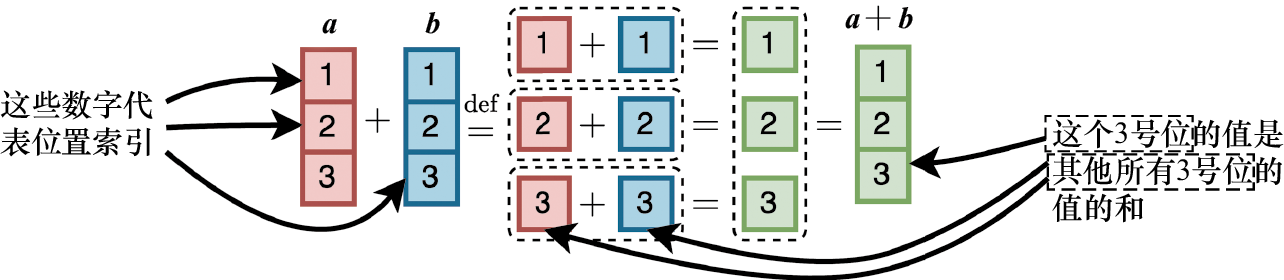
两个维度均为向量 的和 定义为
图1-6 举例说明了两个三维向量求和的计算过程。
图1-6 两个三维向量求和的计算过程
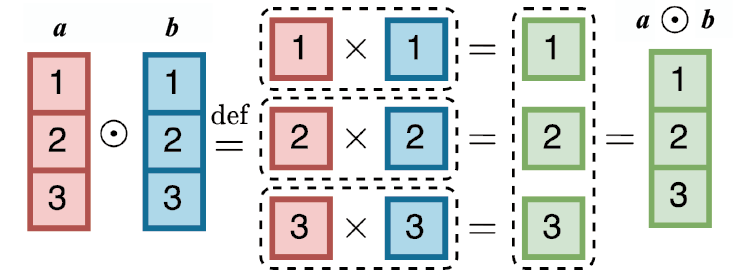
在本章的插图中,单元格中的数字表示某个元素在输入、输出矩阵或向量中的位置,而不是实际的数值。
两个维度为逐元素乘积(element-wise product) 定义如下:
图1-7展示了两个三维向量逐元素乘积的计算过程。
图1-7 两个三维向量逐元素乘积的计算过程
向量范数(norm) ,记作长度 (length) 或大小(magnitude) 。它被定义为该向量的各分量平方和的平方根,即
对于一个二维向量
两个向量
两个向量之间夹角的余弦值可以量化它们的相似性。例如,两套房屋如果面积和卧室数量都相近,它们的余弦相似度会接近1,否则该值会更低。余弦相似度(cosine similarity ) 被广泛用于比较表示为嵌入向量(embedding vector) 的单词或文档。这将在2.2节中进一步讨论。
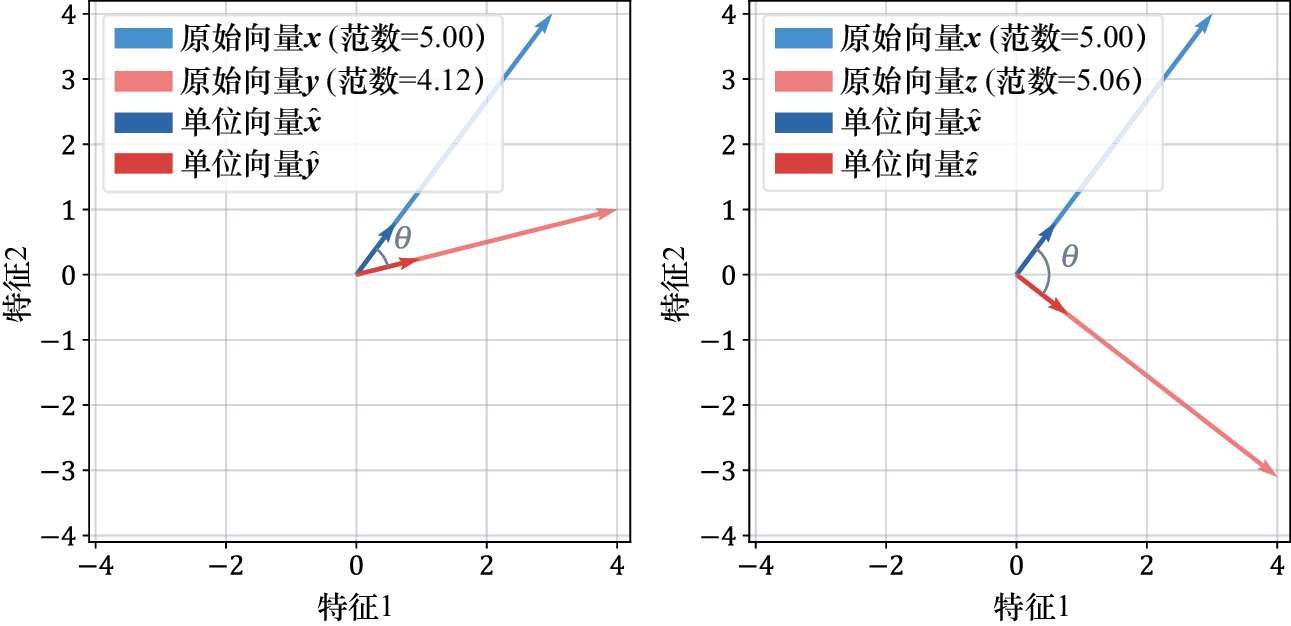
零向量(zero vector) 的所有分量都等于0。单位向量(unit vector) 的长度为归一化(normalization) :
用一个向量除以一个数会得到一个新的向量,新向量的每个分量都是原始向量的相应分量除以这个数所得的结果。
单位向量保留了原始向量的方向,但长度为
图1-8 二维向量经归一化变为单位向量的前后对比图
单位向量之所以有价值,是因为它们的点积等于它们之间夹角的余弦值,而且计算点积的效率很高。当文档被表示为单位向量时,通过计算查询向量和文档向量之间的点积,就能快速找到相似的文档。这就是Milvus、Qdrant和Weaviate等向量搜索引擎和库的运行方式。
随着维度的增加,线性模型中的参数数量变得庞大,无法通过手动方式求解。此外,在高维空间中,我们无法从视觉上验证数据是否遵循线性模式。即使能够对三维以上的空间进行可视化,我们仍然需要更灵活的模型来处理线性模型无法拟合的数据。
1.5节将介绍非线性模型,重点是神经网络。这些是理解大模型(一种特定类型的神经网络架构)的关键。
1.5 神经网络神经网络 与线性模型有两个关键的不同之处:它将固定的非线性函数应用于可训练的线性函数的输出;它的结构更复杂(深度更深),通过层次结构将多个函数组合在一起。下面我们来说明这些差异。
像复合函数
我们先定义
由于
直线通常无法很好地拟合一维数据中的规律,这一点在把线性回归 应用于非线性数据时表现得尤为明显,如图1-9所示。
图1-9 线性回归拟合非线性数据的效果图
为了解决这个问题,我们引入非线性因素。对于一维输入而言,模型变为
函数激活(activation) 函数 。常见的选择如下。
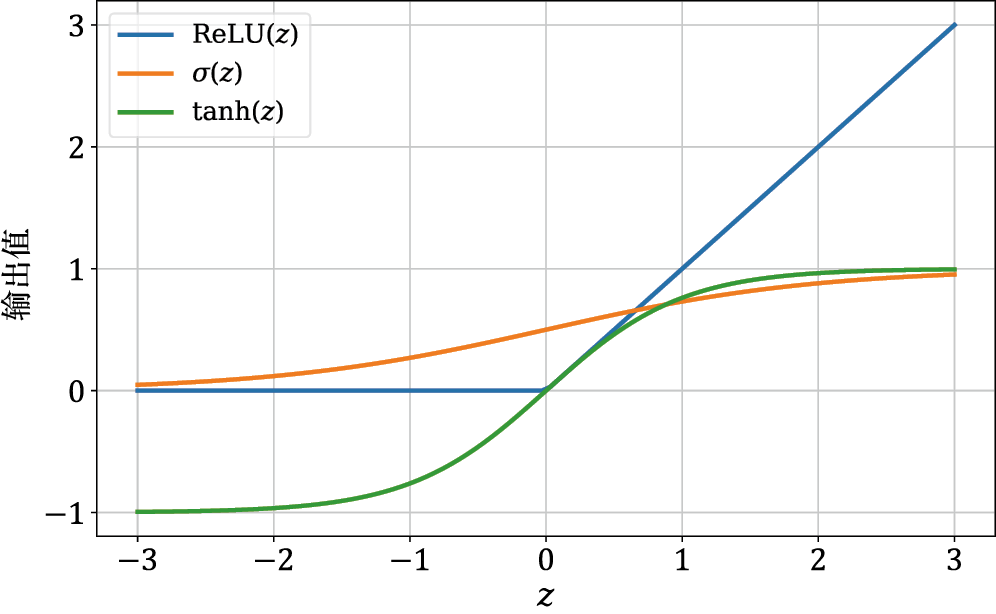
1)修正线性单元(Rectified Linear Unit,ReLU)函数:
2)sigmoid 函数: 二分类(binary classification ) 场景(例如,在垃圾邮件分类场景中,将垃圾邮件分类为
3)双曲正切函数(tanh函数):
在这些方程中,自然常数(即欧拉数,Euler ’ s number), 其值约为
这些函数之所以被广泛应用,是因为它们具备出色的数学特性、简洁性,以及在各种应用中的高效性。图 1-10是它们的函数图形表示。
图1-10 ReLU函数、sigmoid函数和双曲正切函数示意图
复合模型(composite model) :
其中,输入
图1-11所示是复合模型
图1-11 复合模型
计算图(computational graph) 展示了模型的结构。上面的计算图展示的两个非线性单元 (蓝色 方框)通常称为人工神经元(artificial neuron) 。每个神经元包含权重和偏差两个可训练的参数,用灰色圆圈表示。左箭头“←”表示将右侧的值赋给左侧的变量。该图展示了一个两层的基本神经网络,每层包含一个神经元。实践中,大多数神经网络是用很多层构建的,并且每层包含多个神经元。
假设我们有一个二维输入:一个包含3个神经元的输入层(input layer) ,以及一个只有单个神经元的输出层(output layer) 。其计算图如图1-12所示。
这种结构代表的是前馈神经网络(Feedforward Neural Network,FNN),在该网络中,信息沿单一方向(从左至右)流动,没有循环。如图1-12所示,当每一层的神经元都连接到下一层的所有神经元时,我们称之为多层感知机(Multilayer Perceptron,MLP)。如果某层的每个神经元都连接到相邻两层的所有神经元,那么这一层就称为全连接层(fully connected layer),或称为稠密层(dense layer)。
在第3章中,我们将探讨循环神经网络(Recurrent Neural Network,RNN) 。与前馈神经网络不同,循环神经网络具有循环结构。在该结构中,某一层的输出可以用作自身的输入。
图1-12 两层神经网络计算图
卷积神经网络(Convolutional Neural Network,CNN) 是一种具有卷积层的前馈神经网络,其卷积层并不是全连接的。虽然CNN最初是为图像处理而设计的,但它们在处理文本数据(如文档分类)时也非常有效。如果想了解更多关于卷积神经网络的内容,请查阅本书维基页面中的附加资料。
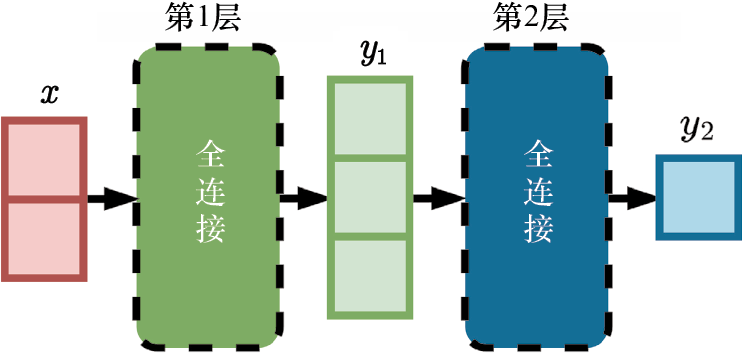
为了简化图表,可以用方块来代替单个神经元。采用这种方法,上面两层神经网络的结构可以用图1-13来更简洁地表示。
图1-13 两层神经网络的结构
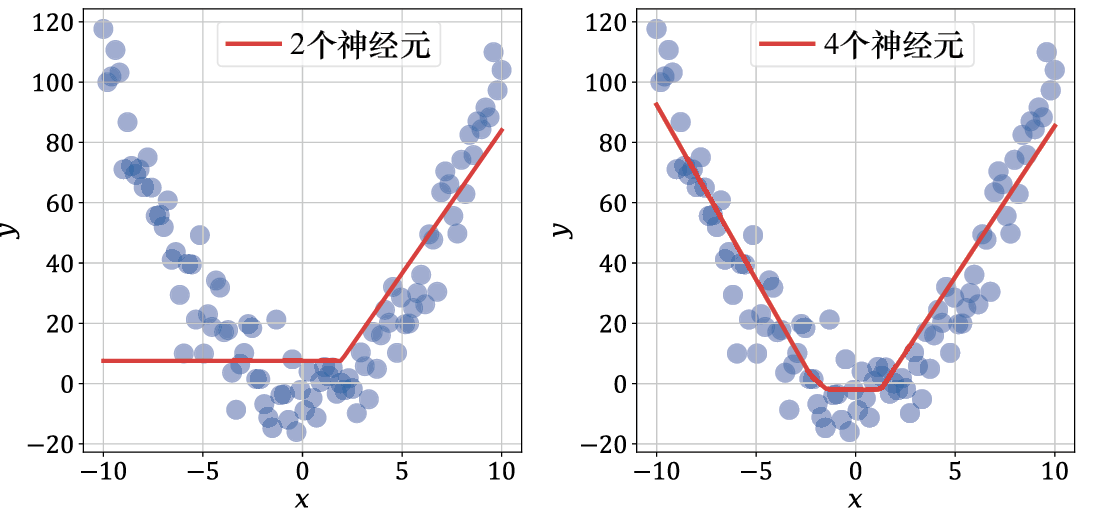
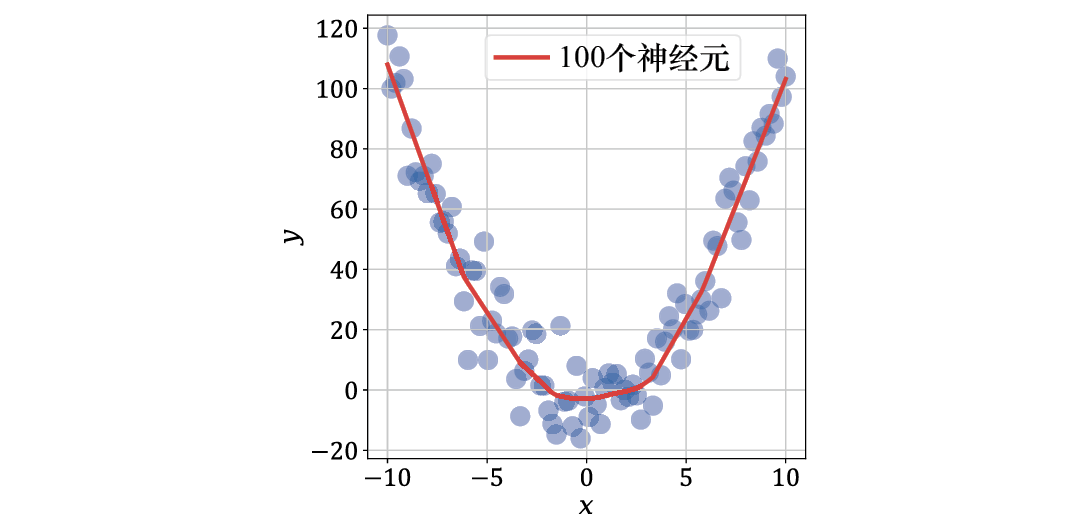
如果你认为这个简单的模型表达能力不足,那就看看图1-14。它包含3个子图,展示了如何通过增加模型大小(神经元数量)来提高拟合效果。其中:上方左侧的子图是一个包含2个神经元(一个输入神经元和一个输出神经元)的模型,并且使用了修正线性单元激活函数;上方右侧的子图是一个包含4个神经元(3个输入神经元和1个输出神经元)的模型;下方的子图展示了一个更大的模型,包含100个神经元。
图1-14 拥有2个、4个和100个神经元的神经网络模型拟合效果
修正线性单元激活函数虽然形式简单,但在机器学习领域却是一个重大突破。2012年之前,神经网络采用的是诸如tanh函数和sigmoid函数这样的平滑激活函数,这使训练深度模型变得越来越困难。我们将在第4章关于Transformer神经网络架构的部分再次回到这个话题。
增加参数数量有助于模型更准确地拟合数据。实验一致表明,增加神经网络的层数或者增加每层神经元的数量,都可以提高其拟合自然语言、语音、音频、图像和视频等高维数据的能力。
1.6 矩阵神经网络能够处理高维数据集,但需要大量的内存和计算资源。如果简单地逐个计算每一层的变换,就需要对每个神经元的数千个参数进行迭代,而这样的神经元可能有数千个,层数可能有几十层,这既缓慢又会消耗大量资源。使用矩阵(matrix) 可以让计算变得更高效。
矩阵 是一种由数字组成的二维数组,这些数字按行和列排列。矩阵将向量的概念推广到了更高的维度。从形式上来说,一个
其中,m 乘以n ”)。
矩阵在机器学习中是基础要素。它们能简洁地表示数据和权重,并通过加法、乘法和转置等运算实现高效计算。在本书中,矩阵用大写粗斜体字母表示,如
具有相同维度的两个矩阵 相加 ,其和是逐元素定义的:
例如,对于两个维度为
图1-15 矩阵 A 和矩阵 B 相加
维度为相乘 ,得到维度为
例如,对于一个
图1-16 矩阵 A 和矩阵 B 相乘
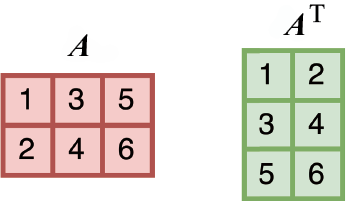
对矩阵转置 操作会交换它的行和列,从而得到它的转置矩阵
例如,对于一个
图1-17 矩阵A 转置成矩阵
矩阵与向量相乘(matrix-vector multiplication) 是矩阵乘法的一种特殊情况。当一个
例如,一个
图1-18 4×3的矩阵A 与三维向量x 相乘
神经网络全连接层的权重和偏差可以通过矩阵和向量简洁地表示出来,从而能够利用高度优化的线性代数库。因此,矩阵运算构成了神经网络训练和推理的核心。
让我们用矩阵符号表示图1-12中的模型。设
第二层也使用了一个权重矩阵和一个偏差。第二层的输出
式(1.6)和式(1.7)共同描述了神经网络中从输入到输出的运算过程,其中每一层的输出都作为下一层的输入。
1.7 梯度下降神经网络通常规模庞大,且由非线性函数构成,这使通过解析的方法求解损失函数的最小值变得不可行。因此,梯度下降算法被广泛用于最小化损失,在大模型中也是如此。
举一个实际应用的例子:二分类 问题。这个任务将输入的数据分类到两个类别中,例如,判断一封电子邮件是否为垃圾邮件,或者检测一个网站连接请求是否为分布式拒绝服务(DDoS)攻击。
我们的训练数据集D 为
其中,sigmoid 函数。
这种模型称为逻辑斯谛回归(logistic regression)模型 ,通常用于二分类任务。逻辑斯谛回归与线性回归 的区别在于:线性回归产生的输出范围从
尽管逻辑斯谛回归已有80多年历史,但它仍然是生产环境中使用最广泛的机器学习算法之一。
在这种情况下,二元交叉熵(binary cross-entropy) 损失函数就成为损失函数(loss function) 的一个常用选项,二元交叉熵损失也称为逻辑斯谛损失(logistic loss) 。对于单个样本
式中,预测得分(prediction score) ,即模型对输入向量自然对数(natural logarithm) 。
损失函数通常设计为对错误的预测进行惩罚,同时对准确的预测给予奖励。为了理解为什么逻辑斯谛损失适用于逻辑斯谛回归,可以假设两种极端情况。
1)完美预测 ,当
此时损失为零,这是很好的表现,因为预测值与标签值完全匹配。
2)相反的情况是 ,当
对于整个数据集D ,损失由数据集中所有样本的平均损失给出:
为了简化梯度下降的推导过程,我们只考虑单个样本
为了最小化损失函数复合函数 ,因此我们将使用链式法则 。
• 函数1:
• 函数2:
• 函数3:
请注意,
我们将
对于偏差
这就是机器学习数学的魅力所在:激活函数(sigmoid函数)和损失函数(交叉熵损失函数)都源于自然常数。它们的函数性质各有用途:sigmoid函数的输出范围在0和1之间,非常适合用于二分类问题;而交叉熵损失函数的输出范围从0到正无穷,非常适合用作惩罚项。当两者结合时,指数和对数部分巧妙地相互抵消,从而得到一个线性函数,该线性函数因计算简单和良好的数值稳定性而备受青睐。本书的维基页面提供了完整的推导过程。
对于单个样本加法法则 和常数倍法则 得到的:
其中,
梯度(gradient) 是一个包含所有偏导数的向量。损失函数的梯度表示为
如果梯度的某个分量为正,这意味着增加相应的参数将增加损失。因此,为了尽量减少损失,我们应该减小该参数。
梯度下降(gradient descent) 算法使用损失函数的梯度来迭代地更新权重和偏差,目标是最小化损失函数。其操作过程如下。
1)初始化参数: 从参数
2)计算预测值: 对于每个训练样本
3)计算梯度 : 使用式(1.11)计算损失函数关于每个权重
4)更新权重和偏差: 按照减小损失函数的方向调整权重和偏差。这种调整为沿着与梯度相反的方向迈出一小步,其步长由学习率
5)计算损失: 将更新后的权重
6)继续迭代过程: 将步骤2~5重复N 次,N 为设定的迭代次数(也称为步数 ),或者直到损失值收敛到最小值为止。
以下是一些更详细的说明,以帮助你理解这些步骤。
• 做梯度减法的原因 : 因为梯度指向损失函数上升最快的方向,而我们的目标是最小化损失 ,所以要向相反方向移动,这就是要做梯度减法的原因。
• 学习率(learning rate) 的作用 : 学习率超参数(hyperparameter) ,不是由模型学习得到的,而是需要手动设置的。它控制着每次更新的步长,想要找到其最优值,需要进行试验。
• 收敛的判断 : 当后续迭代导致损失值的减少幅度变得微乎其微时,就意味着达到了收敛(convergence) 状态。此时,学习率
让我们用一个包含12个样本的简单数据集来说明这个过程:
在这个数据集中,
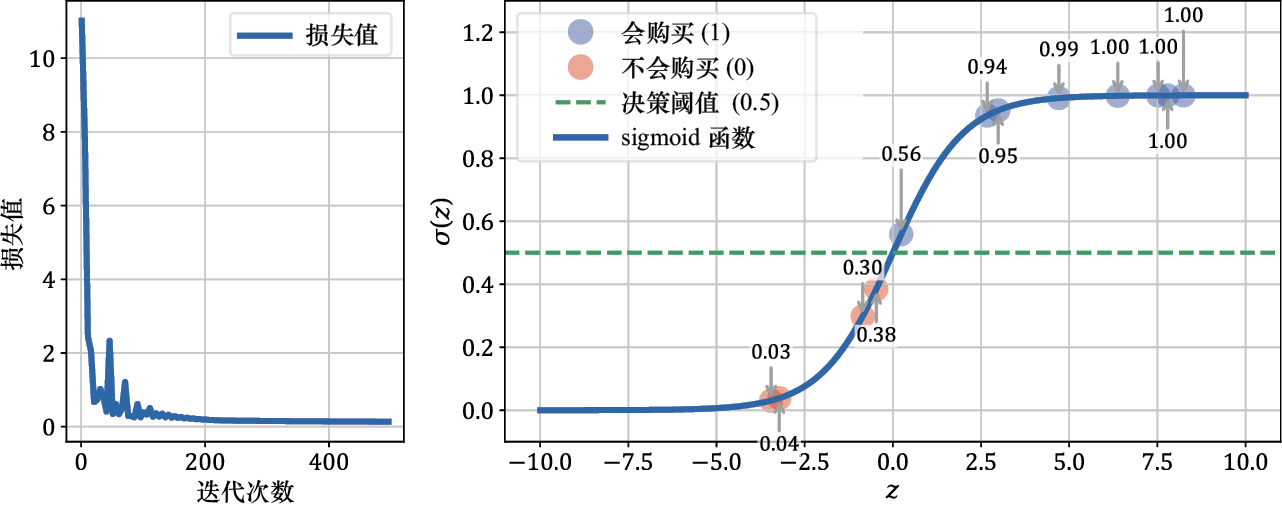
梯度下降步骤中损失值的变化及最终训练好的模型如图1-19所示。
图1-19 损失值变化趋势(左) 及模型训练结果(右)
左侧的图显示了在梯度下降优化迭代的过程中损失值稳步下降的情况。右侧的图展示了经过训练的模型的sigmoid函数,训练样本根据它们的z 值(
选择0.5作为决策阈值是依据了图中明显的分离情况:所有“会购买”的样本(蓝色 点)都位于该阈值上方,而所有“不会购买”的样本(红色 点)都位于其下方。对于新的输入
1.8 自动微分梯度下降用于优化模型参数,但需要使用偏导数方程。到目前为止,我们都是手动为每个模型求导的。然而,随着模型变得越来越复杂,尤其是在多层神经网络中,手动求导变得不切实际。
这就是自动微分(automatic differentiation) 发挥作用的地方,自动微分又叫自动求导(autograd) 。诸如 PyTorch 和 TensorFlow 这样的机器学习框架都内置了这一功能,它可以直接从定义模型的 Python 代码中计算出偏导数。这样就省去了手动求导的过程,即使对于非常复杂的模型也是如此。
现如今自动微分系统能够高效地处理数百万个变量的导数计算。手动计算这些导数是不切实际的,仅仅写出这些方程就可能需要花费数年时间。
要在PyTorch中使用梯度下降,首先需要使用pip3 安装PyTorch,代码如下所示:
$ pip3 install torch 现在已经安装好 PyTorch,接下来让我们导入所需的依赖库:
import torch
import torch.nn as nn
import torch.optim as optim torch.nn 模块包含了用于创建模型的组件。当你使用这些组件时,PyTorch 会自动处理导数计算。对于梯度下降等优化算法,torch.optim 组件就能满足需求。以下是用 PyTorch 实现逻辑斯谛回归的方法:
model = nn.Sequential(
nn.Linear(n_inputs, n_outputs), ➊
nn.Sigmoid() ➋
) 我们的模型利用了PyTorch的顺序API(sequential API) ,它非常适合简单的前馈神经网络,因为数据会在该网络中顺序逐层流动。每一层的输出自然成为下一层的输入。我们将在第2章中使用更通用的模块API(module API ) ,它可以创建具有多个输入、输出或循环结构的模型。
在第➊ 行中,我们使用nn.Linear 定义了输入层。其输入维度n_inputs 与特征向量n_ outputs 则决定了该层的神经元数量。对于我们的“购买/不购买”分类器(即一个为输入分配类别的模型),因为 n_inputs 设置为n_outputs 设置为➋ 行通过Sigmoid 函数对
接下来,我们继续定义数据集、创建模型实例、建立二元交叉熵损失函数,并设置梯度下降算法:
inputs = torch.tensor([
[22 , 25 ], [25 , 35 ], [47 , 80 ], [52 , 95 ], [46 , 82 ], [56 , 90 ],
[23 , 27 ], [30 , 50 ], [40 , 60 ], [39 , 57 ], [53 , 95 ], [48 , 88 ]
], dtype= torch.float32) ➊
labels = torch.tensor([
[0 ], [0 ], [1 ], [1 ], [1 ], [1 ], [0 ], [1 ], [1 ], [0 ], [1 ], [1 ]
], dtype= torch.float32) ➋
model = nn.Sequential(
nn.Linear(inputs.shape[1 ], 1 ),
nn.Sigmoid()
)
optimizer = optim.SGD(model.parameters(), lr= 0.001 ) ➌
criterion = nn.BCELoss() # 二元交叉熵 损失 在上述代码中,我们定义了inputs 和labels 。inputs 构成了一个12行2列的矩阵,而labels 则是一个包含12个分量的向量。inputs 张量的shape 属性会返回其维度信息:
>>>inputs.shape
torch.Size([12,2]) 张量(tensor) 是PyTorch的核心数据结构,是经过优化的多维数组,可以在CPU和GPU上进行高效计算。张量支持自动微分和灵活的数据重塑,是神经网络运算的基础。在上述示例中,inputs 张量包含12个样本,每个样本有两个特征,而labels 张量包含12个样本,每个样本有一个标签。按照标准惯例,样本按行排列,其特征按列排列。
如果你对张量还不太熟悉,那么可以参考本书的维基页面上有关张量的入门教程。
在PyTorch中创建张量时,在第➊ 行中指定dtype=torch.float32, 可以显式设置32位浮点精度。这种精度设置对于神经网络计算(包括权重调整、激活函数计算和梯度计算)至关重要。
32位浮点精度并不是神经网络的唯一选择。量化(quantization)是一种高阶技术,它使用16位或8位浮点数和整数等较低精度的数据类型,有助于减小模型的大小,并提高计算效率。如需了解更多详细信息,请参考本书维基页面上有关模型优化和部署的相关资料。
在第➌ 行中,optim.SGD 类通过接收模型参数列表和学习率作为输入来实现梯度下降。我们的模型继承自 nn.Module ,因此我们可以通过它的 parameters 方法访问所有可训练参数。
PyTorch通过nn.BCELoss() 提供了二元交叉熵 损失函数。
现在,我们已经具备了启动训练循环所需的一切条件:
for step in range(5 00 ):
optimizer.zero_grad() ➊
loss = criterion(model(inputs), labels) ➋
loss.backward() ➌
optimizer.step() ➍ 第 ➋ 行通过将模型的预测值与训练标签进行对比,计算二元交叉熵损失[见式(1.10)]。第 ➌ 行随后利用反向传播来计算该损失相对于模型参数的梯度。
反向传播(backpropagation)算法 应用了微分法则,尤其是链式法则来计算深度复合函数的梯度。该算法构成了神经网络训练的核心。当PyTorch对张量进行操作时,它会构建一个计算图(见图1-12)。这个计算图记录了对张量执行的所有操作。调用loss.backward() 会促使PyTorch遍历这个计算图,并通过链式法则计算梯度,从而无须手动求导和实现梯度计算。
数据通过计算图从输入流向输出的过程构成了正向传播(forward pass) ,而通过反向传播算法从输出到输入计算梯度的过程则对应反向传播(backward pass) 。
PyTorch会将梯度累积到参数(如权重和偏差)的.grad 属性中。虽然这一特性允许在参数更新之前进行多次梯度计算(这对于循环神经网络非常有用,相关内容会在3.3节介绍),但我们的实现并不需要进行梯度累积。因此,第➊ 行代码会在每一步开始时清除梯度。
最后,在第➍ 行中,通过减去学习率与损失函数偏导数的乘积来更新参数值,这就完成了前面讨论的梯度下降算法的第4步。
有些读者可能会感到疑惑:在这个二分类问题中,为什么标签是浮点数而不是整数呢?原因在于PyTorch的BCELoss 函数的运行机制。因为模型的输出层使用了sigmoid激活函数,该函数会产生介于0和1之间的浮点值,所以BCELoss 函数期望预测值和目标标签都是相同范围的浮点数。如果我们使用torch.long 这样的整数类型,就会遇到错误,因为BCELoss 函数并不是为处理整数类型而设计的,它的内部计算需要的是浮点数。这是BCELoss 函数特有的要求,后续会使用的其他损失函数(如CrossEntropyLoss 函数)则要求使用整数标签。
自动微分的一个关键优势在于,其在模型切换时具有很高的灵活性,只要使用的是PyTorch的组件,就可以轻松地在不同架构之间进行切换。例如,你可以用通过顺序API定义的一个简单的两层前馈神经网络来替代逻辑斯谛回归模型:
model = nn.Sequential(
nn.Linear(features.shape[1 ], 1 00 ),
nn.Sigmoid(),
nn.Linear(100 , labels.shape[1 ]),
nn.Sigmoid()
) 在这个设置中,第一层有100个神经元,每一个神经元都包含2个权重和1个偏差,而输出层的单个神经元有100个权重和1个偏差。自动微分系统会在内部处理梯度计算,因此其余代码无须改动。
在第2章中,我们将探讨文本数据的表示和处理方法。我们将从一些基础方法(如词袋模型和词嵌入)入手,它们可以将文档转换为数值格式;之后,我们将介绍统计语言模型。




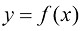 来表示。其中,
来表示。其中,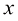 是输入,
是输入,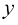 是输出,
是输出,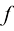 表示
表示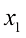 到
到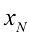 的N个元素的集合表示为
的N个元素的集合表示为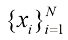 。
。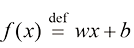 (1.1)
(1.1)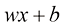 是对
是对 的意思是“根据定义等于”或“被定义为”。
的意思是“根据定义等于”或“被定义为”。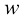 和b。这些值称为该模型的参数(parameter)或权重(weight)。
和b。这些值称为该模型的参数(parameter)或权重(weight)。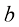 可以称为截距(intercept)、常数项(constant term)或偏差(bias)。在本书中,我们将w称为“权重”,b称为“偏差”,因为这些术语在机器学习中被广泛使用。当含义明确时,“参数”和“权重”可以互换使用。
可以称为截距(intercept)、常数项(constant term)或偏差(bias)。在本书中,我们将w称为“权重”,b称为“偏差”,因为这些术语在机器学习中被广泛使用。当含义明确时,“参数”和“权重”可以互换使用。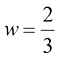 且
且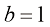 时,该线性函数如图1-3所示。
时,该线性函数如图1-3所示。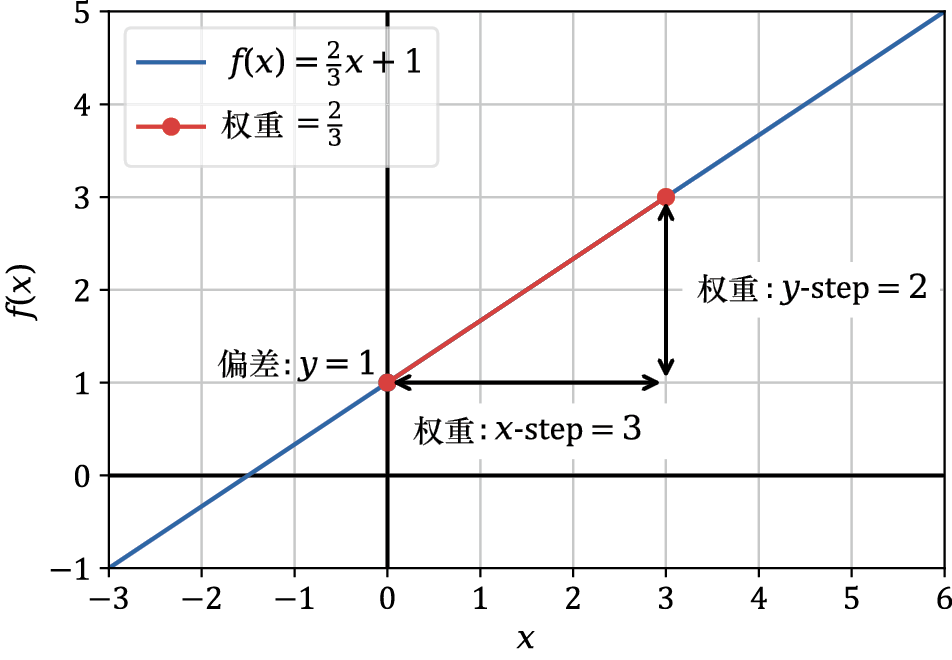
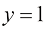 处与
处与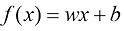 是仿射变换(affine transformation),而不是线性变换,因为真正的线性变换要求
是仿射变换(affine transformation),而不是线性变换,因为真正的线性变换要求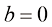 。然而,在机器学习中,只要参数在方程中是线性出现的(意思是
。然而,在机器学习中,只要参数在方程中是线性出现的(意思是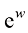 这样的函数内部),我们通常会把这类模型称为“线性模型”。
这样的函数内部),我们通常会把这类模型称为“线性模型”。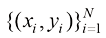 ,其中
,其中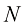 是数据集的大小,
是数据集的大小,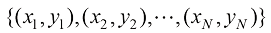 是各个样本,每个
是各个样本,每个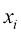 是输入(input),对应的
是输入(input),对应的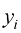 是目标值(target)。当样本既包含输入又包含目标值时,称这种学习过程为监督学习(supervised learning)。本书主要关注有监督机器学习。
是目标值(target)。当样本既包含输入又包含目标值时,称这种学习过程为监督学习(supervised learning)。本书主要关注有监督机器学习。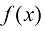 应用于
应用于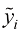 。对于给定样本
。对于给定样本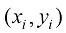 ,我们可以将预测误差
,我们可以将预测误差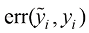 定义为
定义为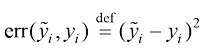 (1.2)
(1.2) 时,其值等于0。这是合理的:如果预测价格与实际价格相匹配,则没有误差。
时,其值等于0。这是合理的:如果预测价格与实际价格相匹配,则没有误差。 和
和 定义为函数
定义为函数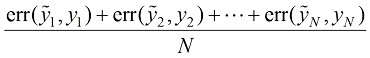

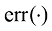 来重写上式:
来重写上式: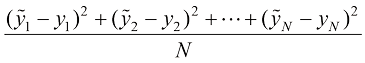
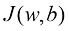 ,将其转化为一个函数,即得到式(1.3):
,将其转化为一个函数,即得到式(1.3):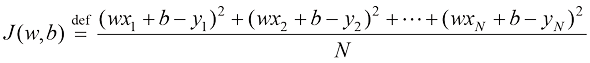
 到
到 ,
,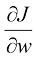 表示关于
表示关于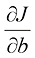 表示关于
表示关于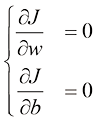
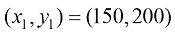 、
、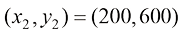 和
和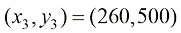 。对于这个数据集,其损失函数为
。对于这个数据集,其损失函数为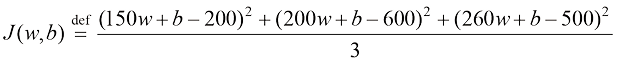
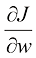 和
和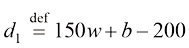 ,
,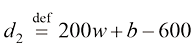 ,
,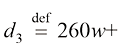
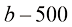 是关于
是关于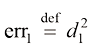 ,
,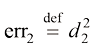 ,
,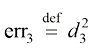 是关于
是关于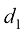 、
、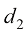 和
和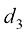 的二次函数;
的二次函数;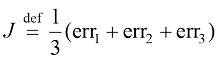 是关于
是关于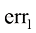 、
、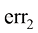 和
和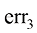 的线性函数。
的线性函数。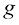 ,首先将函数
,首先将函数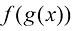 ,意思是首先计算
,意思是首先计算 ,然后将计算结果用作函数
,然后将计算结果用作函数 的值。
的值。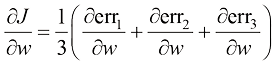
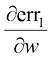 、
、 和
和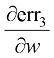 分别是err1、err2和err3关于
分别是err1、err2和err3关于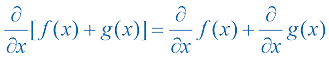 。
。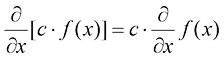 。
。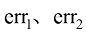 和
和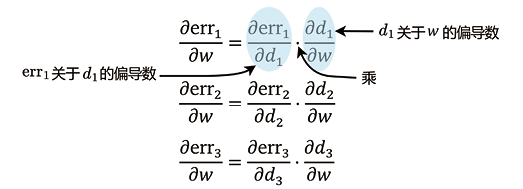
 的导数,记作
的导数,记作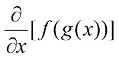 ,是
,是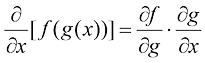 。
。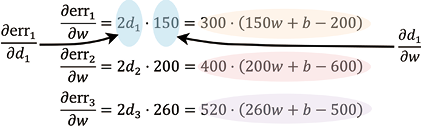
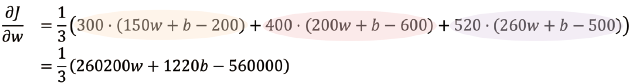
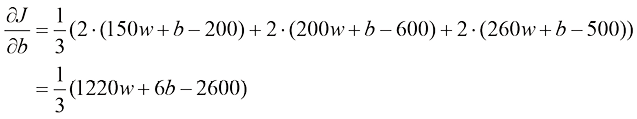
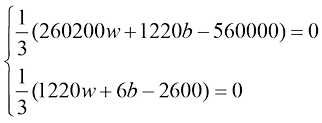
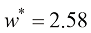 且
且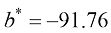 。
。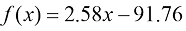 ,如图1-5所示。图中包括3个样本(
,如图1-5所示。图中包括3个样本(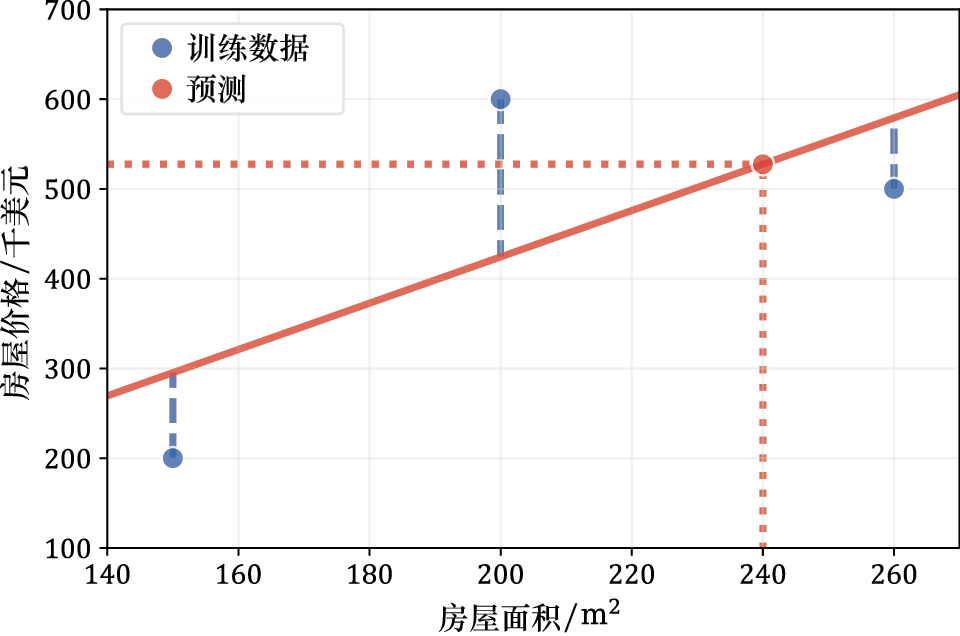
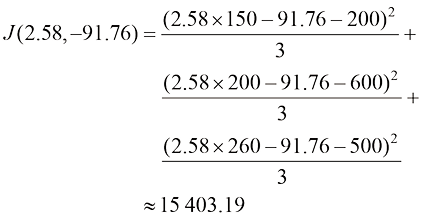
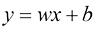 。
。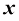 变成一个特征向量(feature vector)。该向量包含两个特征(feature),也称为维度(dimension)或分量(component):
变成一个特征向量(feature vector)。该向量包含两个特征(feature),也称为维度(dimension)或分量(component):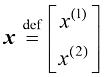
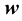 。对于给定的房子
。对于给定的房子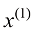 表示其面积(单位:平方米),
表示其面积(单位:平方米), 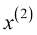 表示卧室的数量。
表示卧室的数量。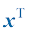 。对列向量进行转置操作会将其转换为行向量(row vector)。例如,
。对列向量进行转置操作会将其转换为行向量(row vector)。例如,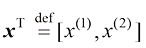 或
或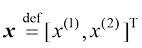 。
。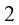 。
。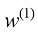 和
和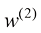 ,以及偏差
,以及偏差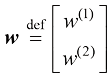
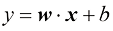 (1.4)
(1.4)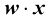 是两个向量的点积(dot product),也称为标量积(scalar product)。其定义如下:
是两个向量的点积(dot product),也称为标量积(scalar product)。其定义如下: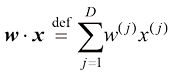
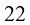 、
、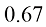 或
或 这样的数。本书中的标量用斜体的小写或大写字母表示,例如
这样的数。本书中的标量用斜体的小写或大写字母表示,例如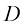 。表达式
。表达式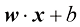 将线性变换(linear transformation)的概念推广到了向量。
将线性变换(linear transformation)的概念推广到了向量。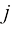 的取值范围则为
的取值范围则为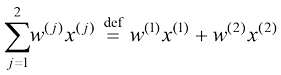 。
。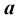 和
和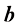 的和定义为
的和定义为
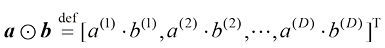
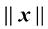 ,表示其长度 (length)或大小(magnitude)。它被定义为该向量的各分量平方和的平方根,即
,表示其长度 (length)或大小(magnitude)。它被定义为该向量的各分量平方和的平方根,即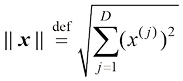
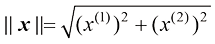
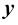 之间夹角
之间夹角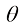 的余弦值定义为
的余弦值定义为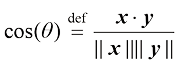 (1.5)
(1.5)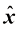 ,需要用该向量除以其范数,这个操作也称为归一化(normalization):
,需要用该向量除以其范数,这个操作也称为归一化(normalization):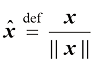
 ;在右边,近乎垂直的向量的夹角余弦值
;在右边,近乎垂直的向量的夹角余弦值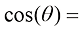
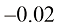 。
。
 ,由线性函数组合成的复合函数仍然是线性的。这一点很容易验证。
,由线性函数组合成的复合函数仍然是线性的。这一点很容易验证。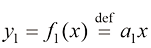 和
和 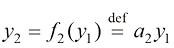 。在这里,
。在这里,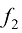 依赖于
依赖于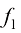 ,这样就使它成为一个复合函数。我们可以将
,这样就使它成为一个复合函数。我们可以将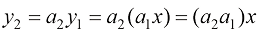
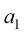 和
和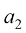 是常数,我们可以定义
是常数,我们可以定义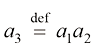 ,因此
,因此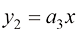 ,显而易见,这个方程仍然是线性的。
,显而易见,这个方程仍然是线性的。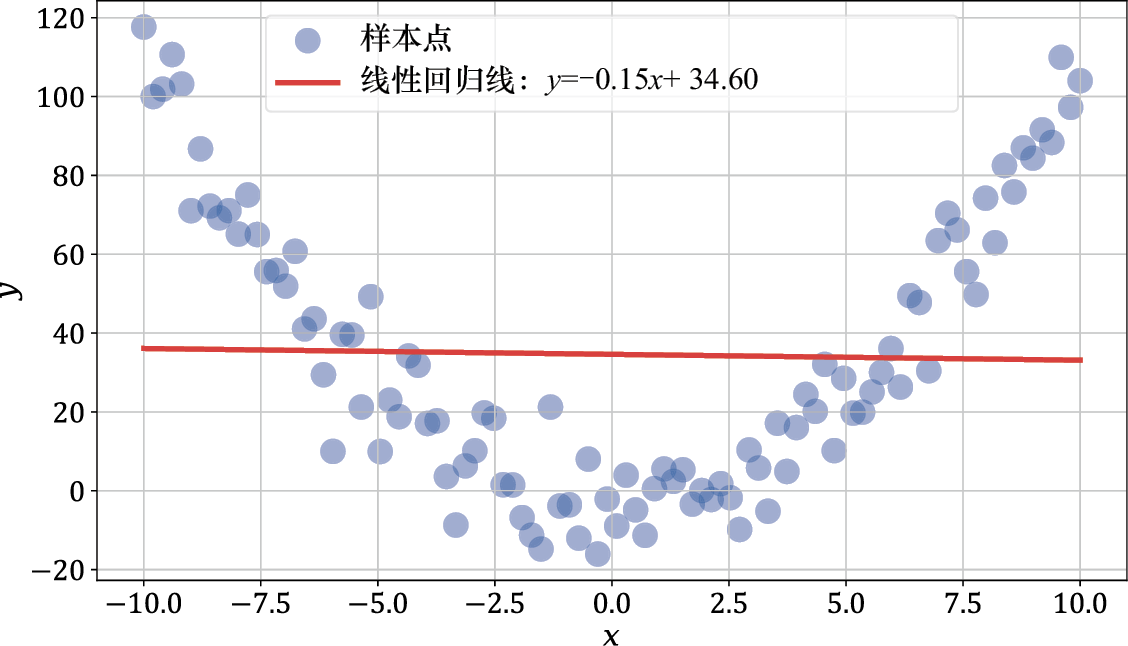
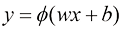
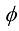 是一个固定的非线性函数,称为激活(activation)函数。常见的选择如下。
是一个固定的非线性函数,称为激活(activation)函数。常见的选择如下。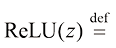
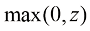 ,它输出非负值,在神经网络中使用广泛。
,它输出非负值,在神经网络中使用广泛。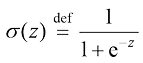 ,输出值介于
,输出值介于 和
和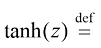
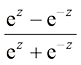 ,输出值介于
,输出值介于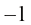 和
和 表示自然常数(即欧拉数,Euler’s number),其值约为
表示自然常数(即欧拉数,Euler’s number),其值约为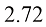 。
。
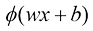 这种结构能够实现对非线性模型的学习,但无法拟合所有非线性曲线。通过嵌套这些函数,我们可以构建更具表现力的模型。例如,设
这种结构能够实现对非线性模型的学习,但无法拟合所有非线性曲线。通过嵌套这些函数,我们可以构建更具表现力的模型。例如,设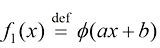 和
和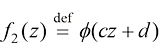 ,将
,将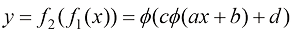
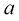 和
和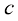 和
和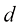 进行线性变换,接着再次应用
进行线性变换,接着再次应用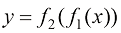 的图形表示。
的图形表示。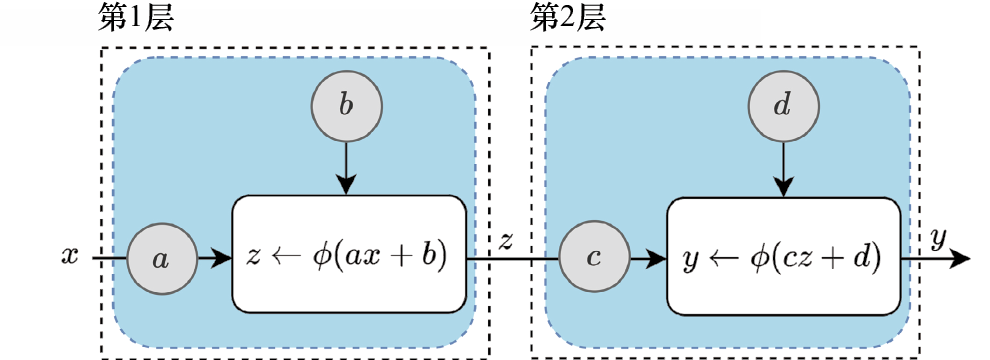
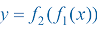 示意图
示意图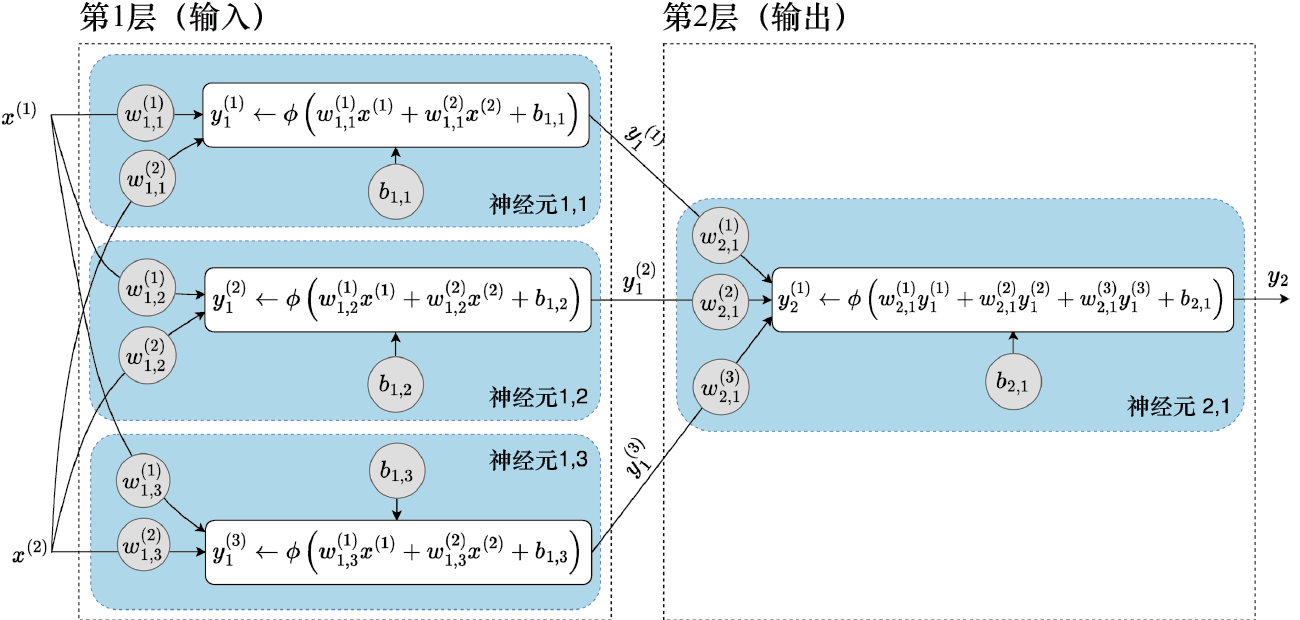
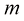 行
行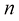 列的矩阵
列的矩阵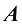 可以表示为
可以表示为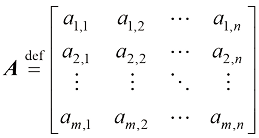
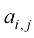 表示矩阵第
表示矩阵第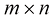 (读作“m乘以n”)。
(读作“m乘以n”)。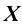 或
或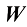 。
。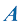 和
和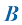 相加,其和是逐元素定义的:
相加,其和是逐元素定义的: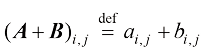
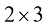 的矩阵
的矩阵 ,它们的加法运算如图1-15所示。
,它们的加法运算如图1-15所示。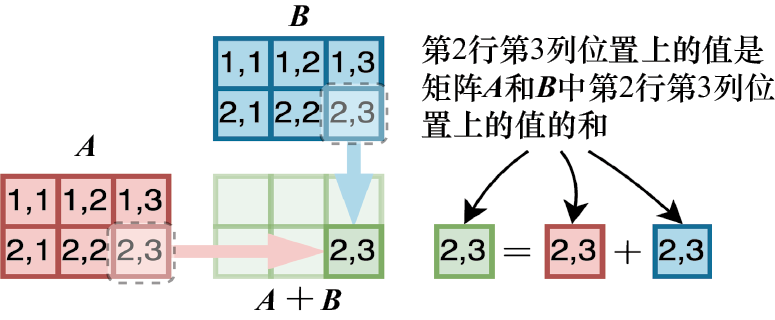
 的矩阵
的矩阵 的矩阵
的矩阵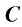 ,其中第
,其中第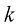 列的值由下式给出:
列的值由下式给出: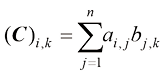
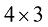 的矩阵
的矩阵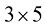 的矩阵
的矩阵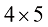 的矩阵,如图1-16所示。
的矩阵,如图1-16所示。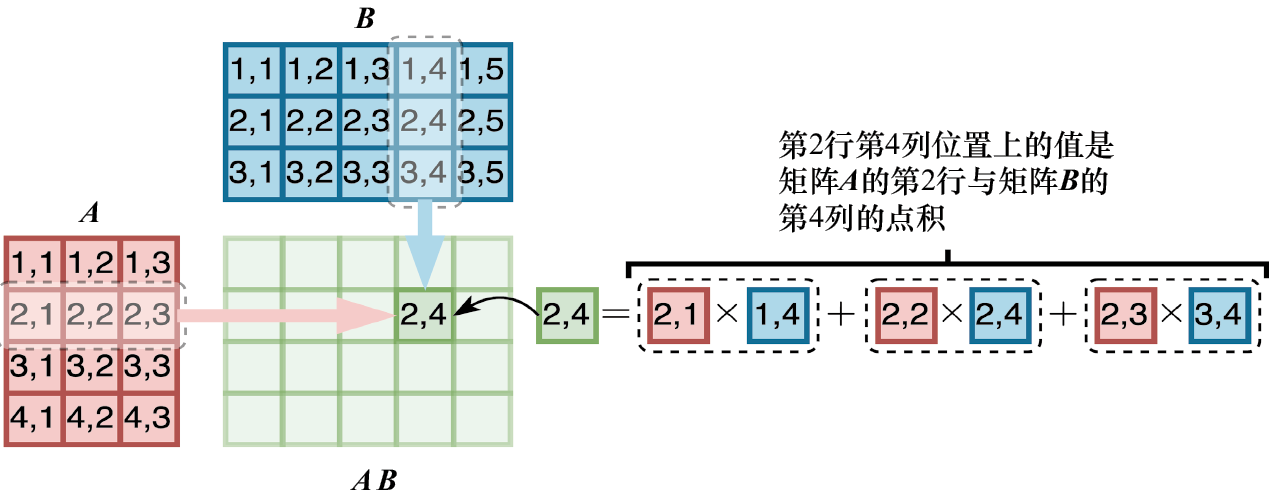
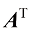 ,其中:
,其中: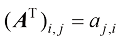
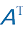
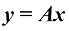 。所得的结果向量
。所得的结果向量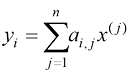
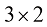 的矩阵
的矩阵 和一个三维向量
和一个三维向量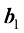 来表示。第一层的三维输出
来表示。第一层的三维输出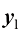 由式(1.6)给出:
由式(1.6)给出: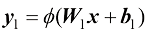 (1.6)
(1.6) 是通过第一层的输出
是通过第一层的输出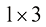 的矩阵
的矩阵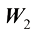 。第二层的偏差是一个标量
。第二层的偏差是一个标量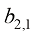 。该模型的输出就对应第二层的输出:
。该模型的输出就对应第二层的输出: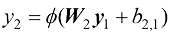 (1.7)
(1.7)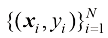 ,其中
,其中 是输入的特征向量,而
是输入的特征向量,而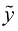 ;而对于非垃圾邮件输入,则应该输出接近
;而对于非垃圾邮件输入,则应该输出接近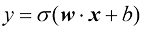 (1.8)
(1.8)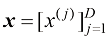 和
和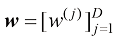 是
是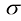 是1.5节中定义的sigmoid函数。
是1.5节中定义的sigmoid函数。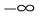 到
到 ,而逻辑斯谛回归的输出值始终在
,而逻辑斯谛回归的输出值始终在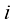 ,二元交叉熵损失定义如下:
,二元交叉熵损失定义如下: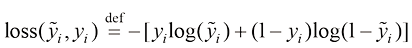 (1.9)
(1.9)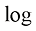 表示自然对数(natural logarithm)。
表示自然对数(natural logarithm)。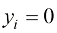 且
且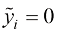 时:
时: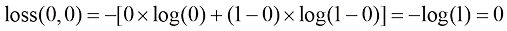
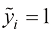 时:
时: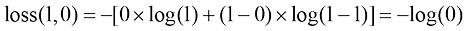
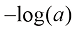 趋近于无穷大,这意味着对于完全错误的预测会产生非常大的损失。然而,因为
趋近于无穷大,这意味着对于完全错误的预测会产生非常大的损失。然而,因为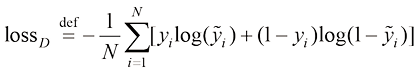 (1.10)
(1.10)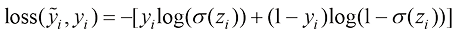 ,其中
,其中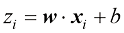
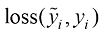 ,我们需要计算关于每个权重
,我们需要计算关于每个权重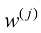 和偏差
和偏差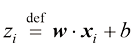 ,这是一个包含权重
,这是一个包含权重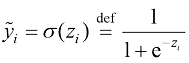 ,即对
,即对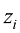 应用sigmoid函数。
应用sigmoid函数。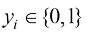 是该样本的标签。符号
是该样本的标签。符号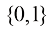 ,在这种情况下,意味着
,在这种情况下,意味着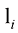 。对于权重
。对于权重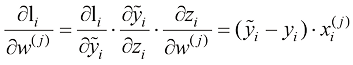
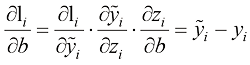
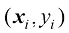 ,关于参数
,关于参数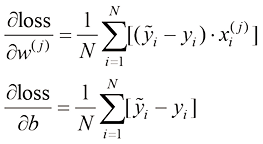 (1.11)
(1.11) 表示整个数据集的平均损失。对各个样本的损失进行平均,可以确保每个样本对总损失的贡献是均等的,而与样本总数无关。
表示整个数据集的平均损失。对各个样本的损失进行平均,可以确保每个样本对总损失的贡献是均等的,而与样本总数无关。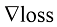 ,定义如下:
,定义如下: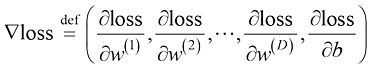
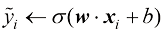
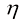 (下面会解释)控制:
(下面会解释)控制: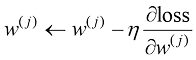
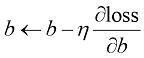
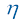 的作用:学习率
的作用:学习率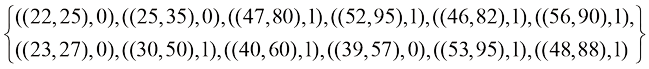
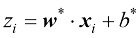 )进行定位,其中
)进行定位,其中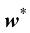 和
和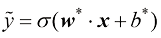 。如果
。如果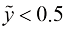 ,则预测该新样本为“不会购买”,否则预测为“会购买”。
,则预测该新样本为“不会购买”,否则预测为“会购买”。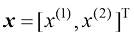 ,所以我们将
,所以我们将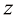 是标量,所以将
是标量,所以将




