版权信息 书名:模式识别与机器学习
ISBN:978-7-115-68140-9
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
版 权 著 [英]克里斯托弗·M.毕晓普(Christopher M.Bishop)
译 陈 翔 张存旺 姜振东 刘志毅 许劭华
责任编辑 郭泳泽
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线: (010)81055410
反盗版热线: (010)81055315
版 权 声 明 First published in English under the title
Pattern Recognition and Machine Learning , edition: 1
by Christopher M. Bishop
Copyright © Springer-Verlag New York, 2006
This edition has been translated and published under licence from
Springer Science+Business Media, LLC, part of Springer Nature.
本书中文简体字版由Springer Nature授权人民邮电出版社出版。未经出版者书面许可,对本书任何部分不得以任何方式复制或抄袭。
版权所有,侵权必究。
内 容 提 要 本书深入而系统地介绍了模式识别和机器学习领域的基本概念、数学原理和核心算法,并附有丰富的习题。作为机器学习领域的“圣经”,本书融合了概率论、统计学、线性代数和优化理论,构建了从基础概念到前沿技术的完整知识体系,内容涵盖决策论、概率分布、线性回归模型、线性分类模型、神经网络、核方法、稀疏核机、图模型、混合模型与最大期望算法、近似推断、采样方法、连续潜变量、序列数据、模型组合等。
本书适合计算机专业高年级本科生和低年级硕士生阅读,也适合作为机器学习从业人员和爱好者的参考资料。
译 者 简 介 刘志毅
上海市人工智能社会治理协同创新中心研究员,在AI领域深入研究和实践十余年,涉及智能计算、空间智能以及超级人工智能对齐方向。中国人工智能学会人工智能伦理与治理工作委员会委员及具身智能专业委员会(筹)委员,上海交通大学计算法学与AI伦理研究中心执行主任,上海交通大学安泰经济与管理学院AI与营销研究中心特聘研究员,上海交通大学清源研究院兼职研究员,上海开源信息技术协会AI伦理与治理专业委员会主任,2024 年入选福布斯中国“十大人工智能影响力人物”。国际电工委员会生物数字融合系统评估组(IEC/SMB/SEG12)伦理专家,国家人工智能标准化总体组专家,中国人工智能产业发展联盟可信AI专家委员会委员,上海市人工智能技术协会专家委员会委员。出版《智能经济》《数字经济学》《智能的启蒙:通用人工智能与意识机器》等十几部中英文专著,翻译多部海外学者专著,作品入围Springer Nature“中国新发展奖”(2023年度)。
许劭华
上海人工智能实验室生态总监,曾担任头部AI企业战略及生态总监、普通高等院校“十三五”人工智能系列规划教材编委会执行委员及副组长、人工智能关键技术和应用评测工业和信息化部重点实验室学术委员会成员。牵头联合多家企业制定人工智能产业人才标准,并推动高校人工智能专业产教融合 项目。
陈 翔
沙特阿卜杜拉国王科技大学统计学专业博士研究生,目前从事空间统计、时间序列分析与人工智能在公共卫生领域的应用研究,重点关注传染病的预测建模与空间分析。在攻读博士学位前,就读于哈尔滨工业大学,获得计算机科学与技术工学学士和工学硕士学位,研究方向为自动机器学习与可解释人工智能;并辅修大数据管理与应用,获得管理学学士学位。曾在Pattern Recognition 、IEEE TKDE 、CVPR、ICDE、HCI等国际期刊与会议上发表多篇论文。曾于微软亚洲研究院实习。知识类视频创作者,讲解数学类课程与外语类课程,累计总播放量超过800万。
张存旺
北京航空航天大学计算机专业博士研究生,研究方向聚焦知识图谱、信息抽取与问答检索,深耕自然语言处理领域8年。本科和硕士均就读于北京航空航天大学,其间系统学习机器学习理论算法,主要研究方向为概率论、图模型、推理推断等。曾在OPPO研究院北京研究所以及北京航空航天大学杭州创新研究院任自然语言处理算法工程师,其间主导或参与近20个实际落地项目,覆盖垂直领域的知识抽取、知识管理、知识检索以及知识问答等方向。
姜振东
北京大学计算机硕士,现任某头部金融央企金融科技专家、数据工程平台负责人,主持完成“大型金融企业DataOps创新实践”等重点课题项目。长期致力于人工智能与数据科学领域的技术研发与应用。参与编撰或翻译《Java核心编程》《人在回路机器学习》《银行数字化转型之路》《人机共舞:AIGC时代的工作变革》《翻译技术教程》等十余部科技类专著。深度参与全国数据标准化技术委员会(SAC/TC609)、中国通信标准化协会大数据技术标准推进委员会(CCSA TC601)多项标准、白皮书的拟制修订工作。拥有多项国家专利,在国内外专业会议与期刊发表多篇学术论文。
主要审校人简介 邹大伟
绥化学院信息工程学院应用数学教研室教师,硕士毕业于西安电子科技大学,从2015年起转向机器学习理论与应用方面的研究,发表机器学习算法的SCI检索论文多篇,拥有发明专利2项。
周允成
复旦大学大数据学院博士研究生。专注于基于深度学习的医学影像分析研究,主要研究领域为多模态影像配准和计算机视觉。
项亦子
《数据分析简史》作者,毕业于上海海洋大学信息与计算科学专业,毕业后长期从事数据分析领域的工作,擅长领域为统计学、数据分析和机器学习。
侯宇清
2016年博士毕业于北京大学信息科学技术学院智能科学系,2017~2019年于清华大学计算机科学与技术系博士后流动站从事研究工作,专注于深度学习和强化学习的研究与应用。在视觉信息处理、信息检索和信息推送等领域发表多篇国际顶级会议论文。
倪嘉琦
上海交通大学软件工程硕士,中国计算机学会(CCF)专业会员,谷歌开发者社区成员。自2016年起深耕大数据开发,主导过多个离线数据仓库设计与实时计算开发项目,擅长数据管道构建、实时分析引擎优化及大规模集群运维。持续关注大数据生态前沿技术理念,致力于推动行业解决方案的技术落地与应用创新。
唐 昕
数据库、大数据与人工智能技术专家、产品负责人,拥有十余年国际化数据管理与AI技术创新、产品孵化与规模上市经验。CCF A类数据工程国际学术会议审稿人,深度参与行业标准与白皮书编制。
译 者 序 在人工智能研究的版图中,模式识别、机器学习是两大核心支柱:前者源于工程领域对从数据中提取规律的需求,后者脱胎于计算机科学对算法自主学习能力的探索。二者虽同源同宗,却缺乏一部能以统一理论框架贯通其精髓的著作。直到本书问世,这一局面才被打破。
本书具有很强的独特性与开创性。
第一,它以贝叶斯视角诠释模式识别。在贝叶斯方法从小众专精领域迈向机器学习主流范式的关键时期(21世纪初,贝叶斯理念在不确定性建模、概率推断中的优势逐渐被学界广泛认知),本书为其提供了完整的教材化呈现。
第二,它将图模型与机器学习深度融合。图模型以直观的图结构描述概率分布的依赖关系,为复杂系统建模提供了有力工具,在本书出版前,鲜有教材将其全面引入机器学习领域。
第三,它还系统阐述了近似推断算法,解决了“复杂模型下精确推断不可行时如何快速获取近似解”的核心问题,为理论落地于实际应用扫清了障碍。
正因如此,本书自出版以来,迅速成为全球高校机器学习、模式识别等课程的核心教材,也成为科研人员与工程实践者的案头必备参考书,被誉为机器学习“圣经”。
核心内容 本书包含14章正文与5个附录,内容覆盖模式识别与机器学习的核心理论、方法及应用,且始终以贝叶斯概率视角及概率建模与推断为核心线索,将分散的方法统一于严谨的理论框架下。
第1章以“多项式曲线拟合”这一直观示例,展现模型复杂度与泛化能力的权衡这一机器学习核心矛盾,同时引入概率论、决策论、信息论等基本概念,为全书奠定以概率为核心的建模与推断的基调。
第2章系统讲解二元变量、多项式变量、高斯分布、指数族分布等基础概率分布,以及非参数方法。对高斯混合模型的介绍与第9章形成呼应。
第3章聚焦于回归任务的概率建模,从线性基函数模型出发,将最大似然估计与最小二乘法紧密结合;通过最小二乘解的几何解释,直观展现参数估计的几何意义;引入正则化最小二乘法,解决过拟合问题;更重要的是,从贝叶斯视角重新审视线性回归,提出贝叶斯线性回归模型,引入参数分布、预测分布、等效核等概念,体现了贝叶斯方法“量化不确定性”的核心优势;对模型证据与参数复杂度的讨论,则为模型选择提供了贝叶斯范式下的解决方案。
第4章聚焦于分类任务的概率建模,涵盖判别函数与概率生成式模型;以逻辑斯谛回归为例,从最大似然解、拉普拉斯近似到贝叶斯逻辑斯谛回归,层层深入;多分类逻辑斯谛回归、概率回归的规范连接函数等内容拓展了线性模型的适用范围;模型比较与贝叶斯信息准则则为分类模型的选择提供了理论依据。
第5章系统讲解前馈神经网络的函数表示、训练方法、正则化,以及贝叶斯神经网络;混合密度网络则展示了神经网络在条件密度估计这类复杂任务中的应用,体现了其强大的表达能力。
第6章基于对偶表示思想,实现通过高维特征空间隐式映射完成非线性建模;讲解核函数的构造、径向基函数网络、高斯过程等内容。对于高斯过程,从线性回归的再探讨到用于回归问题的高斯过程,再到学习超参数、用于分类问题的高斯过程,展现了核方法的优雅性与普适性。
第7章聚焦于模型稀疏性与计算效率,讲解支持向量机、相关向量机。
第8章是本书的一大亮点:系统地引入图模型。多项式回归的贝叶斯网络示例、图像去噪的马尔可夫随机场应用示例等,让读者直观感受图模型“以图结构描述变量依赖关系,简化复杂系统建模与推断”的优势,这些内容也为第10章奠定了 基础。
第9章聚焦于含潜变量模型的参数估计,从K均值算法出发,过渡到高斯混合模型;从用于高斯混合模型的EM算法到另一视角下的EM算法,再到贝叶斯线性回归中的EM算法,展现了EM算法在生成式模型中的普适性。
第10章聚焦于复杂模型的高效推断,核心方法包括变分推断与期望传播。变分推断通过优化变分分布以近似后验分布,解决了复杂模型的推断难题。变分高斯混合模型、变分线性回归、变分逻辑斯谛回归等内容,展示了变分方法的广泛应用;期望传播则通过消息传递实现近似推断,与图模型的推断算法形成互补。
第11章讲解马尔可夫链蒙特卡洛采样及其衍生算法,包括Metropolis-Hastings算法、吉布斯采样、切片采样、混合蒙特卡洛算法等。该章不仅阐述算法原理,还分析不同采样算法的适用场景与效率,让读者掌握从复杂分布中生成样本的核心技术;采样与EM算法则体现了采样方法在参数估计中的应用。
第12章聚焦于降维与流形,讲解主成分分析(PCA)及其概率拓展。从PCA的最大方差表述到概率PCA,再到贝叶斯PCA,展现了从确定性方法到概率方法,再到贝叶斯方法的演变。
第13章讲解马尔可夫模型、隐马尔可夫模型(HMM)、线性动态系统(LDS)等。该章从前后向算法、最大似然估计到维特比算法,展现了HMM在序列标注、语音识别等任务中的应用;LDS则将HMM拓展到连续型观测数据,为时序数据的滤波与预测提供了方法。
第14章讲解模型组合策略,包括贝叶斯模型平均法、决策树、“委员会”、条件混合模型等。这些内容为解决单一模型无法拟合复杂数据的问题提供了思路。
附录A~附录E为读者提供了用于实践的数据集、常用概率分布,以及一些数学公式的讲解,方便读者在学习理论时同步开展实践与推导。
翻译过程 本书的翻译由一支跨学科团队完成,译者来自计算机科学、应用数学、电子工程等领域,既具备机器学习的研究背景,又有丰富的科技图书翻译经验。翻译过程中,我们始终以“准确传递学术内涵,流畅呈现中文表达”为核心原则。原著语言严谨且略带学术性,翻译时在保持学术严谨性的同时,力求中文表述的流畅与易懂。
分工方面,姜振东翻译了前言、第1~2章、附录A~B,陈翔翻译了第3~5章、第11章、附录C、附录E,许劭华翻译了第6章、第14章,刘志毅翻译了第7章、第12~13章,张存旺翻译了第8~10章、附录D。
我们在翻译过程中倾注了大量的心血。对于数学推导、算法步骤,我们逐行核对公式符号、下标、运算顺序与文字描述,确保翻译不会导致理解偏差。例如,书中涉及大量有关矩阵运算的内容,我们会反复验证符号的准确性,保证数学推导的正确性。
翻译初稿完成后,团队进行了多轮交叉校对,重点关注章节间术语的一致性、理论阐述与实例分析的匹配性;随后,邀请领域内专家对译稿进行审读,根据专家意见进一步修订,确保译文的学术性、可读性和准确性。
如何高效学习本书 为帮助读者更好地利用本书开展学习与研究,我们结合内容特点与翻译体验,提出以下建议。
重视习题与实践。书中习题不仅是理论巩固,更是科研思维训练。建议读者尝试独立完成习题,对于涉及编程的习题,可结合Python、MATLAB等工具开展实践——通过动手实现,读者将能够更深刻地理解算法的细节,也能更早体会“理论到工程”的转化过程。
充分利用附录与外部资源。将附录作为“速查手册”,同时结合本书配套资源提供的额外资料辅助学习——尤其是高校教师或准备开设相关课程的读者,本书配套资源能为教学提供有力支持。
借助已有知识加速理解。例如,对于有物理学、工程学背景的读者,可重点关注贝叶斯方法与统计物理的联系、模式识别与信号处理的关联,借助自身已有知识体系加速理解;对于有计算机科学背景的读者,可重点关注算法的复杂度分析、工程实现的技巧。
结语 本书的翻译出版,为国内读者提供了一本兼具理论深度与实践指导的重磅之作。在人工智能浪潮席卷全球的当下,模式识别与机器学习是人工智能的核心基石,而本书所阐释的贝叶斯概率视角、图模型思维、近似推断技术,正是理解复杂智能系统、开展原创性研究的关键。
我们要特别感谢国内多所高校的机器学习专家对译稿的审读和建议。他们的专业意见对提升译文质量功不可没。同时,出版社编辑团队的鼎力支持也使得这本书能够以如此出色的状态呈现给中文读者。由于翻译水平有限,译文中若存在疏漏或不当之处,恳请读者不吝指正,以便我们在后续版本中持续完善。
我们期待本书能成为国内高校相关课程的核心教材,为培养跨学科AI人才提供支撑;同时也期待本书能成为科研人员与工程实践者的案头参考书,助力我国在模式识别与机器学习领域的研究与应用迈向新的高度。
刘志毅
2025年9月于上海
对本书的赞誉 这本书的一大特色是运用了几何图示并做了直观解读……这是一本兼具深度与趣味性的佳作,可作为多门高级统计学课程的核心教材,也非常适合读书小组选用。
John Maindonald,Journal of Statistical Software
作者Bishop阐释了众多已被纳入“模式识别”或“机器学习”范畴的统计技术……这本书将成为一份出色的参考资料……凭借连贯的视角、精准全面的内容覆盖以及清晰易懂的讲解,Bishop的这本书不仅是该领域的优质入门读物,也是读者了解该领域核心技术的宝贵参考。
Radford M. Neal,Technometrics , Vol. 49 (3), 2007
这本书隶属Springer公司的“信息科学与统计学系列丛书”……其定位虽偏向课堂教学,但显然也包含适合自学者的内容,整体结构设计便于自学……为授课教师提供了充足支持,包括约400道习题……书中涵盖的重要内容易于理解,读者无须局限于预设的学习课程即可掌握。
W. R. Howard,Kybernetes , Vol. 36 (2), 2007
微软研究院的Bishop撰写了这本出色的著作,以几百页的篇幅全面介绍了模式识别与机器学习领域。总结:强烈推荐。
C. Tappert,CHOICE , Vol. 44 (9), 2007
这本书包含14章和5个附录……非常适合作为机器学习、统计学、计算机科学、信号处理、计算机视觉、数据挖掘与生物信息学等课程的教材。同时为授课教师提供了丰富支持,包括400多道习题、授课幻灯片,以及可从这本书的资源网站获取的大量补充材料……
Ingmar Randvee,Zentralblatt MATH , Vol. 1107 (9), 2007
Bishop的这本书是其此前著作Neural Networks for Pattern Recognition 的精彩延伸……总而言之,这本书是模式识别与机器学习(从参数估计角度而言)的优秀入门读物,大量极具启发性的插图更增添了其价值。
H. G. Feichtinger,Monatshefte für Mathematik , Vol. 151 (3), 2007
这本书对现代模式识别与机器学习技术进行了清晰、直观的解读,并诠释了难度适宜的技术细节。这本书既可用于课程教学、自学,也可作为参考资料……我向读者强烈推荐这本书,有必要指出的是,Neal在2007年也对这本书给出了高度评价。
Thomas Burr,Journal of the American Statistical Association , Vol. 103 (482), 2008
这本易懂的著作旨在全面介绍模式识别与机器学习领域,对经典的统计模式识别技术进行了系统性阐述……各章末尾的习题十分实用……书中包含多个新颖视角、研究进展与成果,无论是机器学习领域的研究人员还是学生,都能从中受益。
L. State,ACM Computing Reviews , 2008
Bishop的技术阐述兼具清晰性与数学严谨性……在几百页条理清晰、插图丰富的内容中,他构建了一个统一的统计框架,涵盖了模式识别与机器学习领域的方方面面。这本书可作为教材,包含各类习题和提供给教师的完整解题思路获取指引,以及精彩的彩色插图……这本书的清晰性与全面性将使其成为数据分析师的常用桌面参考书。
H. Van Dyke Parunak,ACM Computing Reviews , Vol. 49 (3), 2008
谨以此书献给我的家人:詹娜、马克和休。
2006年3月29日作者一家在土耳其安塔利亚的海滩上观看日全食
前 言 模式识别起源于工程学,机器学习则发轫于计算机科学。然而,它们可以看作同一领域的两个方面,在过去30多年携手经历了长足发展。特别地,贝叶斯方法已经从一个专业小众领域发展为主流方法论,而图模型则已成为描述和应用概率模型的通用框架。此外,通过一系列近似推断算法(如变分贝叶斯和期望传播算法)的发展,贝叶斯方法的实用性已获极大增强。同样,基于核函数的新模型也对算法和应用产生了重要影响。
本书反映了这些最新进展,同时全面介绍了模式识别和机器学习领域。本书面向计算机专业高年级本科生和低年级硕士生,以及机器学习研究人员和从业者,但不要求读者具有模式识别和机器学习背景知识。读者需要具备多元微积分和基础线性代数的知识,对概率论有一定了解会对阅读本书有帮助但非必需,本书包含完整的基础概率论介绍。
本书由于内容广泛,无法提供完整的参考文献列表和观点的准确历史出处。本书转而致力于提供比书中内容更翔实的参考文献,希望这些文献能成为读者涉足文献海洋的切入点。因此,书中所列参考文献通常为近年来的教科书和综述文章,而非原始资料。
本书还附有大量补充材料,包括讲座幻灯片和书中使用的全套图集,我们鼓励读者搜索本书资源网站以获取最新信息。
习题 每章末尾的习题是本书的重要组成部分。每道习题都经过精心挑选,旨在巩固读者对文中已解释概念的理解,或以重要的方式对这些概念进行发展和概括。每道习题按难度分级,从只需几分钟就能完成的一星级(*)到相当复杂的三星级(***)不等。
要明确应在多大程度上提供习题解答并不容易。自学者会认为题解对他们非常有益,而众多授课教师则希望仅通过出版商渠道提供解答,以便在课堂上使用这些习题。为了尽量满足这些需求,针对那些有助于强调学习重点或填补重要细节的习题,其解答可从本书资源网站上以PDF文件形式获取。此类习题用
尽管本书侧重于概念和原理,但在课堂教学中,学生最好有机会使用适当的数据集对一些关键算法展开实验。与本书配套的姊妹篇(Bishop and Nabney,2008)涉及模式识别和机器学习的实践方面,并附有本书讨论的大多数算法的MATLAB软件实现。
致谢 首先,我要衷心感谢Markus Svensen,他在插图准备和使用LaTeX为本书排版方面提供了巨大且无价的帮助。
我非常感谢微软研究院为我提供了一个高度激发思维的研究环境,并给予我撰写本书的自由(然而,本书表达的观点和意见仅代表我个人,因此不一定与微软或其附属机构保持一致)。
Springer公司在本书编写的最后阶段提供了出色的支持,我要感谢策划编辑John Kimmel的支持和专业精神,Joseph Piliero在设计封面与文本格式方面的帮助,以及MaryAnn Brickner在制作阶段的诸多贡献。封面设计的灵感来自与Antonio Criminisi的一次讨论。
我还要感谢牛津大学出版社允许我摘录早期教科书Neural Networks for Pattern Recognition (Bishop, 1995a)。MarkⅠ感知机的图像和Frank Rosenblatt的图像是经Arvin/Calspan先进技术中心许可转载的。我还要感谢Asela Gunawardana绘制了图13.1中的谱图,以及Bernhard Scholkopf允许我使用他的核PCA代码绘制图12.17。
衷心感谢许多人士审查了各章初稿并提供了宝贵的反馈意见,特别感谢Shivani Agarwal、Cedric Archambeau、Arik Azran、Andrew Blake、Hakan Cevikalp、Michael Fourman、Brendan Frey、Zoubin Ghahramani、Thore Graepel、Katherine Heller、Ralf Herbrich、Geoffrey Hinton、Adam Johansen、Matthew Johnson、Michael Jordan、Eva Kalyvianaki、Anitha Kannan、Julia Lasserre、David Liu、Tom Minka、Ian Nabney、Tonatiuh Pena、Yuan Qi、Sam Roweis、Balaji Sanjiya、Toby Sharp、Ana Costa e Silva、David Spiegelhalter、Jay Stokes、Tara Symeonides、Martin Szummer、Marshall Tappen、Ilkay Ulusoy、Chris Williams、John Winn和Andrew Zisserman。
最后,我要感谢我的妻子詹娜在我撰写本书的日子里给予我极大的支持。
Chris Bishop
英国剑桥
2006年2月
数 学 符 号 我力求将本书的数学内容保持在充分理解本书所涉领域所需的最低水平。然而,这并不代表本书对读者的数学水平没有要求。必须强调的是,要清晰理解现代模式识别和机器学习技术,就必须掌握微积分、线性代数和概率论。尽管如此,本书的重点在于传授基本概念,而非聚焦于数学严谨性。
我努力在全书中保持一致的符号表示,尽管有时这意味着与相应研究文献中使用的一些惯例有些不同。向量用小写粗斜体罗马字母表示,如x T ”表示矩阵或向量的转置,因此x T 表示行向量。大写粗斜体罗马字母(如M w 1 , …, w M M 个元素的行向量,而相应的列向量记作w w 1 , …, w M T 。
符号[a , b ]表示从a 到b 的闭区间,包含a 和b ;而符号(a , b )表示相应的开区间,不包含a 和b 。类似地,[a , b )表示一个包含a 但不包含b 的前闭后开区间。然而,在大多数情况下,几乎不必深入讨论区间端点是否包含在内这一细微差别。
M ×M 的单位矩阵记作I M I I ij i = j 时等于1,当i ≠j 时等于0。
泛函记作f [y ],其中y (x )是一个函数。关于泛函的概念见附录D。
符号g (x ) = O ( f (x ))表示当x →∞时,| f (x )/g (x )|有界。例如,如果g (x ) = 3x 2 + 2,则g (x ) = O (x 2 )。
函数f (x , y )关于随机变量x 的期望记作x f (x , y )]。在对变量求平均值无歧义的情况下,可以省略后缀,例如x ]。如果x 的分布以另一变量z 为条件,则相应的条件期望记作x f (x )|z ]。同样,方差记作var[f (x )],对于向量变量,协方差记作cov[x y x x x
如果有D 维向量x x 1 , … , x D T 的N 个值x 1 , …, x N X X n 行对应于行向量X n 行第i 列元素对应于第n 个观测x n i 个元素。对于一维变量,我们将这样的矩阵表示为n 个元素是x n N )和x D )使用了不同的字体以示区别。
从数据中寻找模式是一个基础性问题,这个问题有着悠久而成果丰硕的历史。例如,16世纪第谷·布拉赫(Tycho Brahe)广泛的天文观测记录帮助约翰内斯·开普勒(Johannes Kepler)发现了行星运动的多项经验定律,进而为经典力学的发展提供了跳板。类似地,20世纪初原子光谱规律性的发现对量子物理学的发展和验证起到了关键作用。模式识别领域关注的是通过使用计算机算法自动发现数据中的规律,并利用这些规律采取行动,例如将数据归入不同的类别。
以识别手写数字为例,如图1.1所示。每个数字对应一幅28像素×28像素的图像,因此可以用784个实数组成的向量
图1.1 取自美国邮政编码的手写数字示例
采用机器学习方法可以获得更好的结果。机器学习方法使用一个包含训练集(training set) ,用于调整自适应模型的参数。训练集中数字的类别事先已知,通常经过逐一检查和手工标注而得。我们可以使用目标向量(target vector)
机器学习算法的运行结果可以用函数训 练(training) 阶段根据训练数据确定的,该阶段也称学习(learning) 阶段。模型训练完成后,就可以用于确定新的数字图像的身份标签,这些新图像组成了测试集(test set) 。对不同于训练数据的新样本进行正确分类的能力称为泛化(generalization) 。在实际应用中,由于输入向量的可变性,训练数据只能包含所有可能输入向量的一小部分,因此泛化是模式识别的一个核心目标。
在大多数实际应用中,原始输入变量通常需要经过预处理(preprocessing) ,以变换到某个新的变量空间中,希望模式识别问题在这个新的变量空间中能更容易地得到解决。例如,在数字识别问题中,数字图像通常要经过平移和缩放处理[1] 特征提取(feature extraction) 。请注意,新的测试数据必须使用与训练数据相同的步骤进行预处理。
预处理也可能为了加快计算而执行。例如,如果目标是在高分辨率的视频流中实时检测面部,则计算机必须每秒处理大量像素,而将这些像素直接呈现给复杂的模式识别算法可能在计算上不可行。因此,目标应是找到可以快速计算的有用特征,同时保留区分面部和非面部所需的有用判别信息。这些特征随后用作模式识别算法的输入。例如,矩形子区域内图像强度[2]
当训练数据包括输入向量及其对应的目标向量示例时,这类应用被称为监督学习(supervised learning) 问题。以数字识别为例,其目的是将每个输入向量分配到数目有限的离散类别之一,这种情况被称为分类(classification) 问题。如果所需的输出由一个或多个连续变量组成,则称该任务为回归(regression) 。回归问题的一个例子是预测化学制造过程中的产量,其中输入由反应物的浓度、温度和压力组成。
在其他模式识别问题中,训练数据只包括一组输入向量x 聚类(clustering) ;或确定输入空间内数据的分布,称为密度估计(density estimation) ;或将数据从高维空间投影到二维或三维空间中,以便可视化( visualization) 。
最后,强化学习(reinforcement learning) (Sutton and Barto,1998)技术关注的问题是如何在给定情况下找到适当行动(action),以最大化奖励回报。不同于监督学习,强化学习算法并不给出最优输出的示例,而必须通过试错过程自行发现最优输出。通常,强化学习算法与环境交互时会出现一系列状态和行动。在许多情况下,当前行动不仅影响即时奖励,还会对所有后续时间步的奖励产生影响。例如,通过使用适当的强化学习技术,神经网络可以学会高水准地玩西洋双陆棋游戏(Tesauro,1994)。在此过程中,神经网络必须学会将棋盘位置和掷骰子的结果作为输入,并产生一个强有力的棋步作为输出。这是通过让神经网络与自身副本进行上百万局对弈来实现的。一个主要的挑战是,一场双陆棋游戏可能涉及数十步移动,但直到棋局结束时才获得以胜利形式出现的奖励。其次,必须适当地将奖励归功于促成胜利的所有棋步,即使其中有些棋步是好棋,有些则不是。这是一个贡献度分配(credit assignment) 问题的例子。强化学习的一个普遍特点是在探索(exploration) 和利用(exploitation) 之间进行权衡,前者指系统尝试新的行动类型以了解它们的有效性,而后者则指系统利用已知能产生高奖励的行动。过分关注探索或利用都会导致结果不佳。强化学习仍然是机器学习研究的一个活跃领域,不过,就其详细论述已超出本书范畴。
尽管这些任务各自需要专门的工具和技术,但支撑这些任务的许多关键理念对所有此类问题都是共通的。本章的主要目标之一是以相对非正式的方式介绍其中一些最重要的概念,并通过简单的示例加以说明。在本书的后面我们将看到这些相同理念会在更复杂的模型背景下重新出现,这些模型适用于现实世界中的模式识别应用。本章还将独立地提供三个将在整本书中使用的重要工具,即概率论、决策论和信息论。这些内容听起来似乎十分艰深,但实际上却简单明了,如果要在实际应用中发挥机器学习技术的最佳效果,就必须对它们有清晰的了解。
1.1 示例:多项式曲线拟合我们将从一个简单的回归问题入手。在本章中,我们将把这个问题作为贯穿始终的示例,用以引出一些关键概念。假设我们观测到一个实数型的输入变量
现在假设我们有一个训练集,其中不仅包含N 个
图1.2 由
我们的目标是利用这个训练集,针对输入变量的某个新值
不过当下我们将采取非正式的方式,继续考虑一种基于曲线拟合的简单方法。特别地,我们将使用多项式函数来拟合数据,其形式为
其中阶数(order) ,
系数的值是通过调整多项式拟合训练数据的方式来确定的。这可以通过最小化误 差函数(error function) 来实现。误差函数测量对于任意给定的
其中引入因子1/2是为了便于后续计算。本章稍后将讨论选择此种误差函数的动机。目前只需要注意这是一个非负数,当且仅当函数
图1.3 平方和误差函数[见式(1.2)]对应于每个数据点与函数
我们可以通过选择使
这里还存在一个选择多项式阶数模型比较(model comparison) 或模型选择(model selection) 的一个示例。在图1.4中,我们展示了用图1.2所示的数据集拟合阶数
我们注意到,常数(过拟合(over-fitting) 。
图1.4 在图1.2所示的训练数据集上拟合不同阶数(
正如前面所提到的,我们的目标是通过对新数据进行准确预测来实现良好的泛化。通过考虑由100个数据点组成的独立测试集,我们可以量化泛化性能对于M 的依赖性。该测试集使用与每个训练集完全相同的过程生成数据点,但在目标值中包含了新选择的随机噪声值。对于M 值,我们既可以计算训练数据在式(1.2)下的残差值
其中除以E RMS 与目标变量
图1.5 对式(1.3)定义的均方根误差,在不同
对于
这看似矛盾,因为给定阶数的多项式包含所有低阶多项式的特例。因此,
可以通过观测由不同阶数的多项式求得的系数
研究给定模型的行为随数据集规模的变化也很有趣,如图1.6所示。我们看到,对于给定的模型复杂度,随着数据集规模的增大,过拟合问题会变得不那么严重。换句话说,数据集越大,我们所能用来拟合数据的模型就越复杂(即越灵活)。一种粗略的启发式方法是,数据点的数量不应少于模型中自适应性参数数量的某个倍数(如5或10倍)。然而,正如我们将在第3章中所看到的,参数数量并不一定是衡量模型复杂程度的最合适指标。
表1.1 不同阶多项式的系数
0.19
0.82
0.31
0.35
-1.27
7.99
232.37
−25.43
−5 321.83
17.37
48 568.31
−231 639.30
640 042.26
−1 061 800.52
1 042 400.18
−557 682.99
125 201.43
图1.6 使用
此外,必须根据可用训练集的大小来限制模型中的参数数量这一要求,也会令人有些不满。更合理的选择似乎是根据要求解问题的复杂程度来选择模型的复杂程度。我们将看到,寻找模型参数的最小二乘法是最大似然(maximum likelihood) 法(参见1.2.5小节)的一种特殊情形,而过拟合问题可以理解为最大似然的一种一般特性(参见3.4节)。采用贝叶斯(Bayesian) 方法可以避免过拟合问题。我们将看到,从贝叶斯理论的视角来看,采用参数数量远超数据点数量的模型并不困难。事实上,在贝叶斯模型中,有效参数量会自动适应数据集的规模。
不过就眼下而言,继续沿用当前的方法,并考虑如何在实践中将其应用到有限规模的数据集上,是很有意义的。在数据集规模有限的情况下,我们可能希望使用相对复杂和灵活的模型,而其中控制过拟合现象的一种常用技术是正则化(regularization) ,即在误差函数[以式(1.2)所示的平方和误差函数为例]中加入惩罚项,以阻止系数达到较大值。最简单的惩罚项的形式是所有系数的平方和,从而得到修正的平方和误差函数为
其中w 0 会从正则化项中省略,因为它的加入会使结果依赖于目标变量的起点选择(Hastie et al.,2001),但如果保留,就要有自己的正则化系数(我们将在5.5.1小节中更详细地讨论这个话题)。此外,式(1.4)所示的误差函数可以用闭式方法精确地最小化(见习题1.2)。统计学文献中称这种方法为收缩(shrinkage) 法,因为它可以减小系数的值。二次正则化项的特殊情况则称为岭回归( ridge regression) (Hoerl and Kennard,1970)。在神经网络中,这种方法被称为权重衰减(weight decay) 。
图1.7展示了在此前相同数据集上拟合阶数
图1.7 利用正则化误差函数[见式(1.4)],在正则化参数λ 的两个值(分别对应
表1.2 正则化参数
0.35
0.35
0.13
232.37
4.74
−0.05
−5 321.83
−0.77
−0.06
48 568.31
−31.97
−0.05
−231 639.30
−3.89
−0.03
640 042.26
55.28
−0.02
−1 061 800.52
41.32
−0.01
1 042 400.18
−45.95
−0.00
−557 682.99
−91.53
0.00
125 201.43
72.68
0.01
通过绘制训练集和测试集的均方根误差[见式(1.3)]与
图1.8
模型复杂度是一个重要问题,这个问题我们将在1.3节中详细讨论。在此我们只需留意,如果试图用这种最小化误差函数的方法来解决实际应用问题,就必须找到一种方式来确定模型复杂度的合适值。上述结果给出了实现这一目标的简单方法,即对现有数据进行划分:一个训练集,用于确定系数验证(validation) 集,也称留出(hold-out) 集,用于优化模型复杂度(
到目前为止,我们对多项式曲线拟合的讨论主要基于直观判断。现在,我们将通过对概率论的讨论,寻求一种更有原则性的方法来解决模式识别中的问题。概率论不仅为本书几乎所有后续章节奠定了基础,也为我们在多项式曲线拟合示例中引入相关概念提供了一些重要的启示,从而让我们能够将这些概念延展到更复杂的场景中。
1.2 概率论模式识别领域的一个关键概念是不确定性。不确定性既缘于测量中的噪声,也缘于数据集有限的规模。概率论为量化和处理不确定性提供了一致的框架,是模式识别的核心基础之一。当把概率论与1.5节讨论的决策论相结合时,我们就能在掌握所有可用信息的情况下做出最优预测,即便这些信息可能是不完整或模糊的。
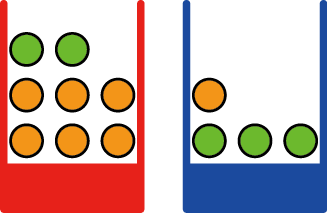
让我们通过一个简单例子来介绍概率论的基本概念。想象有两个盒子,一个是红色的,另一个是蓝色的。红色盒子里有2个苹果和6个橙子,蓝色盒子里有3个苹果和1个橙子,如图1.9所示。现在假设我们随机选取其中一个盒子,然后从该盒子中随机选取一种水果,观察它是哪种水果后,再把它放回原来的盒子。可以想象重复这个过程很多次。假设在这样做的过程中,我们有40%的时间选择红色的盒子,有60%的时间选择蓝色的盒子,并且从盒子中拿出水果时,每个水果被选中的可能性是相同的。
图1.9 我们用包含水果(绿色代表苹果,橙色代表橙子)的两个彩色盒子的简单例子来介绍概率的基本概念
在这个例子中,被选中的盒子的身份是一个随机变量,记作B 。这个随机变量有两种可能的取值,即r (对应红色盒子)和b (对应蓝色盒子)。同样,水果的身份也是一个随机变量,记作F ,它有a (代表苹果)和o (代表橙子)两种取值。
首先,我们定义事件的概率为,在无限次试验中,该事件发生的次数占总试验次数的比例。因此,选择红色盒子的概率是4/10,选择蓝色盒子的概率是6/10。我们把这些概率记作
我们现在可以提出这样的问题:选择程序选中苹果的总概率是多少?或者,假定选中了一个橙子,那么选中的盒子是蓝色的概率是多少?只要我们掌握了概率的两个基本法则——加和法则(sum rule) 与乘积法则(product rule) ,我们就能回答诸如此类的问题,并能回答与模式识别问题相关的更复杂的问题。在掌握了这两个基本法则后,我们再回到水果盒的例子。
为了推导出概率法则,考虑图1.10所示的稍宽泛的例子,其中涉及两个随机变量X 和Y (它们可以是上面提到的盒子变量和水果变量)。假设X 可以取任意值Y 也可以取任意值N 次试验中同时对变量X 和Y 进行采样,并将其中n ij X 取值Y 的值)的试验数记为Y 取值
图1.10 通过考虑两个随机变量i 列中的点数记为j 行中的点数记为r j
X 取值Y 取值
这里我们隐含地考虑了极限X 取值Y 值的概率记为i 列的点数占总点数的比例给出,即
由于图1.10中第i 列的实例数仅为该列中每个单元格的实例数的总和,我们有
这就是概率的加和法则 。注意,边缘(marginal) 概率,因为它是通过对其他变量(在本例中为Y )进行边缘化(或求和)得到的。
如果我们只考虑条件(conditional) 概率。它是通过求出第i 列中落在(i , j )单元格中的点数比例得到的,由下式给出:
从式(1.5)、式(1.6)和式(1.8)中,我们可以推导出如下关系:
这就是概率的乘积法则 。
到目前为止,我们一直很注意区分随机变量(如水果示例中的盒子B )和随机变量可能取的值。例如,如果盒子是红色的,则取r 。因此,B 取值为r 的概率记为B 的分布,或用r 下的分布,只要从上下文中能清楚其含义即可。
使用这种更简洁的表示法,我们可以将概率论中的两个基本法则写成如下形式。
概率论中的基本法则
加和法则
乘积法则
这里X 与Y 同时发生的概率”。同样,在 X 发生的条件下 Y 发生 的概率”;而X 发生的概率”。这两个简单的概率法则构成了我们在本书中使用的所有概率工具的基础。
根据概率的乘积法则,再加上对称性
这被称为贝叶斯定理(Bayes ’ theorem) ,它在模式识别和机器学习中发挥着核心作用。利用概率的加和法则,贝叶斯定理中的分母可以用分子中出现的量来表示:
我们可以将贝叶斯定理中的分母视为归一化常数,以确保式(1.12)左侧的条件概率对所有Y 值的和等于1。
在图1.11中,我们以两个变量的联合概率分布为例来说明边缘分布和条件分布的概念,左上图展示的是从联合概率分布中抽取的Y 的两种取值中每个值的数据点比例的直方图。根据概率的定义,在
图1.11 两个变量分布的示意图:X 有9种可能取值,Y 有2种可能取值。左上图展示了从这些变量的联合概率分布中抽取的60个样本点。其余图形展示了边缘分布
现在让我们回到水果盒的例子。我们将再次明确区分随机变量及其实例。我们已经看到,选择红色或蓝色盒子的概率分别为
请注意,它们满足
现在假设我们随机抽取一个盒子,结果得到蓝色的盒子。那么选中一个苹果的概率就是蓝色盒子里苹果所占的比例,即3/4,所以
请再次注意,这些概率都已归一化,因此有
类似地有
我们现在可以使用概率的加和法则与乘积法则来评估选择一个苹果的总体概率:
从而根据概率的加和法则得出
假设我们被告知选中的水果是一个橙子,我们想知道它来自哪个盒子。这需要我们评估在水果类型已知的情况下盒子的概率分布,而式(1.16)~式(1.19)中的概率给出的是在盒子已知的情况下水果类型的概率分布。我们可以使用贝叶斯定理来解决这个反向条件概率问题,得到
根据概率的加和法则,可以得出
我们可以对贝叶斯定理做出如下重要解释。如果在被告知所选水果的类别之前就被问及选中了哪个盒子,那么所掌握的最完整的信息就是概率先验 概率(prior probability) ,因为它是在观察到水果的类别之前 可获得的概率。一旦被告知水果是橙子,就可以利用贝叶斯定理计算出概率后验概率 (posterior probability) ,因为这是我们观察到F 之后 得到的概率。注意,在这个例子中,选择红色盒子的先验概率是4/10,所以我们更有可能选择蓝色盒子。然而,一旦我们观察到所选水果是橙子,就会发现红色盒子的后验概率现在是2/3,因此现在更有可能选择的其实是红色盒子。这一结果符合我们的直觉,因为红色盒子中橙子的比例远高于蓝色盒子中橙子的比例,因此观察到水果是橙子提供了有利于红色盒子的重要证据。事实上,该证据足够有力,以至于超过了先验概率,使得选择红色盒子比选择蓝色盒子的可能性更大。
最后,我们注意到,如果两个变量的联合概率分布可以分解为边缘分布的乘积,即X 和Y 相互独立(independent) 。根据概率的乘积法则,可以得到X 的条件下,Y 的条件分布确实与X的值无关。例如,在我们的水果盒示例中,如果每个盒子中苹果和橙子的比例相同,那么
1.2.1 概率密度 除了考虑定义在离散事件集上的概率之外,我们还希望考虑连续变量的概率。我们将仅限于进行相对非正式的讨论。如果实值变量x 位于区间x 的概率密度(probability density) 。这在图1.12中有所展示。x 位于区间(a , b )的概率由下式给出:
图1.12 离散变量的概率概念可以扩展为连续变量x 的概率密度x 位于区间
由于概率是非负的,而且x 的值必须位于实轴上的某处,因此概率密度
在非线性变量变换下,由于雅可比因子的作用,概率密度的变换与简单函数不同。例如,如果我们考虑变量y 的概率密度
这一性质的一个结果是,概率密度最大值的概念取决于变量的选择(见习题1.4)。
x 位于区间累积分布函数(cumulative distribution function) 给出:
该函数满足
假设我们有几个连续变量x x x
其中积分是在整个x
请注意,如果x 是离散变量,那么概率质量函数(probability mass function ) ,因为它可以看作集中在x 的允许值上的一组“概率质量”。
概率的加和法则与乘积法则以及贝叶斯定理,同样适用于概率密度以及离散变量与连续变量的组合情形。例如,如果x 和y 是两个实变量,那么加和法则与乘积法则的形式为
对于连续变量来说,概率的加和法则与乘积法则的形式化证明(Feller,1966)需要借助一个称为测度论(measure theory) 的数学分支,这不在本书的讨论范围内。不过,通过将每个实变量划分为宽度为
1.2.2 期望与协方差 与概率相关的最重要运算之一是求取函数的加权平均值。函数期望(expectation) ,记作
因此平均值由
但无论在哪种情况下,如果我们从概率分布或概率密度中得到有限数量(
后面第11章讨论采样方法时,我们将经常用到这一结果。式(1.35)中的近似值在极限
有时我们也会考虑多变量函数的期望,在这种情况下,可以使用下标来表示对哪个变量求平均,例如
表示函数
我们也可以考虑相对于条件分布的条件期望(conditional expectation) ,即
连续变量情形下的定义则类似。
方差(variance) 定义为
方差用于度量
特别地,我们可以考虑变量
对于两个随机变量协方差(covariance) 定义为
协方差表示
对于两个随机向量
如果我们考虑的是一个向量
1.2.3 贝叶斯概率 到目前为止,我们都是从随机、可重复事件发生的频率来看待概率的。我们将其称为概率的经典 或频率学派(frequentist) 解释。现在我们转向更一般的贝叶斯(Bayesian) 理论视角,在这种视角下,概率提供了一种不确定性的量化。
考虑一个不确定的事件,例如月球是否曾在其自身轨道上围绕太阳运转,或者北极冰盖是否会在21世纪末消失。这些事件不可能像我们之前讨论水果盒子时那样,为了定义概率概念而重复无数次。不过,我们一般会对于像极地冰层融化的速度有多快这样的概念有一些看法。如果获得了新的证据,例如来自新的地球观测卫星的新型诊断信息,我们可能会修正对融化速度的看法。对这些问题的评估将影响我们所采取的行动,例如减少温室气体排放的程度。在这种情况下,我们希望能够量化我们对不确定性的表述,并根据新的证据对不确定性进行精确修正,以及随后能够因此采取最佳行动或决策。这一切都可以通过优雅而非常通用的贝叶斯概率解释来实现。
使用概率来表示不确定性并不是临时起意的权宜之计,而是一种必然的选择,因为只有这样,我们才能在尊重常识的同时做出合理连贯的推论。例如,Cox(1946)证明了如果用数值来表示信念的程度,那么用一组简单的公理来编码这些信念的常识属性,就能唯一地得出一组操纵信念度的规则,这些规则等同于概率的加和法则与乘积法则。这首次严格证明了概率论可以视为布尔逻辑在涉及不确定性情况下的扩展(Jaynes,2003)。许多其他作者提出了此类不确定性度量应满足的不同属性或公理(Ramsey,1931;Good,1950;Savage,1961;deFinetti,1970;Lindley,1982)。在每种情况下,所得数值结果都与概率法则完全一致。因此,把这些数值称为(贝叶斯)概率是很合理的。
在模式识别领域,有一个更通用的概率概念也很有帮助。考虑1.1节中讨论的多项式曲线拟合的例子,将频率学派的概率概念应用于观测变量
托马斯·贝叶斯出生于英国坦布里奇韦尔斯,是一位牧师,也是一名业余科学家和数学家。他曾在爱丁堡大学学习逻辑学和神学,并于1742年当选英国皇家学会会员。18世纪,与赌博和新保险概念有关的概率问题层出不穷,其中一个特别重要的问题涉及所谓的逆概率。托马斯·贝叶斯在他的论文“Towards solving a problem in the doctrine of chances”中提出了解决方案,该论文于1764年,即他去世约三年后发表在《英国皇家学会哲学汇刊》上。事实上,贝叶斯只是针对均匀先验的情况提出了他的理论,皮埃尔-西蒙·拉普拉斯(Pierre-Simon Laplace)独立地重新发现了这一理论的一般形式,并证明了它的广泛适用性。
贝叶斯定理现在有了全新的理论内涵。回想一下,在水果盒子的例子中,对水果身份的观察提供了相关信息,改变了所选盒子为红色的概率。在这个例子中,贝叶斯定理被用来将先验概率转为后验概率,其中包含了观测数据提供的证据。稍后我们将详细介绍,在对多项式曲线拟合示例中的参数
因此我们可以用后验概率
式(1.43)右侧的似然函数(likelihood function) 。它表示在参数向量
鉴于似然的这一定义,我们可以将贝叶斯定理表述如下:
其中所有这些量都被视为
在贝叶斯学派和频率学派的范式体系中,似然函数
一种广泛使用的频率学派估计方法是最大似然(maximum likelihood) 估计,其中误差函数(error function) 。由于负对数函数具有单调递减性质,最大化似然相当于最小化误差。
一种确定频率学派估计量的误差范围的方法是自助法(bootstrap) (Efron,1979;Hastie et al., 2001),其通过以下方式创建多个数据集。假设原始数据集由
贝叶斯学派方法论的一个优势是可以很自然地纳入先验知识。例如,假设一枚看起来质地均匀的硬币被掷了三次,每次都正面朝上。经典的最大似然估计对硬币正面朝上概率的估计值为1,这意味着未来所有的硬币抛掷都将出现正面朝上(参见2.1节)!相比之下,采用任何合理先验的贝叶斯方法都会得出一个不那么极端的结论。
关于频率学派和贝叶斯学派方法论的相对优劣一直存在诸多争议,而事实上并不存在独特的频率学派或贝叶斯学派观点。例如,对贝叶斯学派的一个常见批评是,先验分布的选择往往基于数学上的便利而非任何真实的先验信念反映。有些人甚至认为结论的主观性取决于先验的选择,这也是困难的根源。减少对先验的依赖是所谓无信息(noninformative) 先验的动机之一(参见2.4.3小节)。然而,在对不同模型进行比较时,这些先验会引发困难。事实上,基于劣质先验选择的贝叶斯方法可能会给出置信度较高的劣质结果。频率学派的评估方法在一定程度上可以避免这些问题,交叉验证等技术在模型比较等领域仍然有用(参见1.3节)。
本书着重强调贝叶斯学派的观点,反映贝叶斯方法在过去几年实际重要性的巨大提升,同时也会根据需要讨论有用的频率学派理论。
尽管贝叶斯理论框架起源于18世纪,但在很长一段时间内,贝叶斯方法的实际应用受到了严重限制,因为难以执行完整的贝叶斯程序,特别是需要对整个参数空间进行边缘化(求和或积分),正如我们将看到的那样,这在进行预测或比较不同模型时是必要的。采样方法[如马尔可夫链-蒙特卡洛方法(将在第11章中讨论)]的发展,以及计算机速度和内存容量的显著提高,为贝叶斯技术在众多问题领域的实际应用打开了大门。蒙特卡洛方法非常灵活,可以应用于多种模型。然而,这些方法计算量大,主要用于小规模问题的求解。
最近,人们开发出了高效的确定性近似方案,如变分贝叶斯和期望传播(将第10章中讨论)。这些方法提供了采样方法的补充替代方案,使贝叶斯技术得以大规模应用(Blei et al.,2003)。
1.2.4 高斯分布 我们将在第2章中探究各种概率分布及其主要性质。不过为方便起见,在此介绍连续变量最重要的概率分布之一——高斯(Gaussian) 分布,又称正态(normal) 分布。我们将在本章的其余部分,乃至本书的大部分内容中广泛地使用这种分布。
对于单个实值变量
它受两个参数支配:均值( mean) ;方差(variance) 。方差的平方根标准差(standard deviation) ,方差的倒数精度(precision) 。我们很快就会介绍这些术语的含义。图1.13给出了高斯分布的图形。
图1.13 显示了均值
从式(1.46)的形式可以看出,高斯分布满足
此外,高斯分布是归一化的(见习题1.7),即
因此,式(1.46)满足有效概率密度的两个要求。
据说拉普拉斯非常不谦虚,曾一度宣称自己是当时法国最出色的数学家,这一说法在某种程度上是正确的。除了在数学上多产之外,他还对天文学做出了许多贡献,包括提出“星云假说”,认为地球是由一个由气体和尘埃组成的大型旋转盘凝结和冷却后形成的。1812年,他出版了《概率分析理论》。拉普拉斯在这本书中指出:“概率论不过是将常识简化为计算。”这部著作包含了对逆概率计算(后来被庞加莱称为贝叶斯定理)的讨论,他用其解决预期寿命、法理学、行星质量、三角测量和误差估计等方面的问题。
我们可以很容易地找到高斯分布下
由于参数
根据式(1.49)和式(1.50),可以得出
因此
我们还对定义在
其中
现在假设我们有一组观测数据
如果将其视为
图1.14 高斯分布的似然函数(用红色曲线表示)。黑点表示数据集
利用观测数据集确定概率分布参数的一个常用标准是找到使似然函数最大化的参数值。这似乎是一个奇怪的标准,因为根据我们前面对概率论的讨论,更合理的做法是最大化给定数据的参数概率,而不是最大化给定参数的数据概率。事实上,这两个标准是相关的,我们将在曲线拟合中讨论。
不过,目前我们将通过最大化似然函数[见式(1.53)]来确定高斯分布的未知参数
通过最大化式(1.54)与
此为样本均值(sample mean) ,也就是观测值
此为相对于样本均值样本方差(sample variance) 。需要注意的是,我们是针对
在本章的后面以及后续章节中,我们将强调最大似然法的重要局限性。在此,我们将结合一元高斯分布的最大似然参数设置方案来说明这一问题。我们将特别指出,最大似然法系统地低估了分布的方差。这是偏差(bias ) 现象的一个例子,与多项式曲线拟合中的过拟合问题有关(参见1.1节)。我们首先注意到,最大似然结果
因此最大似然估计平均会得到正确的均值,但会低估真实方差
图1.15 利用最大似然确定高斯分布的方差时产生偏差的示意图。绿色曲线表示产生数据的真实高斯分布,三条红色曲线表示使用最大似然结果[见式(1.55)和式(1.56)]拟合三个数据集(每个数据集由蓝色显示的两个数据点组成)后得到的高斯分布。从三个数据集的平均值来看,均值是正确的,但方差被系统性地低估了,因为方差是相对于样本均值而不是真实均值测量得到的
由式(1.58)可知,下面对方差参数的估计是无偏的:
在10.1.3小节中,我们将看到当采用贝叶斯方法时,这一结果是如何自动产生的。
请注意,随着数据点数
1.2.5 再论曲线拟合 我们已经看到多项式曲线拟合问题如何用误差最小化来表示(参见1.1节)。在此,我们回到曲线拟合的例子,从概率论的角度来看待这个问题,从而获得关于误差函数和正则化的见解,并引导我们进入全面的贝叶斯处理方法。
曲线拟合问题的目标是在一组由
为了与后面章节中的符号保持一致,我们定义了一个精度参数
图1.16 由式(1.60)给定
现在我们利用训练数据
与前面简单高斯分布的情况一样,最大化似然函数的对数是很方便的。代入式(1.46)给出的高斯分布形式,我们得到对数似然函数的形式为
首先考虑确定多项式系数的最大似然结果,记作平方和 误差函数 。因此,平方和误差函数是在高斯噪声分布假设下最大化似然的结果。
我们还可以利用最大似然确定高斯条件分布的精度参数
同样,我们可以首先确定控制均值的参数向量
在确定了参数预测分布(predictive distribution) 来表示,而不是进行简单的点估计,将最大似然参数代入式(1.60)可以得到
现在让我们向贝叶斯方法迈进一步:引入多项式系数
其中超参数(hyperparameter) 。利用贝叶斯定理,
现在,我们可以根据给定数据找出最可能的最大后验(maximum posterior ,简称MAP) 。取式(1.66)的负对数并结合式(1.62)和式(1.65),我们可以发现后验最大值是下式的最小值:
因此,我们可以看到后验分布的最大化等同于之前遇到的正则化平方和误差函数的最小化,其形式为式(1.4),正则化参数为
1.2.6 贝叶斯曲线拟合 虽然加入了先验分布
在曲线拟合问题中,我们得到了训练数据
贝叶斯处理方法简单地对应于概率的加和法则与乘积法则的一致应用,这使得预测分布可以写成
这里
其中均值和方差可表示为
这里矩阵S
其中
我们可以看到式(1.69)中预测分布的方差和均值都取决于
图1.17 使用
1.3 模型选择在使用最小二乘法进行多项式曲线拟合的示例中,我们发现存在一种最优的多项式阶数,它能带来最佳的泛化效果。多项式的阶数控制着模型中自由参数的数量,从而决定了模型的复杂度水平。在正则化最小二乘法中,正则化系数
我们已经看到,在最大似然法中,由于过拟合问题,模型在训练集上的性能并不能很好地反映模型在未见数据上的预测性能。如果数据很丰富,那么一种方法就是使用一些可用数据来训练一系列模型,或者使用一个给定模型的一系列复杂度参数值来训练该模型,然后在有时称为验证集(validation set) 的独立数据上对它们进行比较,选出预测性能最好的模型。如果使用规模有限的数据集多次迭代设计模型,就会出现对验证数据过度拟合的情况,因此可能需要保留测试集(test set) ,并在此基础上最终评估所选模型的性能。
然而,在许多应用中,用于训练和测试的数据是有限的,为了建立良好的模型,我们希望尽可能多地使用可用数据进行训练。但是,如果验证集较小,那么对模型预测性能的估计就会相对嘈杂。解决这一难题的方法之一是使用交叉验证(cross-validation ) ,如图1.18所示。这就允许将可用数据的留一(leave-one-out) 法。
图1.18 S 折交叉验证技术(此处以
交叉验证的一个主要缺点是,必须进行的训练运行次数会增加到原来的
历史上人们曾提出各种“信息准则”,试图通过增加惩罚项来纠正最大似然的偏差,以补偿较复杂模型的过拟合。例如,赤池信息准则(Akaike Information Criterion,AIC ) (Akaike,1974)选择使量
最大的模型。这里贝叶斯信息准则(Bayesian Information Criterion, BIC) 。然而,该准则并没有考虑模型参数的不确定性,而且在实践中往往偏好过于简单的模型。因此,我们将在3.4节转向完全贝叶斯方法,届时读者将看到复杂性惩罚是如何以一种自然且符合原则的方式产生的。
1.4 维度灾难在多项式曲线拟合的例子中,我们只有一个输入变量
为了说明问题,考虑一个通过合成生成的数据集,该数据集包含了从含有油、水、气混合物的管道中采集的测量数据(Bishop and James,1993)。以上三种物质可能呈现在三种不同的几何结构中,分别称为“均质”“环状”和“分层”结构,并且这三种物质的比例也可能不同。每个数据点都包含一个12维的输入矢量,该矢量由伽马射线密度计的测量数据组成,伽马射线密度计测量的是沿狭窄射束穿过管道时伽马射线的衰减情况。附录A详细说明了这组数据。图1.19展示了这组数据中的100个点,涉及两个测量值
图1.19 输入变量
如何将这种直觉转为学习算法呢?一种非常简单的方法是将输入空间划分为规则的单元格,如图1.20所示。当我们得到一个测试点并希望预测它的类别时,首先要确定它属于哪个单元格,然后找出属于同一单元格的所有训练点。测试点的类别将被预测为同单元格中具有最多训练点的类别(平局时为测试点随机分配类别)。
图1.20 解决分类问题的一种简单方法:将输入空间划分为多个单元格,任何新的测试点都会被分配到与该测试点处于同一单元格的训练点最多的类别中。我们很快就会看到,这种方法存在一些严重缺陷
这种简单的分类方法存在很多问题,当考虑将其扩展应用于具有更多输入变量的分类问题(对应于更高维度的输入空间)时,其中一个最严重的问题就显而易见了。图1.21展示了该问题的起源,如果我们将输入空间的一个区域划分为规则的单元格,那么这些单元格的数量会随着空间维度的增加呈指数增长。单元格数量呈指数增长的问题在于,我们需要大量的训练数据才能确保单元格不是空的。显然,我们并不希望将这种技术应用到只有几个变量的输入空间中,因此我们需要找到一种更合适的方法。
图1.21 维度灾难图解,其显示了规则网格的区域数量是如何随空间维数
让我们回到多项式曲线拟合的例子,考虑如何将这种方法扩展至处理具有多个变量的输入空间,从而进一步了解高维空间的问题(参见1.1节)。如果我们有
随着维度
我们的几何直觉是在三维空间中形成的,当我们考虑更高维的空间时,这种直觉就会严重失灵。举个简单的例子,假设在一个
其中常数
如图1.22中不同维度的函数曲线所示。我们看到,当
图1.22 在不同维度
再举一个与模式识别直接相关的例子,考虑一下高斯分布在高维空间中的表现。如果将笛卡儿坐标转换为极坐标,然后对方向变量进行积分,就可以得到密度
图1.23 高斯分布相对于半径
多维空间中可能出现的严重困难有时称为维度灾难(curse of dimensionality) (Bellman,1961)。在本书中,我们将大量使用涉及一维或二维输入空间的示例,因为这样特别容易用图形来说明这些技术。不过要提醒读者的是,并非所有在低维空间中形成的直觉都能推广到多维空间。
尽管“维度灾难”肯定会给模式识别的应用带来重要问题,但它并不妨碍我们找到适用于高维空间的有效技术。原因有二:第一,真实数据通常会被限制在有效维度较低的空间区域,特别是目标变量发生重要变化的方向可能会被限制在这一区域;第二,真实数据通常会表现出一定的平滑性(至少是局部平滑),因此在大多数情况下,输入变量的微小变化会导致目标变量发生微小变化,因此我们可以利用类似局部插值的技术,针对输入变量的新值对目标变量进行预测。成功的模式识别技术都会利用上述一种或两种特性。举例来说,在制造业的一个应用中,捕捉传送带上相同平面物体的图像,是为了确定它们的方向。每幅图像都是高维空间中的一个点,其维度由像素数量决定。由于物体可能以不同位置和不同方向出现在图像中,因此图像之间存在三个自由度的变化,一组图像将存在于嵌入高维空间的三维流形(manifold) 上。由于物体位置或方向与像素强度之间的复杂关系,这个流形将是高度非线性的。如果我们的目标是学习一个能够接收输入图像并输出物体方位(无论其位置如何)的模型,那么流形内只有一个自由度的变化将具有重要意义。
1.5 决策论我们在1.2节中看到了概率论为我们提供了量化和处理不确定性的一致数学框架。在此,我们将讨论决策论,当把决策论与概率论相结合时,我们就能在涉及不确定性的情况下做出最优决策,例如在模式识别中遇到的情况。
假设我们有一个输入向量推断(inference) 的一个例子,也是一个非常困难的问题,本书的大部分内容将讨论如何解决这个问题。然而在实际应用中,我们往往必须对
例如,考虑一个医学诊断问题,我们拍摄了病人的X光影像,并希望确定病人是否患有癌症。在这种情况下,输入向量决策(decision) 环节,决策论的主题就是告诉我们如何在适当的概率条件下做出最优决策。我们将看到,一旦解决了推断问题,决策环节通常非常简单,甚至毫不费力。
在此,我们将介绍本书其他部分所涉及的决策论的主要观点。更多的背景知识和更详细的介绍,请参阅Berger(1985)和Bather(2000)。
在进行更详细的分析之前,不妨先非正式地考虑一下我们会如何期望概率在决策中发挥作用。当我们获得一个新患者的X光影像
请注意,贝叶斯定理中出现的任何量都可以通过对适合的变量进行边缘化或条件化,进而从联合概率分布
1.5.1 最小化误分类率 假设我们的目标只是尽可能减少误分类。我们需要有一条规则,以便将决策区域(decision region) ,每个类别一个决策区域,这样决策边界(decision boundary) 或决策面(decision surface) 。需要注意的是,每个决策区域不一定是连续的,也可以由若干不相交的区域组成。在后面的章节中,我们还会遇到决策边界和决策区域的例子。为了找到最优决策规则,首先考虑两个类别的情况,就像前述的癌症问题那样。当属于
我们可以自由选择决策规则,将每个点
图1.24 两个类别中每个类别的联合概率
对于
当选择
1.5.2 最小化预期损失 在许多应用中,我们的目标要比简单地最小化误分类率要复杂得多。让我们再次考虑前述的医疗诊断问题。我们注意到,如果一个未患癌症的病人被错误地诊断为患了癌症,其后果可能是病人会承受一些痛苦,且需要进一步检查。相反,如果一个癌症病人被漏诊,结果可能导致这个病人由于缺乏治疗而过早死亡。因此,这两种错误造成的后果可能大相径庭。显然,最好少犯第二种错误,哪怕以多犯第一种错误为代价。
我们可以通过引入损失函数(loss function) 来形式化表述这些问题,损失函数也称成本函数(cost function) 。损失函数是对采取任何可用决策或行动所造成损失的单一、总体衡量。我们的目标就是最大限度地减少总损失。请注意,有些作者考虑的是效用函数(utility function) ,他们的目标是最大化效用函数的值。如果我们把效用简单地理解为损失的负值,那么这两个概念是等价的。假设对于一个新的损失矩阵(loss matrix) 的
图1.25 癌症诊断问题中元素为
最佳解决方案是使损失最小的方案。然而,损失函数取决于未知的真实类别。对于给定的输入向量
每个
最小的类别
1.5.3 拒绝选项 我们已经看到,分类错误产生于输入空间的一些区域,在这些区域,后验类别概率拒绝选项( reject option) 。例如,在我们假设的医疗诊断示例中,可能适合使用自动系统对那些正确类别几乎不存在疑问的X光影像进行分类,而让人类专家对较为模糊的样本进行分类。为此,我们可以引入一个阈值
图1.26 拒绝选项图解。如果输入
在给出损失矩阵的情况下,我们可以很容易地将拒绝准则扩展至最小化预期损失,同时考虑做出拒绝决定时所产生的损失(见习题1.24)。
1.5.4 推断与决策 我们可以将分类问题分解为两个独立的阶段:推断阶段(inference stage) 和决策阶段(decision stage) 。在推断阶段,我们使用训练数据来学习判别函数(discriminant function) 。
事实上,我们可以找出三种不同的方法来解决决策问题,它们都已在现实世界中得到应用。按照复杂程度递减的顺序,这三种方法分别如下。
(a)首先解决推断问题,即分别确定每个类别
求出后验类别概率
相应地,我们可以直接建模联合概率分布x 生成式模型(generative model) ,因为通过对它们进行采样,就可以在输入空间中生成合成数据。
(b)首先求解推断问题,即确定后验类别概率判别模型(discriminative model) 。
(c)找到一个能将每个输入
让我们来看看这三种方法的相对优势。方法(a)要求最高,因为它需要找到离群点检测(outlier detection) 或新奇样本检测(novelty detection) (Bishop,1994;Tarassenko,1995)。
然而,如果我们只想做出分类决策,那么寻找联合概率分布
方法(c)是一种更简单的方法,即使用训练数据找到一个判别函数x
图1.27 具有单一输入变量
但是,如果采用方法(c),我们就无法再获得后验类别概率
风险最小化。 考虑这样一个问题:损失矩阵的元素时常会被修改(例如在金融应用中可能出现的情况)。如果我们知道后验概率,就可以通过适当修改式(1.81)来修正最小风险决策标准。如果我们只有一个判别函数,那么损失矩阵的任何改变都要求我们返回训练数据,重新解决分类问题。
拒绝选项。 通过后验概率,我们可以确定一个拒绝标准,使给定拒绝数据点的误分类率(或更广义的预期损失)最小。
补偿类别先验。 再次考虑前述的医疗诊断问题,假设我们从普通人群中收集了大量X光影像作为训练数据,以建立一个自动筛查系统。由于癌症在普通人群中发病率很低,我们可能会发现,比如说,每1000例样本中仅有1例癌症患者。如果我们使用这样的数据集来训练自适应模型,由于癌症类的比例太小,我们可能会遭遇严重的困难。例如,简单地将每个样本都归入正常类的分类器可以达到99.9%的准确率,这种简单解决方案下的漏诊难以避免。另外,即使是一个大型数据集,其中包含的与癌症相对应的X光影像也会非常少,因此学习算法不会接触到广泛的此类图像示例,因而不可能有很好的泛化效果。如果采用均衡数据集,从每个类别中选取数量相同的样本,我们就能找到更准确的模型。但是,我们必须对训练数据的修改效果进行补偿。假设我们使用了这样一个修改过的数据集,并找到了后验概率模型。根据贝叶斯定理[见式(1.82)],我们可以看到后验概率与先验概率成正比。我们可以将先验概率解释为每个类别中样本的分数。因此,只需将我们从人为的均衡数据集中得到的后验概率除以该数据集中的类别分数,再乘以我们希望应用该模型的人群中的类别分数即可。最后,我们需要进行归一化处理,以确保新的后验概率总和为1。需要注意的是,如果我们直接学习判别函数而不是确定后验概率,则无法应用这一过程。
模型组合。 对于复杂的应用,我们可能希望将问题分解成若干较小的子问题,每个子问题都可以用一个单独的模块来处理。例如,在我们假设的医疗诊断问题中,我们可能会从血液检测和X光影像等方面获得信息。与其将所有这些异构信息整合到一个巨大的输入空间,不如建立一个系统来解释X光影像,并用另一个系统来解释血液数据。只要这两个系统都给出类别的后验概率,我们就可以利用概率法则系统地组合输出结果。一种简单的方法是假定对于每个类别,X光影像(用
这是条件独立性(conditional independence) 假设的一个例子(参见8.2节),因为当分布以类
因此,我们需要先验类别概率朴素贝叶斯模型(naive Bayes model ) 的一个例子(参见8.2.2小节)。请注意,在此模型下,联合边缘分布
1.5.5 回归问题的损失函数 到目前为止,我们已经讨论了分类问题中的决策论。现在我们来讨论回归问题,例如前面讨论的曲线拟合问题(参见1.1节)。决策阶段的核心任务是为每个输入
回归问题中常用的损失函数是平方损失函数,即
我们的目标是选择
求解
它是以回归函数(regression function) 。图1.28展示了这一结果。它可以很容易地扩展到由向量
图1.28 回归函数
我们还可以用稍微不同的方法推导出这一结果,这也将揭示回归问题的本质。有了最优解是条件期望的知识,我们可以将平方项展开如下:
其中,为了保持符号简洁,我们用
我们要确定的函数
与分类问题一样,我们既可以确定适当的概率,然后利用这些概率做出最优决策,也可以建立直接做出决策的模型。事实上,我们可以找出三种不同的方法来解决回归问题。按复杂度递减的顺序,这三种方法分别如下。
(a)首先求解旨在确定联合概率密度
(b)首先求解旨在确定条件概率密度
(c)直接从训练数据中找出回归函数
以上三种方法的相对优势与前述分类问题的思路相同。
平方损失函数并不是回归问题中唯一可选的损失函数。事实上,在有些情况下,平方损失会导致非常糟糕的结果,因此我们需要找到更合适的方法。条件分布闵可夫斯基(Minkowski) 损失,其期望由下式给出:
当
图1.29 不同
1.6 信息论前面我们讨论了概率论和决策论中的各种概念,这些概念将构成本书后续讨论的基础。在本章的最后,我们将介绍信息论中的其他一些概念,这些概念也将被证明有助于我们开发模式识别和机器学习技术。同样,我们将只关注关键概念,更详细的讨论请参考其他文献(Viterbi and Omura,1979;Cover and Thomas,1991;MacKay,2003)。
首先考虑一个离散随机变量
其中的负号确保了信息为正值或零。请注意,低概率事件
现在假设发送方希望向接收方传输随机变量的值。它们在这一过程中传输的平均信息量可以通过求概率分布
这个重要的量称为随机变量熵 。请注意,
至此,我们已经给出了信息定义[见式(1.92)]和相应熵定义[见式(1.93)]的启发式论证。现在我们要证明这些定义确实具有有用的性质。考虑一个有8种可能状态的随机变量x ,其每种状态的可能性都相同。为了将
再看一个例子(Cover and Thomas,1991),变量有8种可能的状态
可以看到,非均匀分布的熵比均匀分布的熵小,稍后讨论从无序角度解释熵时,读者会对此有所了解。现在,让我们考虑一下如何将变量状态的身份信息传递给接收者。我们可以像以前一样,使用3位数字来实现这一目的。不过,我们可以利用非均匀分布的优势,对可能性较高的事件使用较短的编码,而对可能性较低的事件使用较长的编码,以期获得较短的平均编码长度。例如,可以使用以下一组代码字符串来表示状态
这也与随机变量的熵相同。需要注意的是,不能使用更短的代码字符串,因为要求必须能够将这些代码字符串的连接分解为其组成部分。例如,11001110必须能够唯一解码为状态序列c , a , d 。
熵与最短编码长度之间的这种关系是一种普遍情形。无噪声编码定理(noiseless coding theorem) (Shannon,1948)指出,熵是传输随机变量状态所需比特数的下界。
从现在起,我们将改用自然对数来定义熵,因为这样可以更方便地与本书其他部分的观点联系起来。在这种情况下,熵的单位是“纳特”(nat)而不是比特,两者之间存在ln 2倍的关系。
我们从说明随机变量状态所需的平均信息量的角度引入了熵的概念。事实上,熵的概念在物理学中的起源要早得多,它是在平衡热力学的背景下提出的,后来经过统计力学的发展,被更深入地解释为一种无序的度量。我们可以从另一个角度来理解熵的概念,即把一组
这就是所谓的乘数(multiplicity) 。熵可以定义为用一个适当的常数进行缩放后的乘数的对数,即
考虑极限
可以得到
其中利用了微观状态(microstate) ,而通过宏观状态(macrostate) 。乘数权重(weight) 。
我们可以把箱子理解为离散随机变量
如图1.30所示,分布
从中我们可以发现所有的
其中
图1.30 两种概率分布在30个分段上的直方图,其说明较宽分布的熵
我们可以将熵的定义扩展到连续变量中值定理( mean value theorem) (Weisstein,1999)告诉我们,对于每一个这样的分段,一定存在一个值
现在我们可以将连续变量
其中利用了
其中右侧的量称为微分熵(differential entropy) 。我们看到,熵的离散形式和连续形式的差分量为
在离散分布的情况下,我们看到最大熵配置对应于变量可能状态下的等概率分布。现在让我们考虑连续变量的最大熵配置。为了使这个最大值定义明确,有必要对
可以使用拉格朗日乘子法进行受限最大化(参见附录E),这样我们就可以最大化以下与
利用变分法,我们将这个泛函的导数设为零,得到(参见附录D)
将这一结果代入前面的三个约束方程,可以求出拉格朗日乘子,最后得到如下结果(见习题1.34)
因此最大化微分熵的分布就是高斯分布。请注意,我们在最大化熵时并没有限制分布必须是非负的。然而,由于得出的分布确实是非负的,我们事后发现这种限制是不必要的。
如果我们求高斯分布的微分熵,就会得到(见习题1.35)
因此,我们再次看到,熵随着分布变宽而增加,即随着
假设我们有一个联合概率分布
这就是给定条件熵(conditional entropy) 。利用概率的乘积法则很容易看出,条件熵满足关系(见习题1.37)
其中
从密歇根大学和麻省理工学院毕业后,香农于1941年加入AT&T贝尔电话实验室。他于1948年在《贝尔系统技术期刊》上发表的论文《通信的数学理论》奠定了现代信息论的基础。这篇论文引入了“比特”一词,他认为信息可以作为1和0的数据流发送,这一概念为通信革命铺平了道路。据说,冯·诺依曼建议香农使用“熵”(entropy)一词,这不仅是因为它与物理学中使用的量相似,还因为“没有人知道熵到底是什么,所以在任何讨论中,你总是会占上风”。
1.6.1 相对熵与互信息 到目前为止,我们已经介绍了信息论中的一些概念,包括关键的熵概念。现在我们开始将这些概念与模式识别联系起来。考虑某个未知的分布额外 信息量(以纳特为单位)为
这就是分布相对熵(relative entropy) 或Kullback-Leibler散度(简称KL散度) (Kullback and Leibler,1951)。请注意,它不是一个对称量,即
下面我们来证明
图1.31 凸函数是其每条弦(蓝色所示)都位于函数曲线(红色所示)上方或与之重合的函数
这相当于要求函数的二阶导数处处为正。凸函数的例子有严格凸(strictly convex) 。如果函数具有相反的性质,即每条弦都位于函数曲线的下方或与之重合,则称为凹( concave) 函数,严格凹(strictly concave) 函数也有相应的定义。如果函数
利用归纳证明的技巧(见习题1.38),我们可以通过式(1.114)证明凸函数
其中詹森不等式 (Jensen ’ s inequality) 。如果我们把
其中
我们可以将式(1.117)所示的詹森不等式应用于
其中利用了
我们可以看到,数据压缩与密度估计(即对未知概率分布建模的问题)之间有着密切的关系,因为当我们知道真实的分布时,就能实现最有效的压缩。如果我们使用的分布与真实分布不同,那么我们的编码效率必然较低,平均而言,必须传输的额外信息(至少)等于两个分布之间的
假设数据是由我们希望建模的未知分布
式(1.119)右侧的第二项与
现在考虑两个变量集
这称为变量集互信息(mutual information) 。根据
因此,我们可以把互信息看作由于获知
习题 1.1 (*)
其中
这里,上角标
1.2 (*) 写出类似于式(1.122)的耦合线性方程组,这些方程满足使式(1.4)给出的正则化误差函数最小的系数
1.3 (**) 假设我们有三个彩色的盒子r (红色)、b (蓝色)和g (绿色)。盒子r 中有3个苹果、4个橙子和3个青柠,盒子b 中有1个苹果、1个橙子和0个青柠,盒子g 中有3个苹果、3个橙子和4个青柠。如果以
1.4 (**)
1.5 (*) 利用式(1.38)证明
1.6 (*) 证明如果两个变量
1.7 (**)
将其平方写成如下形式以便求值:
现在将笛卡儿坐标
最后,利用这一结果来证明高斯分布
1.8 (**)
的两边进行微分,证明高斯分布满足式(1.50)。最后证明式(1.51)成立。
1.9 (*)
1.10 (*)
1.11 (*) 将对数似然函数[见式(1.54)]关于
1.12 (**)
其中
1.13 (*) 假设使用式(1.56)估计高斯分布的方差,但用均值的真实值
1.14 (**) 证明元素为
证明
使得反对称矩阵的贡献消失。因此我们看到,在不失一般性的情况下,系数矩阵
1.15 (***)
系数
请注意,系数
接下来用归纳法证明下面的式子成立:
首先利用结果
为此,首先通过与习题1.14的结果做比较,证明该结果对于
1.16 (***) 在习题1.15中,我们证明了
其中
接下来利用式(1.137)的计算结果和归纳法证明
为此,首先证明结果在
证明对于
1.17 (**)
用分部积分法证明关系式
1.18 (**)
利用伽马函数的定义[见式(1.141)],并结合式(1.126),求出式(1.142)所示方程两边的值,从而证明
接下来,通过对半径从0到1进行积分,证明
最后,利用结果
1.19 (**) 考虑一个半径为
利用对
证明当
我们还可以证明,超立方体中心到其中一个顶点的距离与到其中一条边的垂直距离的比值是
1.20 (**)
我们希望在极坐标中求得相对于半径的概率密度,其中的方向变量已被积分掉。为此,请证明半径为
这里
这表明
1.21 (**) 考虑两个非负数
1.22 (*)
1.23 (*) 当损失矩阵和先验类别概率均为一般情形时,推导出能使预期损失最小化的准则。
1.24 (**)
1.25 (*) t 的平方损失函数[见式(1.87)]推广到由向量t
利用变分法,证明能使预期损失最小化的函数为t 的情况下,这一结果可简化为式(1.89)。
1.26 (*) 通过将式(1.151)中的平方项展开,推导出类似于式(1.90)的结果,从而证明在目标变量向量t t
1.27 (**) x
1.28 (*) 在1.6节中,我们介绍了熵
1.29 (*)
1.30 (**) 求两个高斯分布
1.31 (**) x y
当且仅当
1.32 (*) 考虑一个连续变量向量x
1.33 (**) 假设两个离散随机变量
1.34 (**)
1.35 (*)
1.36 (*) 严格凸函数是指每条弦都位于函数曲线上方或与之重合的函数。证明这等同于函数的二阶导数为正这一条件。
1.37 (*) 利用式(1.111)并结合概率的乘积法则,证明式(1.112)。
1.38 (**)
1.39 (***) 考虑两个二元变量
求下列量:
(a)
(b)
请画图表示这些量之间的关系。
1.40 (*) 运用
1.41 (*)
表1.3 习题1.39中使用的两个二元变量
y
0
1
x
0
1/3
1/3
1
0
1/3














 进行标记。其余习题的解答如有需要,可联系出版商(联系方式见本书网站)获取。我们强烈建议读者独立完成习题,并仅在必要时参考解答。
进行标记。其余习题的解答如有需要,可联系出版商(联系方式见本书网站)获取。我们强烈建议读者独立完成习题,并仅在必要时参考解答。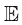 x[f (x, y)]。在对变量求平均值无歧义的情况下,可以省略后缀,例如
x[f (x, y)]。在对变量求平均值无歧义的情况下,可以省略后缀,例如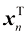 。因此,X的第n行第i列元素对应于第n个观测xn的第i个元素。对于一维变量,我们将这样的矩阵表示为
。因此,X的第n行第i列元素对应于第n个观测xn的第i个元素。对于一维变量,我们将这样的矩阵表示为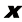 ,它是一个列向量,其第n个元素是xn。请注意,
,它是一个列向量,其第n个元素是xn。请注意,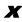 (维度为N)和x(维度为D)使用了不同的字体以示区别。
(维度为N)和x(维度为D)使用了不同的字体以示区别。
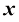 来表示。我们的目标是建立一个机器,将这样的向量
来表示。我们的目标是建立一个机器,将这样的向量
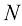 个数字的大型数字集合
个数字的大型数字集合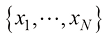 作为训练集(training set),用于调整自适应模型的参数。训练集中数字的类别事先已知,通常经过逐一检查和手工标注而得。我们可以使用目标向量(target vector)
作为训练集(training set),用于调整自适应模型的参数。训练集中数字的类别事先已知,通常经过逐一检查和手工标注而得。我们可以使用目标向量(target vector)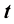 表示数字的类别,它代表了相应数字的身份标签。用向量表示类别的合适技术将在后面章节讨论。请注意,每个数字图像
表示数字的类别,它代表了相应数字的身份标签。用向量表示类别的合适技术将在后面章节讨论。请注意,每个数字图像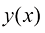 来表示,该函数将新的数字图像
来表示,该函数将新的数字图像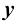 ,其编码方式与目标向量相同。函数
,其编码方式与目标向量相同。函数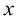 ,并希望利用这一观测结果来预测一个实数型目标变量
,并希望利用这一观测结果来预测一个实数型目标变量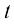 的值。为了更好地理解,考虑一个使用合成数据生成的人工示例会很有启发,由此我们就能知道生成数据的确切过程,从而与所学模型进行比较。本例的数据由函数
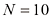
的值。为了更好地理解,考虑一个使用合成数据生成的人工示例会很有启发,由此我们就能知道生成数据的确切过程,从而与所学模型进行比较。本例的数据由函数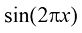 生成,并在目标值中加入了随机噪声,详见附录A。
生成,并在目标值中加入了随机噪声,详见附录A。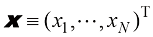 ,还包含相应
,还包含相应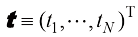 。图1.2展示了一个包含
。图1.2展示了一个包含 个数据点的训练集。图1.2中的输入数据集
个数据点的训练集。图1.2中的输入数据集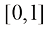 区间均匀选择
区间均匀选择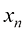 的值来生成的,其中
的值来生成的,其中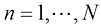 。目标数据集
。目标数据集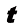 的获取方式如下:首先计算函数
的获取方式如下:首先计算函数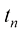 值。通过这种方式生成数据,我们捕获了许多真实数据集的一个属性,即它们具有潜在的规律性,我们希望学习这种规律性,但个别观测结果受到随机噪声的干扰。这种噪声可能源于内在的随机过程,如放射性衰变,但更常见的是由于存在自身未被观测到的可变性来源。
值。通过这种方式生成数据,我们捕获了许多真实数据集的一个属性,即它们具有潜在的规律性,我们希望学习这种规律性,但个别观测结果受到随机噪声的干扰。这种噪声可能源于内在的随机过程,如放射性衰变,但更常见的是由于存在自身未被观测到的可变性来源。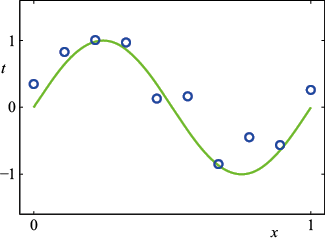
 个点(蓝色圆圈)组成的训练数据集,其中的每个点反映输入变量
个点(蓝色圆圈)组成的训练数据集,其中的每个点反映输入变量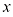 和相应的目标变量
和相应的目标变量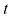 的观测值。绿色曲线表示用于生成数据的函数
的观测值。绿色曲线表示用于生成数据的函数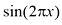 。目标是在不知道绿色曲线的情况下,预测某个新的
。目标是在不知道绿色曲线的情况下,预测某个新的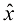 预测目标变量的值
预测目标变量的值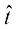 。正如我们稍后将看到的那样,这隐含着试图发现潜在的函数
。正如我们稍后将看到的那样,这隐含着试图发现潜在的函数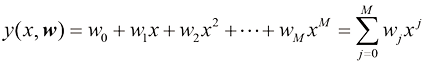 (1.1)
(1.1)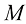 是多项式的阶数(order),
是多项式的阶数(order),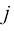 次幂记作
次幂记作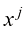 。多项式系数
。多项式系数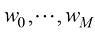 整体记作向量
整体记作向量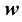 。注意,虽然多项式函数
。注意,虽然多项式函数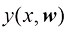 是
是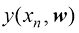 与相应的目标值
与相应的目标值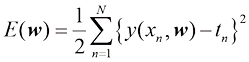 (1.2)
(1.2)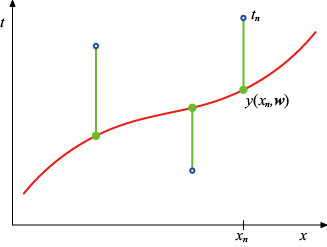
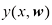 之间位移(垂直绿线)的平方和(的一半)
之间位移(垂直绿线)的平方和(的一半)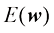 尽量小的
尽量小的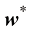 ,可以用闭式求解的方法得到(见习题1.1)。由此得到的多项式由函数
,可以用闭式求解的方法得到(见习题1.1)。由此得到的多项式由函数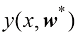 给出。
给出。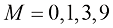 的多项式的4个结果示例。
的多项式的4个结果示例。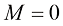 )和一阶(
)和一阶( )多项式对数据的拟合效果很差,因此对函数
)多项式对数据的拟合效果很差,因此对函数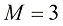 )多项式似乎对函数
)多项式似乎对函数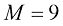 )的多项式时,训练数据的拟合效果达到完美。事实上多项式恰好通过了每个数据点,
)的多项式时,训练数据的拟合效果达到完美。事实上多项式恰好通过了每个数据点,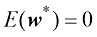 。然而,拟合曲线摆动剧烈,对函数
。然而,拟合曲线摆动剧烈,对函数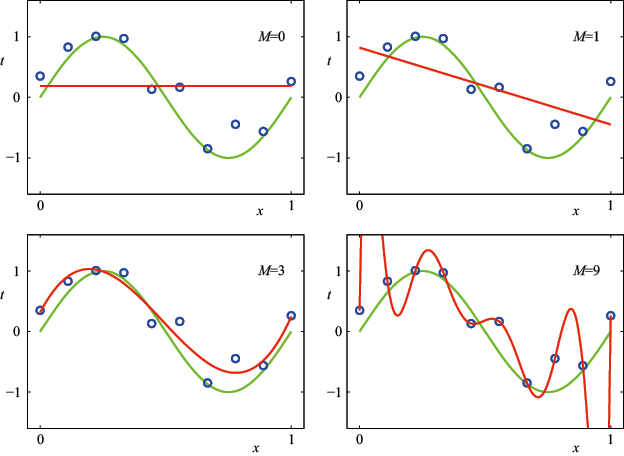
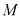 )的多项式(红色曲线)
)的多项式(红色曲线)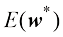 ,也可以计算测试数据集的
,也可以计算测试数据集的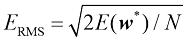 (1.3)
(1.3) 的范围时,测试集误差不仅较小,也能合理地表示生成函数
的范围时,测试集误差不仅较小,也能合理地表示生成函数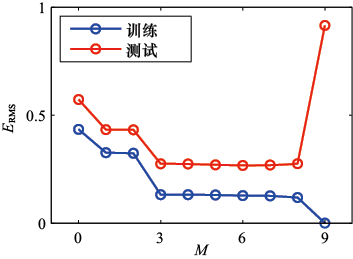
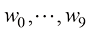 ,因此可以根据训练集中的10个数据点进行精确调整。然而,测试集误差变得非常大,正如我们在图1.4中所看到的,相应的函数
,因此可以根据训练集中的10个数据点进行精确调整。然而,测试集误差变得非常大,正如我们在图1.4中所看到的,相应的函数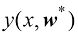 呈现出大幅振荡。
呈现出大幅振荡。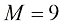 的多项式能够产生至少与
的多项式能够产生至少与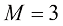 的多项式一样好的结果。此外,我们可能会认为,新数据的最佳预测函数是生成数据的函数
的多项式一样好的结果。此外,我们可能会认为,新数据的最佳预测函数是生成数据的函数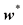 的对照表。请注意观察系数的典型量级是如何随着多项式阶数的增加而急剧增大的
的对照表。请注意观察系数的典型量级是如何随着多项式阶数的增加而急剧增大的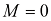
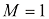
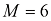
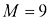
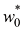
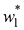
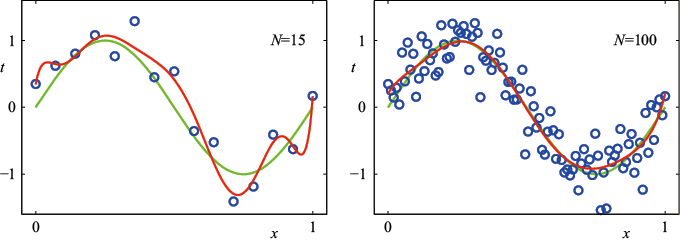
 的多项式最小化平方和误差函数求解的曲线图,左图对应
的多项式最小化平方和误差函数求解的曲线图,左图对应 个数据点,右图对应
个数据点,右图对应 个数据点。可以看到,增加数据集的规模可以缓解过拟合问题
个数据点。可以看到,增加数据集的规模可以缓解过拟合问题 (1.4)
(1.4)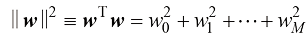 ,而系数
,而系数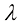 则决定了正则化项相对于平方和误差项的重要性。需要注意的是,通常系数w0会从正则化项中省略,因为它的加入会使结果依赖于目标变量的起点选择(Hastie et al.,2001),但如果保留,就要有自己的正则化系数(我们将在5.5.1小节中更详细地讨论这个话题)。此外,式(1.4)所示的误差函数可以用闭式方法精确地最小化(见习题1.2)。统计学文献中称这种方法为收缩(shrinkage)法,因为它可以减小系数的值。二次正则化项的特殊情况则称为岭回归(ridge regression)(Hoerl and Kennard,1970)。在神经网络中,这种方法被称为权重衰减(weight decay)。
则决定了正则化项相对于平方和误差项的重要性。需要注意的是,通常系数w0会从正则化项中省略,因为它的加入会使结果依赖于目标变量的起点选择(Hastie et al.,2001),但如果保留,就要有自己的正则化系数(我们将在5.5.1小节中更详细地讨论这个话题)。此外,式(1.4)所示的误差函数可以用闭式方法精确地最小化(见习题1.2)。统计学文献中称这种方法为收缩(shrinkage)法,因为它可以减小系数的值。二次正则化项的特殊情况则称为岭回归(ridge regression)(Hoerl and Kennard,1970)。在神经网络中,这种方法被称为权重衰减(weight decay)。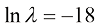 的数值条件下,过拟合被抑制,于是获得了更接近潜在函数
的数值条件下,过拟合被抑制,于是获得了更接近潜在函数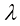 值,则会再次得到欠佳的拟合效果,如图1.7中
值,则会再次得到欠佳的拟合效果,如图1.7中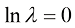 的情况所示。表1.2给出了拟合多项式的相应系数,这表明正则化具有降低系数大小的预期效果。
的情况所示。表1.2给出了拟合多项式的相应系数,这表明正则化具有降低系数大小的预期效果。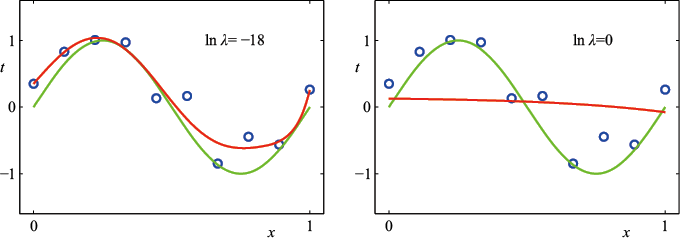
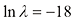 和
和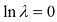 )下,对图1.2所示的数据集进行
)下,对图1.2所示的数据集进行 的情况,对应
的情况,对应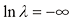
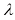 取值不同的
取值不同的


 的关系图,可以看出正则化项对泛化误差的影响,如图1.8所示。我们看到,实际上
的关系图,可以看出正则化项对泛化误差的影响,如图1.8所示。我们看到,实际上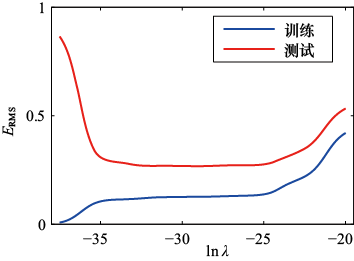
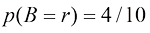 和
和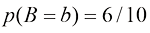 。请注意,根据定义,概率必须在区间
。请注意,根据定义,概率必须在区间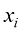 (其中
(其中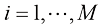 ),Y也可以取任意值
),Y也可以取任意值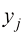 (其中
(其中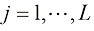 )。考虑在N次试验中同时对变量X和Y进行采样,并将其中
)。考虑在N次试验中同时对变量X和Y进行采样,并将其中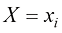 和
和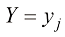 的试验数设为nij。此外,X取值
的试验数设为nij。此外,X取值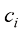 ,Y取值
,Y取值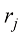 。
。
 和
和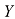 可以推导出概率的加和法则与乘积法则。这里
可以推导出概率的加和法则与乘积法则。这里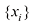 (其中
(其中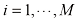 ),
),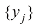 (其中
(其中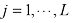 )。在本例中,我们有
)。在本例中,我们有 和
和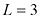 。如果这两个变量的总实例数为
。如果这两个变量的总实例数为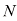 ,那么我们用
,那么我们用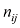 表示
表示 且
且 的实例数,即对应数组单元格中的点数。与
的实例数,即对应数组单元格中的点数。与 ,与
,与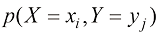 表示,称为
表示,称为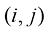 单元格中的点数占总点数的比例给出,即
单元格中的点数占总点数的比例给出,即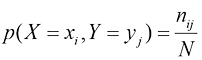 (1.5)
(1.5) 。同样,X取值
。同样,X取值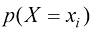 ,由落在第i列的点数占总点数的比例给出,即
,由落在第i列的点数占总点数的比例给出,即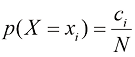 (1.6)
(1.6)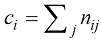 。另外,从式(1.5)和式(1.6)中,我们可以推导出如下关系:
。另外,从式(1.5)和式(1.6)中,我们可以推导出如下关系: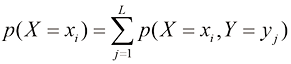 (1.7)
(1.7)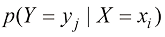 ,它被称为给定
,它被称为给定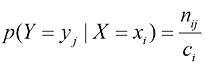 (1.8)
(1.8)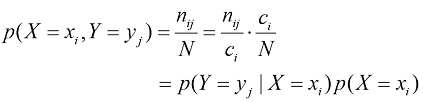 (1.9)
(1.9)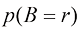 。虽然这样做有助于避免歧义,但却导致符号过于烦琐,而在许多情况下并不需要这么严苛。相反,我们可以简单地用
。虽然这样做有助于避免歧义,但却导致符号过于烦琐,而在许多情况下并不需要这么严苛。相反,我们可以简单地用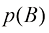 来表示随机变量B的分布,或用
来表示随机变量B的分布,或用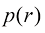 来表示特定值r下的分布,只要从上下文中能清楚其含义即可。
来表示特定值r下的分布,只要从上下文中能清楚其含义即可。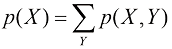 (1.10)
(1.10)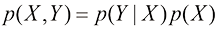 (1.11)
(1.11)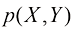 是联合概率,表示“X与Y同时发生的概率”。同样,
是联合概率,表示“X与Y同时发生的概率”。同样,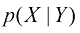 是条件概率,表示“在X发生的条件下Y发生的概率”;而
是条件概率,表示“在X发生的条件下Y发生的概率”;而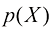 是边缘概率,表示“X发生的概率”。这两个简单的概率法则构成了我们在本书中使用的所有概率工具的基础。
是边缘概率,表示“X发生的概率”。这两个简单的概率法则构成了我们在本书中使用的所有概率工具的基础。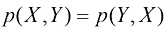 ,我们马上就能得到条件概率之间的如下关系:
,我们马上就能得到条件概率之间的如下关系: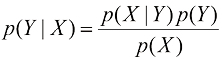 (1.12)
(1.12)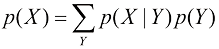 (1.13)
(1.13) 个数据点的有限样本,右上图是Y的两种取值中每个值的数据点比例的直方图。根据概率的定义,在
个数据点的有限样本,右上图是Y的两种取值中每个值的数据点比例的直方图。根据概率的定义,在 的情况下,这些比例等于相应的概率
的情况下,这些比例等于相应的概率 。我们可以把直方图看作一种简单的概率分布建模方法,只需要从该分布中抽取有限数量的点即可。从数据中建立分布模型是统计模式识别的核心,本书将对此进行详细探讨。图1.11中的其余两个图形显示了
。我们可以把直方图看作一种简单的概率分布建模方法,只需要从该分布中抽取有限数量的点即可。从数据中建立分布模型是统计模式识别的核心,本书将对此进行详细探讨。图1.11中的其余两个图形显示了 的相应直方图估计值。
的相应直方图估计值。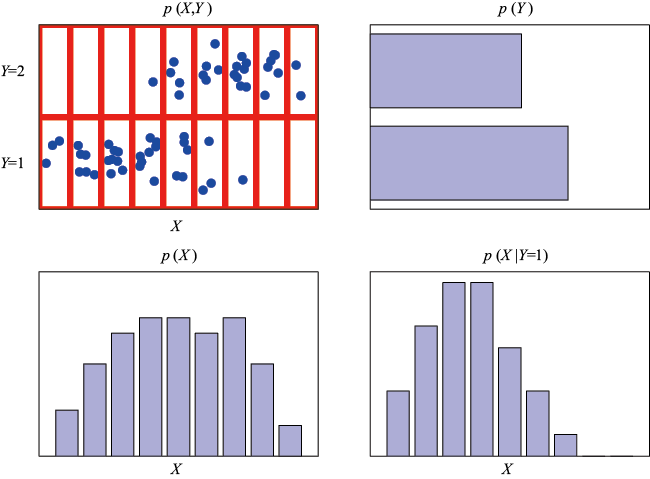
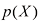 和
和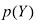 的直方图估计值,以及与左上图最下面一行相对应的条件分布
的直方图估计值,以及与左上图最下面一行相对应的条件分布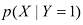
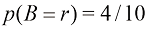 (1.14)
(1.14) (1.15)
(1.15) 。
。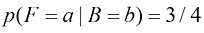 。事实上,我们可以写出给定所选盒子中水果类型的全部4个条件概率:
。事实上,我们可以写出给定所选盒子中水果类型的全部4个条件概率: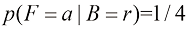 (1.16)
(1.16)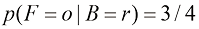 (1.17)
(1.17)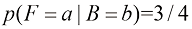 (1.18)
(1.18)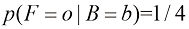 (1.19)
(1.19)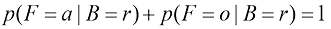 (1.20)
(1.20) (1.21)
(1.21) (1.22)
(1.22) 。
。 (1.23)
(1.23)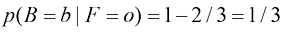 。
。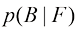 ,我们称之为后验概率(posterior probability),因为这是我们观察到F之后得到的概率。注意,在这个例子中,选择红色盒子的先验概率是4/10,所以我们更有可能选择蓝色盒子。然而,一旦我们观察到所选水果是橙子,就会发现红色盒子的后验概率现在是2/3,因此现在更有可能选择的其实是红色盒子。这一结果符合我们的直觉,因为红色盒子中橙子的比例远高于蓝色盒子中橙子的比例,因此观察到水果是橙子提供了有利于红色盒子的重要证据。事实上,该证据足够有力,以至于超过了先验概率,使得选择红色盒子比选择蓝色盒子的可能性更大。
,我们称之为后验概率(posterior probability),因为这是我们观察到F之后得到的概率。注意,在这个例子中,选择红色盒子的先验概率是4/10,所以我们更有可能选择蓝色盒子。然而,一旦我们观察到所选水果是橙子,就会发现红色盒子的后验概率现在是2/3,因此现在更有可能选择的其实是红色盒子。这一结果符合我们的直觉,因为红色盒子中橙子的比例远高于蓝色盒子中橙子的比例,因此观察到水果是橙子提供了有利于红色盒子的重要证据。事实上,该证据足够有力,以至于超过了先验概率,使得选择红色盒子比选择蓝色盒子的可能性更大。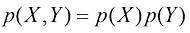 ,则称X和Y相互独立(independent)。根据概率的乘积法则,可以得到
,则称X和Y相互独立(independent)。根据概率的乘积法则,可以得到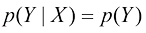 ,因此在给定X的条件下,Y的条件分布确实与X的值无关。例如,在我们的水果盒示例中,如果每个盒子中苹果和橙子的比例相同,那么
,因此在给定X的条件下,Y的条件分布确实与X的值无关。例如,在我们的水果盒示例中,如果每个盒子中苹果和橙子的比例相同,那么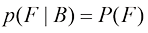 ,因此选择苹果的概率与选择哪个盒子无关。
,因此选择苹果的概率与选择哪个盒子无关。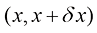 的概率在
的概率在 时由
时由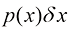 给出,则称
给出,则称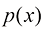 为x的概率密度(probability density)。这在图1.12中有所展示。x位于区间(a, b)的概率由下式给出:
为x的概率密度(probability density)。这在图1.12中有所展示。x位于区间(a, b)的概率由下式给出: (1.24)
(1.24)
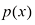 ,当
,当 时,x位于区间
时,x位于区间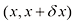 的概率为
的概率为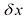 。概率密度可以表示为累积分布函数
。概率密度可以表示为累积分布函数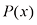 的导数
的导数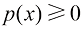 (1.25)
(1.25)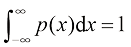 (1.26)
(1.26)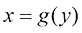 的变化,那么函数
的变化,那么函数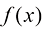 就会变成
就会变成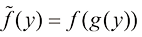 。现在考虑对应于新变量y的概率密度
。现在考虑对应于新变量y的概率密度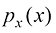 ,记作
,记作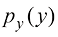 ,其中下标表示
,其中下标表示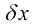 值,处于
值,处于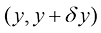 范围内的观测值,其中
范围内的观测值,其中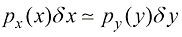 ,即
,即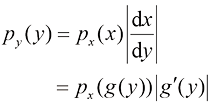 (1.27)
(1.27)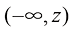 的概率由下式定义的累积分布函数(cumulative distribution function)给出:
的概率由下式定义的累积分布函数(cumulative distribution function)给出: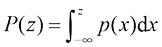 (1.28)
(1.28)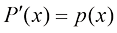 ,如图1.12所示。
,如图1.12所示。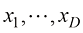 ,统记为x,则我们可以定义一个联合概率密度
,统记为x,则我们可以定义一个联合概率密度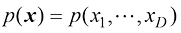 ,使得x落在包含点x的无穷小体积
,使得x落在包含点x的无穷小体积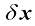 中的概率为
中的概率为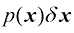 。这个多元概率密度必须满足
。这个多元概率密度必须满足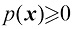 (1.29)
(1.29)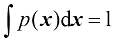 (1.30)
(1.30)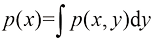 (1.31)
(1.31)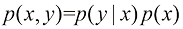 (1.32)
(1.32) 的区间,并考虑这些区间上的离散概率分布,可以非形式化地看出其有效性。取极限
的区间,并考虑这些区间上的离散概率分布,可以非形式化地看出其有效性。取极限 就可以将加和转为积分,从而得到所需的结果。
就可以将加和转为积分,从而得到所需的结果。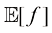 。对于离散分布,期望表示为
。对于离散分布,期望表示为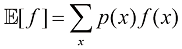 (1.33)
(1.33)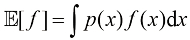 (1.34)
(1.34)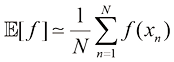 (1.35)
(1.35)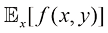 (1.36)
(1.36)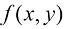 关于
关于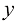 的一个函数。
的一个函数。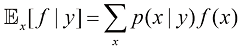 (1.37)
(1.37)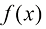 的方差(variance)定义为
的方差(variance)定义为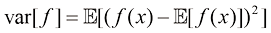 (1.38)
(1.38)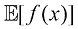 附近的变化程度。将平方项展开后,我们看到方差也可以用
附近的变化程度。将平方项展开后,我们看到方差也可以用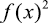 的期望来表示(见习题1.5):
的期望来表示(见习题1.5):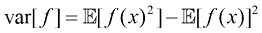 (1.39)
(1.39)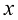 自身的方差,其表示为
自身的方差,其表示为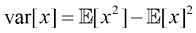 (1.40)
(1.40)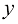 ,协方差(covariance)定义为
,协方差(covariance)定义为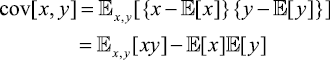 (1.41)
(1.41)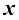 和
和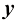 ,它们的协方差是一个矩阵:
,它们的协方差是一个矩阵: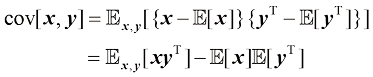 (1.42)
(1.42)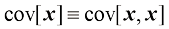 来表示。
来表示。 的随机值似乎是合理的。然而,我们希望解决并量化围绕模型参数
的随机值似乎是合理的。然而,我们希望解决并量化围绕模型参数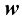 适当选择的不确定性。我们将看到,从贝叶斯理论的角度来看,我们可以使用概率论的机制来描述模型参数(如
适当选择的不确定性。我们将看到,从贝叶斯理论的角度来看,我们可以使用概率论的机制来描述模型参数(如
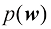 的形式捕捉我们对
的形式捕捉我们对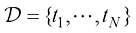 的影响通过条件概率
的影响通过条件概率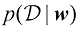 来表示,我们将在1.2.5小节中看到如何明确地表示这一点。贝叶斯定理的形式为
来表示,我们将在1.2.5小节中看到如何明确地表示这一点。贝叶斯定理的形式为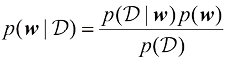 (1.43)
(1.43)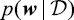 的形式来评估观测到
的形式来评估观测到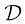 之后
之后 (1.44)
(1.44)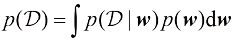 (1.45)
(1.45) 个数据点
个数据点 构成。我们可以通过从
构成。我们可以通过从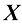 中随机抽取
中随机抽取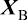 ,并在其中有放回地抽取点,这样
,并在其中有放回地抽取点,这样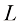 次,生成
次,生成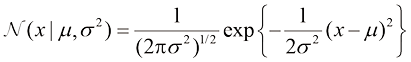 (1.46)
(1.46)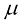 ,称为均值(mean);
,称为均值(mean);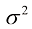 ,称为方差(variance)。方差的平方根
,称为方差(variance)。方差的平方根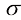 称为标准差(standard deviation),方差的倒数
称为标准差(standard deviation),方差的倒数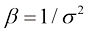 称为精度(precision)。我们很快就会介绍这些术语的含义。图1.13给出了高斯分布的图形。
称为精度(precision)。我们很快就会介绍这些术语的含义。图1.13给出了高斯分布的图形。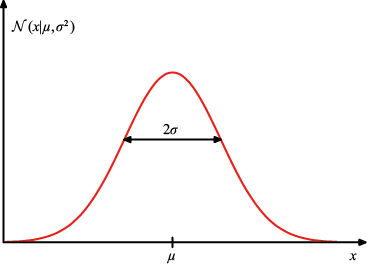
 和标准差
和标准差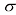 的一元高斯分布
的一元高斯分布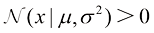 (1.47)
(1.47)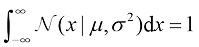 (1.48)
(1.48)
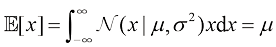 (1.49)
(1.49)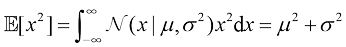 (1.50)
(1.50)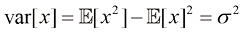 (1.51)
(1.51)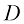 维连续变量向量
维连续变量向量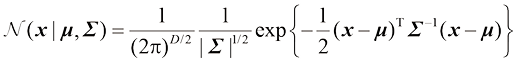 (1.52)
(1.52)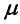 称为均值,
称为均值,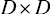 矩阵
矩阵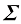 称为协方差矩阵,
称为协方差矩阵,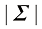 表示
表示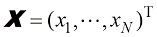 ,代表标量变量
,代表标量变量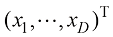 的单个观测值用
的单个观测值用 表示。我们假设这些观测值是独立地从高斯分布中抽取的,其均值
表示。我们假设这些观测值是独立地从高斯分布中抽取的,其均值 是独立同分布的,因此可以写出给定
是独立同分布的,因此可以写出给定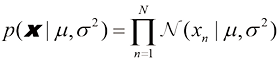 (1.53)
(1.53)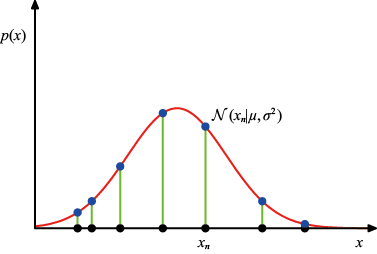
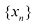 ,式(1.53)给出的似然函数对应于蓝色值的乘积。最大化似然涉及调整高斯分布的均值和方差,以最大化该乘积
,式(1.53)给出的似然函数对应于蓝色值的乘积。最大化似然涉及调整高斯分布的均值和方差,以最大化该乘积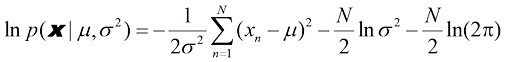 (1.54)
(1.54)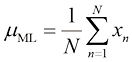 (1.55)
(1.55) 的平均值。类似地,通过最大化式(1.54)与
的平均值。类似地,通过最大化式(1.54)与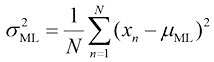 (1.56)
(1.56)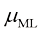 的样本方差(sample variance)。需要注意的是,我们是针对
的样本方差(sample variance)。需要注意的是,我们是针对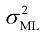 是数据集值
是数据集值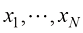 的函数。考虑这些值相对于数据集值的期望值,数据集值本身来自参数为
的函数。考虑这些值相对于数据集值的期望值,数据集值本身来自参数为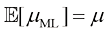 (1.57)
(1.57) (1.58)
(1.58) 。图1.15给出了这一结果背后的机理。
。图1.15给出了这一结果背后的机理。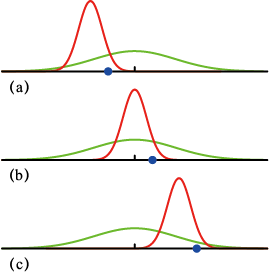
 (1.59)
(1.59) 的情况下,方差的最大似然结果等于产生数据的分布的真实方差。在实践中,对于
的情况下,方差的最大似然结果等于产生数据的分布的真实方差。在实践中,对于 及其对应的目标值
及其对应的目标值 组成的训练数据的基础上,根据输入变量
组成的训练数据的基础上,根据输入变量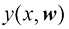 的高斯分布。因此,我们有
的高斯分布。因此,我们有 (1.60)
(1.60) ,对应于分布的逆方差。图1.16举例说明了这一点。
,对应于分布的逆方差。图1.16举例说明了这一点。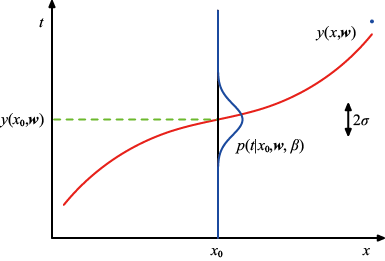
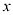 的
的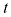 的高斯条件分布示意图,其中均值由多项式函数
的高斯条件分布示意图,其中均值由多项式函数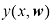 给定,精度由参数
给定,精度由参数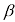 给定,
给定,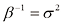
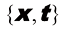 ,通过最大似然法确定未知参数
,通过最大似然法确定未知参数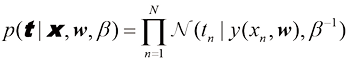 (1.61)
(1.61)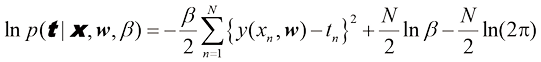 (1.62)
(1.62)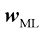 。它们可以通过对
。它们可以通过对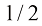 代替系数
代替系数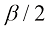 。最后,我们可以用最小化负对数似然来代替最大化对数似然。就确定
。最后,我们可以用最小化负对数似然来代替最大化对数似然。就确定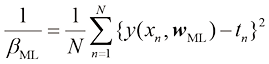 (1.63)
(1.63)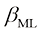 ,就像简单高斯分布那样(参见1.2.4小节)。
,就像简单高斯分布那样(参见1.2.4小节)。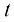 上概率分布的预测分布(predictive distribution)来表示,而不是进行简单的点估计,将最大似然参数代入式(1.60)可以得到
上概率分布的预测分布(predictive distribution)来表示,而不是进行简单的点估计,将最大似然参数代入式(1.60)可以得到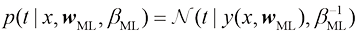 (1.64)
(1.64)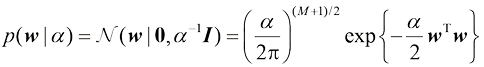 (1.65)
(1.65) 是分布的精度,
是分布的精度, 是
是 阶多项式的向量
阶多项式的向量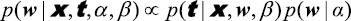 (1.66)
(1.66)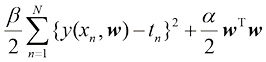 (1.67)
(1.67)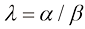 。
。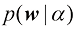 ,但到目前为止,我们仍在对
,但到目前为止,我们仍在对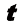 ,以及一个新的测试点
,以及一个新的测试点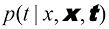 。在此,我们假设参数
。在此,我们假设参数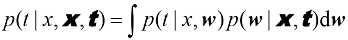 (1.68)
(1.68)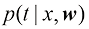 由式(1.60)给出,为了简化记号,我们省略了对
由式(1.60)给出,为了简化记号,我们省略了对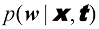 是参数的后验分布,可以通过对式(1.66)的右侧进行归一化求得。我们将在3.3节中看到,对于曲线拟合等问题,后验分布是高斯分布,可以通过分析求得。同样,式(1.68)中的积分也可以通过分析求得,其结果是预测分布由形式如下的高斯分布给出:
是参数的后验分布,可以通过对式(1.66)的右侧进行归一化求得。我们将在3.3节中看到,对于曲线拟合等问题,后验分布是高斯分布,可以通过分析求得。同样,式(1.68)中的积分也可以通过分析求得,其结果是预测分布由形式如下的高斯分布给出: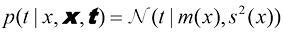 (1.69)
(1.69)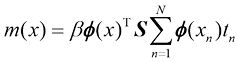 (1.70)
(1.70)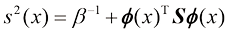 (1.71)
(1.71)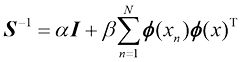 (1.72)
(1.72)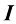 是单位矩阵,我们定义了元素为
是单位矩阵,我们定义了元素为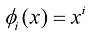 的向量
的向量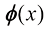 ,其中
,其中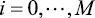 。
。 来表示的。然而,式(1.71)中右侧的第二项源于参数
来表示的。然而,式(1.71)中右侧的第二项源于参数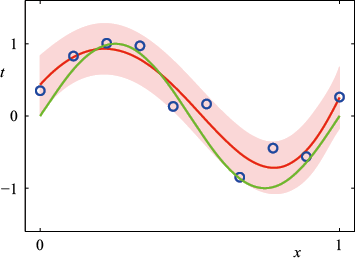
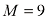 阶的多项式对多项式曲线拟合进行贝叶斯处理后的预测分布,其中固定参数
阶的多项式对多项式曲线拟合进行贝叶斯处理后的预测分布,其中固定参数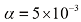 和
和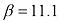 (对应已知噪声方差),红色曲线表示预测分布的平均值,红色区域对应平均值周围
(对应已知噪声方差),红色曲线表示预测分布的平均值,红色区域对应平均值周围 标准差的波动范围
标准差的波动范围 也控制着模型的有效复杂度;而对于更复杂的模型,如混合分布或神经网络,则可能有多个参数控制着模型复杂度。在实际应用中,我们需要确定这些参数的值,这样做的主要目的通常是在新数据上获得最佳预测性能。此外,除了在给定模型中找到复杂度参数的适当值外,我们可能还希望考虑一系列不同类型的模型,以找到最适合特定应用的模型。
也控制着模型的有效复杂度;而对于更复杂的模型,如混合分布或神经网络,则可能有多个参数控制着模型复杂度。在实际应用中,我们需要确定这些参数的值,这样做的主要目的通常是在新数据上获得最佳预测性能。此外,除了在给定模型中找到复杂度参数的适当值外,我们可能还希望考虑一系列不同类型的模型,以找到最适合特定应用的模型。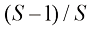 比例用于训练,同时利用所有数据来评估模型性能。当数据特别稀缺时,可以考虑
比例用于训练,同时利用所有数据来评估模型性能。当数据特别稀缺时,可以考虑 的情况,其中
的情况,其中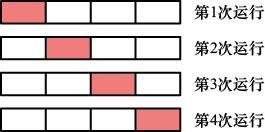
 的情况为例进行说明)涉及获取可用数据并将其划分为
的情况为例进行说明)涉及获取可用数据并将其划分为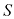 组(在最简单的情况下,这些组的大小相等)。用其中的
组(在最简单的情况下,这些组的大小相等)。用其中的 组来训练一组模型,然后在剩余的组上对这些模型进行评估。对所有
组来训练一组模型,然后在剩余的组上对这些模型进行评估。对所有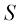 倍,这对于训练本身计算成本较高的模型来说可能会带来问题。交叉验证等使用单独数据评估性能的技术还有一个问题,那就是可能会为单个模型设置多个复杂度参数(例如,可能有多个正则化参数)。在最坏的情况下,探索这些参数的设置组合可能需要的训练次数与参数数量成指数关系。显然,我们需要一种更好的方法。理想情况下,这种方法应该只依赖于训练数据,并允许在一次训练运行中对多个超参数和模型类型进行比较。因此,我们需要找到一种只依赖于训练数据,并且不会因过度拟合而产生偏差的性能测量方法。
倍,这对于训练本身计算成本较高的模型来说可能会带来问题。交叉验证等使用单独数据评估性能的技术还有一个问题,那就是可能会为单个模型设置多个复杂度参数(例如,可能有多个正则化参数)。在最坏的情况下,探索这些参数的设置组合可能需要的训练次数与参数数量成指数关系。显然,我们需要一种更好的方法。理想情况下,这种方法应该只依赖于训练数据,并允许在一次训练运行中对多个超参数和模型类型进行比较。因此,我们需要找到一种只依赖于训练数据,并且不会因过度拟合而产生偏差的性能测量方法。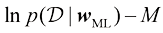 (1.73)
(1.73)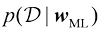 是最佳拟合对数似然,
是最佳拟合对数似然,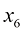 和
和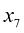 (图1.19忽略了其余10个输入值)。我们的目标是将这些数据作为训练集,以便能够对新的观测值
(图1.19忽略了其余10个输入值)。我们的目标是将这些数据作为训练集,以便能够对新的观测值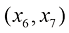 进行分类,见图1.19中叉号所示的观测值。我们可以观察到,该点周围有许多红色点,因此我们可能认为它属于红色类别。但是,该点附近也有很多绿色点,因此我们可能认为它属于绿色类别。看来它不太可能属于蓝色类别。我们的直觉是,该点的特征应该更多地由训练集中附近的点决定,而不是由较远的点决定。事实上,这种直觉是合理的,我们将在后面的章节中进行更充分的讨论。
进行分类,见图1.19中叉号所示的观测值。我们可以观察到,该点周围有许多红色点,因此我们可能认为它属于红色类别。但是,该点附近也有很多绿色点,因此我们可能认为它属于绿色类别。看来它不太可能属于蓝色类别。我们的直觉是,该点的特征应该更多地由训练集中附近的点决定,而不是由较远的点决定。事实上,这种直觉是合理的,我们将在后面的章节中进行更充分的讨论。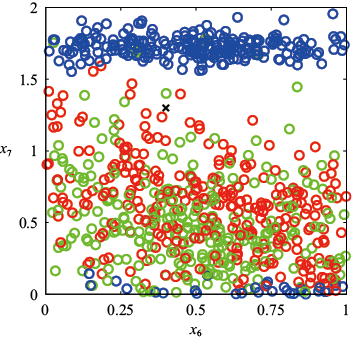
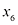 和
和 的油流数据集散点图,其中红色表示“均质”类,绿色表示“环状”类,蓝色表示“分层”类。我们的目标是对“
的油流数据集散点图,其中红色表示“均质”类,绿色表示“环状”类,蓝色表示“分层”类。我们的目标是对“ ”所表示的新测试点进行分类
”所表示的新测试点进行分类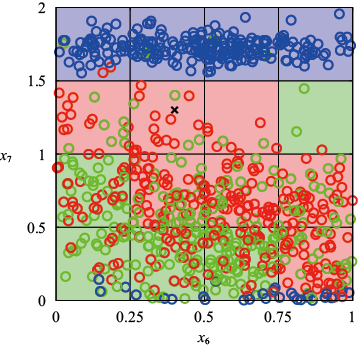
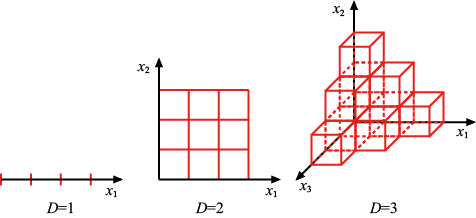
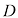 呈指数增长的。为清晰起见,这里只显示了
呈指数增长的。为清晰起见,这里只显示了 时的立方体区域子集
时的立方体区域子集 (1.74)
(1.74)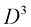 成比例增长。实际上,为了捕捉数据中的复杂依赖关系,我们可能需要使用更高阶的多项式。对于
成比例增长。实际上,为了捕捉数据中的复杂依赖关系,我们可能需要使用更高阶的多项式。对于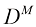 相似(见习题1.16)。虽然呈幂律增长而非指数增长,但这仍表明该方法正迅速变得难以使用,因而实用性有限。
相似(见习题1.16)。虽然呈幂律增长而非指数增长,但这仍表明该方法正迅速变得难以使用,因而实用性有限。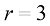 的球体,请问,位于半径
的球体,请问,位于半径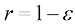 和半径
和半径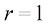 之间的部分在球的总体积中占比多少?我们可以通过留意半径为
之间的部分在球的总体积中占比多少?我们可以通过留意半径为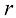 的球体在
的球体在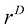 缩放来计算这个占比,因此可以写出
缩放来计算这个占比,因此可以写出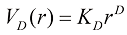 (1.75)
(1.75) 仅取决于
仅取决于 (1.76)
(1.76) 的值很小,这个占比也趋近于1。因此,在高维空间中,球体的大部分体积集中在球体表面附近的薄壳中!
的值很小,这个占比也趋近于1。因此,在高维空间中,球体的大部分体积集中在球体表面附近的薄壳中!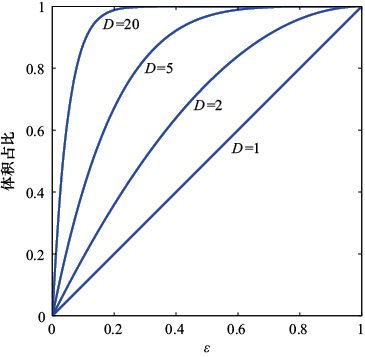
 和半径
和半径 之间的体积占比图
之间的体积占比图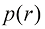 作为从原点算起的半径
作为从原点算起的半径 是位于半径
是位于半径 的薄壳内的概率质量。图1.23是不同
的薄壳内的概率质量。图1.23是不同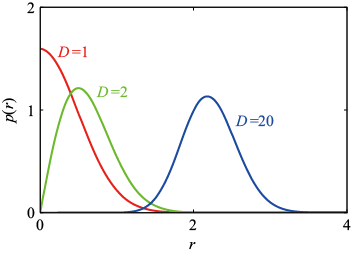
 的概率密度图示,其显示了不同维度
的概率密度图示,其显示了不同维度 ,我们的目标是根据
,我们的目标是根据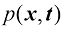 提供了与这些变量相关的不确定性的完整总结。从一组训练数据中确定
提供了与这些变量相关的不确定性的完整总结。从一组训练数据中确定 类来表示病人未患癌症,而用
类来表示病人未患癌症,而用 类来表示病人患有癌症。我们可以选择
类来表示病人患有癌症。我们可以选择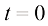 就对应
就对应 就对应
就对应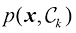 ,其等价于
,其等价于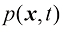 ,它给了我们对情况最完整的概率描述。尽管这可能是一个非常有用的信息,但最终我们必须决定是否对病人进行治疗,而且我们希望这种选择在某种适当的意义上是最优的(Duda and Hart,1973)。这就是决策(decision)环节,决策论的主题就是告诉我们如何在适当的概率条件下做出最优决策。我们将看到,一旦解决了推断问题,决策环节通常非常简单,甚至毫不费力。
,它给了我们对情况最完整的概率描述。尽管这可能是一个非常有用的信息,但最终我们必须决定是否对病人进行治疗,而且我们希望这种选择在某种适当的意义上是最优的(Duda and Hart,1973)。这就是决策(decision)环节,决策论的主题就是告诉我们如何在适当的概率条件下做出最优决策。我们将看到,一旦解决了推断问题,决策环节通常非常简单,甚至毫不费力。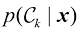 。利用贝叶斯定理,这个概率可以表示为
。利用贝叶斯定理,这个概率可以表示为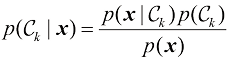 (1.77)
(1.77)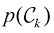 解释为类别
解释为类别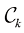 的先验概率,把
的先验概率,把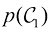 表示在我们进行X光检测之前,一个人患癌症的概率。同样,
表示在我们进行X光检测之前,一个人患癌症的概率。同样,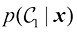 是根据X光影像中包含的信息使用贝叶斯定理修正后的相应概率。如果我们的目标是尽量降低将
是根据X光影像中包含的信息使用贝叶斯定理修正后的相应概率。如果我们的目标是尽量降低将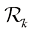 个区域,称为决策区域(decision region),每个类别一个决策区域,这样
个区域,称为决策区域(decision region),每个类别一个决策区域,这样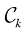 中。决策区域之间的边界称为决策边界(decision boundary)或决策面(decision surface)。需要注意的是,每个决策区域不一定是连续的,也可以由若干不相交的区域组成。在后面的章节中,我们还会遇到决策边界和决策区域的例子。为了找到最优决策规则,首先考虑两个类别的情况,就像前述的癌症问题那样。当属于
中。决策区域之间的边界称为决策边界(decision boundary)或决策面(decision surface)。需要注意的是,每个决策区域不一定是连续的,也可以由若干不相交的区域组成。在后面的章节中,我们还会遇到决策边界和决策区域的例子。为了找到最优决策规则,首先考虑两个类别的情况,就像前述的癌症问题那样。当属于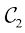 类时,就会发生错误,反之亦然。这种情况发生的概率为
类时,就会发生错误,反之亦然。这种情况发生的概率为 (1.78)
(1.78) (错误),我们应该把每个
(错误),我们应该把每个 大于
大于 ,我们就应该把
,我们就应该把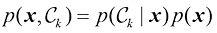 。由于因子
。由于因子 在比较过程中具有共通性,因此可以把这个结果重述如下:如果把
在比较过程中具有共通性,因此可以把这个结果重述如下:如果把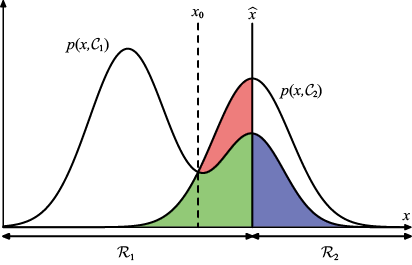
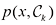 与
与 的示意图。
的示意图。 的点被归为
的点被归为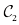 类,因此属于决策区域
类,因此属于决策区域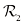 ;而
;而 的点被归为
的点被归为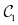 类,属于决策区域
类,属于决策区域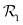 。误差来自蓝色、绿色和红色区域,因此对于
。误差来自蓝色、绿色和红色区域,因此对于 位置时,蓝色和绿色区域的总面积保持不变,而红色区域的面积则会变化。
位置时,蓝色和绿色区域的总面积保持不变,而红色区域的面积则会变化。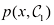 和
和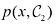 的曲线交叉处,即
的曲线交叉处,即 处,因为在这种情况下红色区域会消失。这等价于最小误分类率决策规则,它将
处,因为在这种情况下红色区域会消失。这等价于最小误分类率决策规则,它将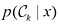 较高的类别
较高的类别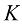 个类别的更一般情况,使正确概率最大化稍微容易一些,其公式为
个类别的更一般情况,使正确概率最大化稍微容易一些,其公式为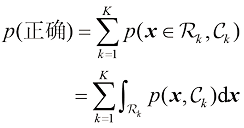 (1.79)
(1.79)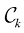 ,而我们将
,而我们将 (这里的
(这里的 可能等于也可能不等于
可能等于也可能不等于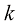 )。在此过程中,我们会产生一定程度的损失,用
)。在此过程中,我们会产生一定程度的损失,用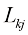 表示,我们可以将其视为损失矩阵(loss matrix)的
表示,我们可以将其视为损失矩阵(loss matrix)的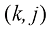 元素。例如,在癌症诊断的例子中,我们可能会有一个图1.25所示形式的损失矩阵。这个特定的损失矩阵表示,如果诊断正确,则不会产生任何损失;如果健康的人被误诊为患有癌症,则损失为1;而如果癌症病人被诊断为身体正常,则损失为1000。
元素。例如,在癌症诊断的例子中,我们可能会有一个图1.25所示形式的损失矩阵。这个特定的损失矩阵表示,如果诊断正确,则不会产生任何损失;如果健康的人被误诊为患有癌症,则损失为1;而如果癌症病人被诊断为身体正常,则损失为1000。
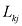 的损失矩阵示例。行对应于真实类别,列对应于我们的决策规则所做的类别分配
的损失矩阵示例。行对应于真实类别,列对应于我们的决策规则所做的类别分配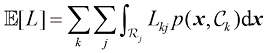 (1.80)
(1.80)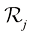 。我们的目标是选择
。我们的目标是选择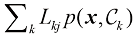 。与之前一样,我们可以使用概率的乘积法则
。与之前一样,我们可以使用概率的乘积法则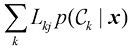 (1.81)
(1.81)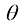 ,并拒绝那些后验类别概率
,并拒绝那些后验类别概率 将确保所有样本都被拒绝,而如果有
将确保所有样本都被拒绝,而如果有 将能够确保没有样本被拒绝。因此,被拒绝样本的比例受
将能够确保没有样本被拒绝。因此,被拒绝样本的比例受
 ,则样本会被拒绝
,则样本会被拒绝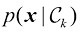 ,同时分别推断先验类别概率
,同时分别推断先验类别概率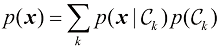 (1.83)
(1.83)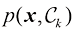 ,然后进行归一化处理,得到后验概率。找到后验概率后,我们就可以使用决策论来确定每个新输入x的类别成员。显式或隐式地建模输入输出分布的方法称为生成式模型(generative model),因为通过对它们进行采样,就可以在输入空间中生成合成数据。
,然后进行归一化处理,得到后验概率。找到后验概率后,我们就可以使用决策论来确定每个新输入x的类别成员。显式或隐式地建模输入输出分布的方法称为生成式模型(generative model),因为通过对它们进行采样,就可以在输入空间中生成合成数据。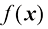 。例如,在二分类情况下,
。例如,在二分类情况下,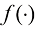 可能是二值函数,即
可能是二值函数,即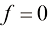 代表
代表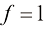 代表
代表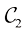 类。在这种情况下,概率不起任何作用。
类。在这种情况下,概率不起任何作用。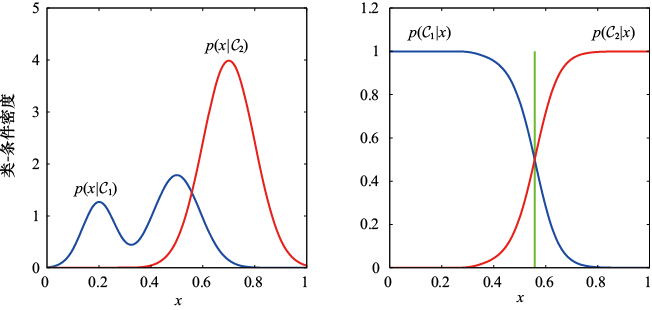
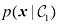 的左侧峰形对后验概率没有影响;右图中的垂直绿线显示的是
的左侧峰形对后验概率没有影响;右图中的垂直绿线显示的是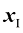 表示)和血液数据(用
表示)和血液数据(用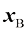 表示)的输入分布是独立的,因此
表示)的输入分布是独立的,因此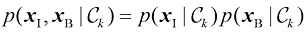 (1.84)
(1.84)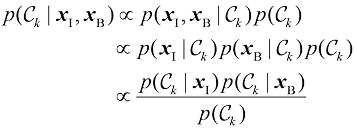 (1.85)
(1.85)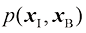 通常无法因式分解。在后面的章节中,我们将看到如何构建不需要条件独立性假设[见式(1.84)]的数据组合模型。
通常无法因式分解。在后面的章节中,我们将看到如何构建不需要条件独立性假设[见式(1.84)]的数据组合模型。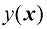 。设在此过程产生的损失为
。设在此过程产生的损失为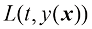 ,则平均损失或预期损失的计算公式为
,则平均损失或预期损失的计算公式为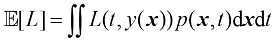 (1.86)
(1.86) 。在这种情况下,预期损失可以写成
。在这种情况下,预期损失可以写成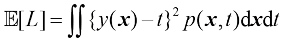 (1.87)
(1.87)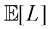 最小。如果我们假设
最小。如果我们假设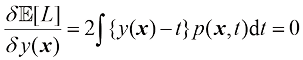 (1.88)
(1.88)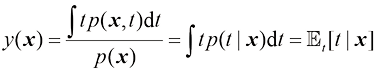 (1.89)
(1.89)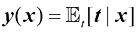 (见习题1.25)。
(见习题1.25)。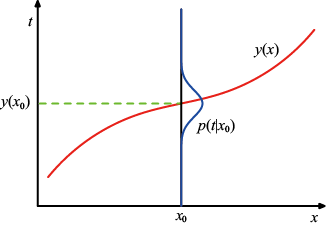
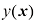 由条件分布
由条件分布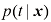 的均值给出,它能使预期平方损失最小化
的均值给出,它能使预期平方损失最小化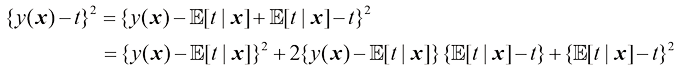
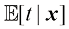 代表
代表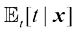 。代入损失函数并对
。代入损失函数并对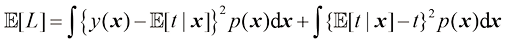 (1.90)
(1.90)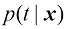 ,最后进行边缘化处理,求出式(1.89)所给出的条件均值。
,最后进行边缘化处理,求出式(1.89)所给出的条件均值。 (1.91)
(1.91) 时,闵可夫斯基损失可简化为预期平方损失。图1.29展示了不同
时,闵可夫斯基损失可简化为预期平方损失。图1.29展示了不同 值下
值下 与
与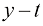 的关系曲线。
的关系曲线。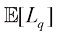 的最小值由
的最小值由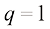 时的条件中值和
时的条件中值和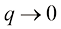 时的条件众数给出(见习题1.27)。
时的条件众数给出(见习题1.27)。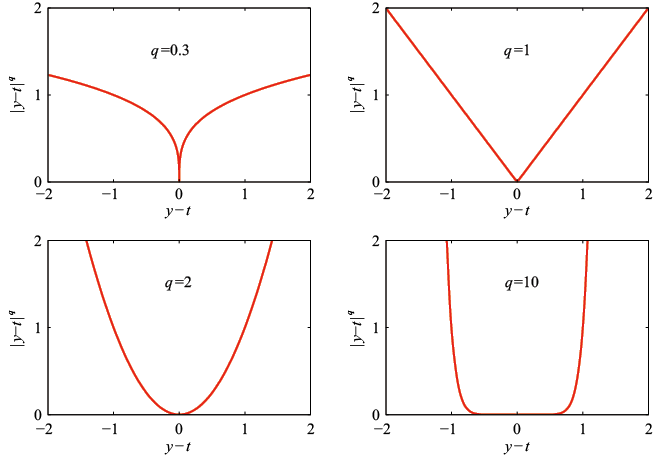
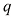 值下
值下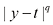 与
与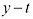 的关系曲线
的关系曲线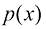 ,我们需要寻找一个与概率分布
,我们需要寻找一个与概率分布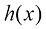 来表达信息含量。要找到
来表达信息含量。要找到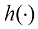 的形式,可以注意到,如果有两个互不相关的事件
的形式,可以注意到,如果有两个互不相关的事件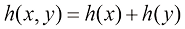 。两个不相关的事件在统计上是独立的,因此
。两个不相关的事件在统计上是独立的,因此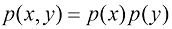 。根据这两个关系,可以很容易地看出
。根据这两个关系,可以很容易地看出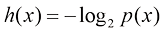 (1.92)
(1.92)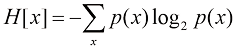 (1.93)
(1.93) ,因此只要我们遇到
,因此只要我们遇到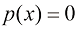 ,我们就取
,我们就取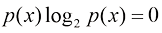 。
。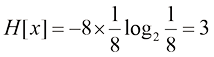 比特
比特
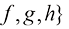 ,它们各自的概率分布为(1/2,1/4,1/8,1/16,1/64,1/64,1/64,1/64)。这种情况下的熵为
,它们各自的概率分布为(1/2,1/4,1/8,1/16,1/64,1/64,1/64,1/64)。这种情况下的熵为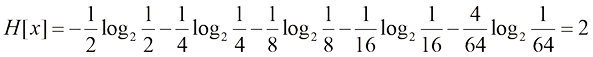 比特
比特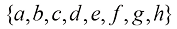 :0、10、110、1110、111100、111101、111110、111111。需要传输的代码的平均长度为
:0、10、110、1110、111100、111101、111110、111111。需要传输的代码的平均长度为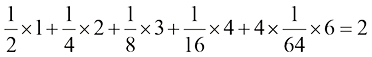 比特
比特 个箱子中就有
个箱子中就有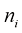 个物品。考虑将这些物品分配到各个箱子的不同方法的数量。选择第一个物品的方法有
个物品。考虑将这些物品分配到各个箱子的不同方法的数量。选择第一个物品的方法有 种,以此类推,共有
种,以此类推,共有 种。
种。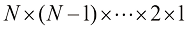 。不过,我们并不想区分各个箱子中的物品是否重新排列。在第
。不过,我们并不想区分各个箱子中的物品是否重新排列。在第 (1.94)
(1.94)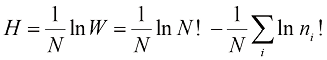 (1.95)
(1.95)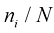 保持不变,应用斯特林近似公式:
保持不变,应用斯特林近似公式: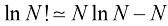 (1.96)
(1.96)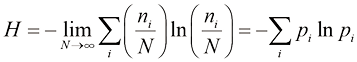 (1.97)
(1.97) ,这里
,这里 是物品被分配到第
是物品被分配到第 称为宏观状态的权重(weight)。
称为宏观状态的权重(weight)。 的状态
的状态 ,其中
,其中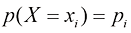 。随机变量
。随机变量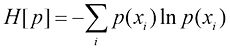 (1.98)
(1.98)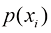 如果在几个值之间呈尖峰状,则熵相对较低;而如果在多个值之间较均匀,则熵较高。因为
如果在几个值之间呈尖峰状,则熵相对较低;而如果在多个值之间较均匀,则熵较高。因为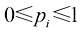 ,所以熵是非负的,当其中一个
,所以熵是非负的,当其中一个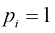 而其他所有
而其他所有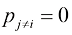 时,熵达到其最小值0(参见附录E)。因此,我们最大化
时,熵达到其最小值0(参见附录E)。因此,我们最大化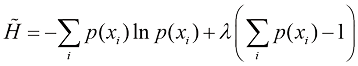 (1.99)
(1.99) ,其中
,其中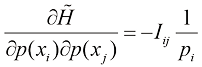 (1.100)
(1.100) 是单位矩阵的元素。
是单位矩阵的元素。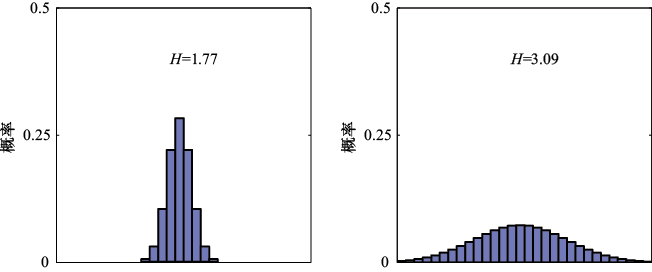
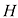 值较高。最大的熵来自均匀分布,即
值较高。最大的熵来自均匀分布,即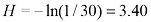
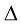 的分段,然后假定
的分段,然后假定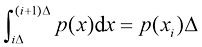 (1.101)
(1.101) 。这就得到了一个离散分布,其熵的形式为
。这就得到了一个离散分布,其熵的形式为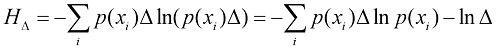 (1.102)
(1.102) ,这源于式(1.101)。现在我们省略式(1.102)右侧的第二项
,这源于式(1.101)。现在我们省略式(1.102)右侧的第二项 ,然后考虑极限
,然后考虑极限 。在这个极限下,式(1.102)右侧的第一项将接近
。在这个极限下,式(1.102)右侧的第一项将接近 的积分,因此
的积分,因此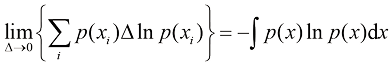 (1.103)
(1.103) ,在极限
,在极限 (1.104)
(1.104) (1.106)
(1.106) (1.107)
(1.107)
 来表示,其中
来表示,其中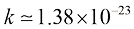 (单位:焦耳/开尔文),称为玻耳兹曼常数。玻尔兹曼的观点受到当时许多科学家的质疑。热力学第二定律指出,封闭系统的熵随时间呈上升趋势。相比之下,在微观层面,牛顿的经典物理学方程是可逆的,因此他们很难理解后者如何解释前者。
(单位:焦耳/开尔文),称为玻耳兹曼常数。玻尔兹曼的观点受到当时许多科学家的质疑。热力学第二定律指出,封闭系统的熵随时间呈上升趋势。相比之下,在微观层面,牛顿的经典物理学方程是可逆的,因此他们很难理解后者如何解释前者。
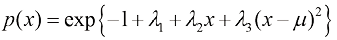 (1.108)
(1.108)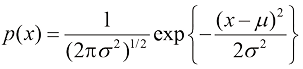 (1.109)
(1.109) (1.110)
(1.110)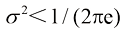 时,式(1.110)中的
时,式(1.110)中的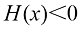 。
。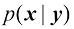 ,从中抽取
,从中抽取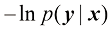 。因此,指定
。因此,指定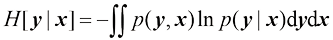 (1.111)
(1.111)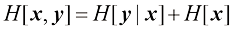 (1.112)
(1.112)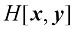 是
是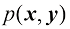 的微分熵,
的微分熵, 是边缘概率分布
是边缘概率分布
 对其进行建模。如果我们使用
对其进行建模。如果我们使用 (1.113)
(1.113)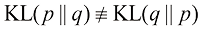 。
。 散度满足
散度满足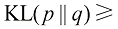 0,当且仅当
0,当且仅当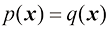 时等式成立。为此,我们首先引入凸(convex)函数的概念。如图1.31所示,如果函数
时等式成立。为此,我们首先引入凸(convex)函数的概念。如图1.31所示,如果函数 到
到 的区间内的任何
的区间内的任何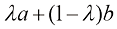 的形式,其中
的形式,其中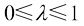 。弦上的相应点为
。弦上的相应点为 ,函数的相应值为
,函数的相应值为
 。因此,函数
。因此,函数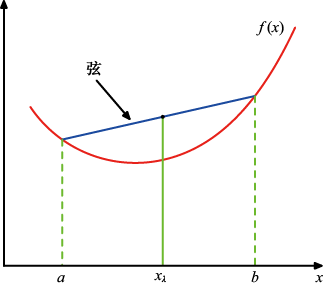
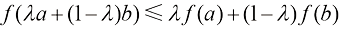 (1.114)
(1.114)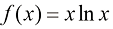 (对于
(对于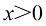 )和
)和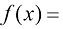
 (见习题1.36)。如果凸函数
(见习题1.36)。如果凸函数 和
和 时才满足相等关系,则称为严格凸(strictly convex)。如果函数具有相反的性质,即每条弦都位于函数曲线的下方或与之重合,则称为凹(concave)函数,严格凹(strictly concave)函数也有相应的定义。如果函数
时才满足相等关系,则称为严格凸(strictly convex)。如果函数具有相反的性质,即每条弦都位于函数曲线的下方或与之重合,则称为凹(concave)函数,严格凹(strictly concave)函数也有相应的定义。如果函数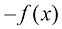 将是凹函数。
将是凹函数。 (1.115)
(1.115)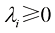 且
且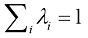 ,这适用于任意点集
,这适用于任意点集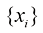 。式(1.115)被称为詹森不等式(Jensen’s inequality)。如果我们把
。式(1.115)被称为詹森不等式(Jensen’s inequality)。如果我们把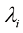 解释为离散变量
解释为离散变量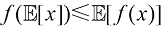 (1.116)
(1.116) 表示期望。对于连续变量,詹森不等式的形式为
表示期望。对于连续变量,詹森不等式的形式为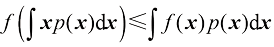 (1.117)
(1.117)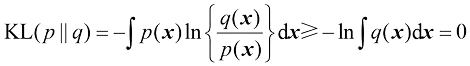 (1.118)
(1.118) 是凸函数这一事实,以及归一化条件
是凸函数这一事实,以及归一化条件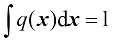 。事实上,
。事实上,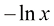 是一个严格凸函数,因此当且仅当
是一个严格凸函数,因此当且仅当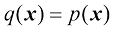 时,对于所有
时,对于所有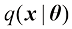 来近似这一分布,该分布受一组可调参数
来近似这一分布,该分布受一组可调参数 的控制,例如多元高斯分布。确定
的控制,例如多元高斯分布。确定 取自
取自 (1.119)
(1.119) 的乘积。如果变量集不是独立的,可以通过考虑联合分布与边缘分布乘积之间的
的乘积。如果变量集不是独立的,可以通过考虑联合分布与边缘分布乘积之间的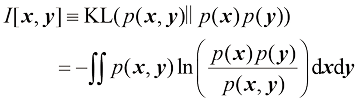 (1.120)
(1.120)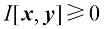 ,当且仅当变量集
,当且仅当变量集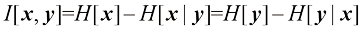 (1.121)
(1.121)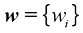 由以下线性方程组的解给出:
由以下线性方程组的解给出: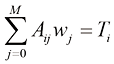 (1.122)
(1.122)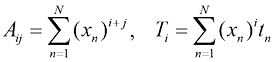 (1.123)
(1.123)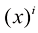 表示
表示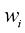 。
。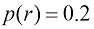 、
、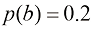 、
、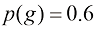 的概率随机选择一个盒子,并从盒子中取出一个水果(选择盒子中任意水果的概率都相等),那么选中苹果的概率是多少?如果我们发现选中的水果实际上是橙子,那么它来自绿色盒子的概率是多少?
的概率随机选择一个盒子,并从盒子中取出一个水果(选择盒子中任意水果的概率都相等),那么选中苹果的概率是多少?如果我们发现选中的水果实际上是橙子,那么它来自绿色盒子的概率是多少?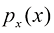 ,假设我们用
,假设我们用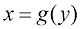 对变量进行非线性变换,概率密度将按照式(1.27)发生相应变化。通过对式(1.27)进行微分,证明
对变量进行非线性变换,概率密度将按照式(1.27)发生相应变化。通过对式(1.27)进行微分,证明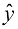 与
与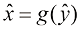 作为雅可比因子的结果。这表明概率密度的最大值(与简单函数不同)取决于变量的选择。证明在线性变换的情况下,概率密度最大值的位置与变量本身的变换方式相同。
作为雅可比因子的结果。这表明概率密度的最大值(与简单函数不同)取决于变量的选择。证明在线性变换的情况下,概率密度最大值的位置与变量本身的变换方式相同。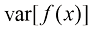 满足式(1.39)。
满足式(1.39)。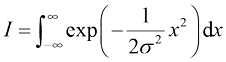 (1.124)
(1.124)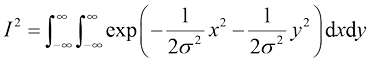 (1.125)
(1.125) 转换为极坐标
转换为极坐标 ,然后代入
,然后代入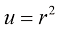 。证明对
。证明对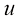 进行积分,然后取两边的平方根,即可得到
进行积分,然后取两边的平方根,即可得到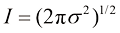 (1.126)
(1.126)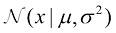 是归一化的。
是归一化的。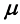 。
。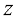 是统计独立的。证明二者之和的均值和方差满足
是统计独立的。证明二者之和的均值和方差满足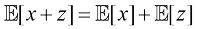 (1.128)
(1.128)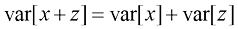 (1.129)
(1.129)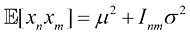 (1.130)
(1.130)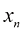 和
和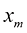 表示从均值为
表示从均值为 ,则
,则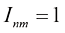 ,否则
,否则 ,从而证明式(1.57)和式(1.58)成立。
,从而证明式(1.57)和式(1.58)成立。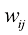 的任意方阵都可以写成
的任意方阵都可以写成 的形式,其中
的形式,其中 和
和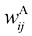 分别是对称矩阵和反对称矩阵,对于所有
分别是对称矩阵和反对称矩阵,对于所有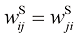 和
和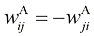 。现在考虑
。现在考虑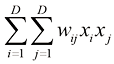 (1.131)
(1.131) (1.132)
(1.132) 元素并非都可以独立选择。证明
元素并非都可以独立选择。证明 。
。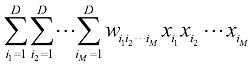 (1.133)
(1.133)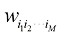 由
由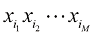 的许多互换对称性,独立参数的数量要少得多。证明系数中的冗余可以通过将这个
的许多互换对称性,独立参数的数量要少得多。证明系数中的冗余可以通过将这个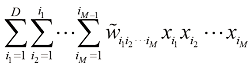 (1.134)
(1.134)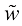 和
和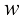 之间的精确关系无须明示。利用这一结果证明阶次为
之间的精确关系无须明示。利用这一结果证明阶次为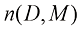 满足下面的递推关系:
满足下面的递推关系: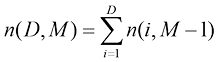 (1.135)
(1.135)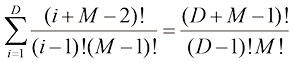 (1.136)
(1.136)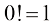 证明
证明 和任意
和任意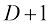 也正确。最后,利用前面的两个结果以及归纳法证明
也正确。最后,利用前面的两个结果以及归纳法证明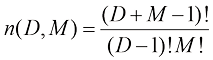 (1.137)
(1.137) 阶和任何
阶和任何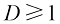 的维度都成立。然后利用式(1.135)和式(1.136)证明如果结果对于
的维度都成立。然后利用式(1.135)和式(1.136)证明如果结果对于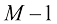 阶成立,那么该结果对于
阶成立,那么该结果对于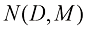 的计算公式。首先证明
的计算公式。首先证明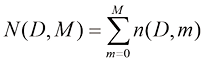 (1.138)
(1.138)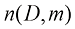 是第
是第 阶项中独立参数的个数。
阶项中独立参数的个数。 (1.139)
(1.139) 和任意维度(
和任意维度( )时成立,然后假设它在
)时成立,然后假设它在 值的情况下,利用斯特林近似公式
值的情况下,利用斯特林近似公式 (1.140)
(1.140) ,
, ,
, 相似。考虑一个
相似。考虑一个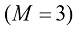 多项式,并对以下情况下的独立参数总数进行估计:(i)
多项式,并对以下情况下的独立参数总数进行估计:(i)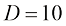 ;(ii)
;(ii)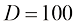 。这两种情况分别对应于典型的小规模和中规模机器学习应用。
。这两种情况分别对应于典型的小规模和中规模机器学习应用。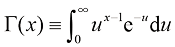 (1.141)
(1.141)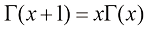 并证明
并证明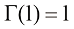 ,从而证明当
,从而证明当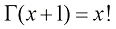 。
。 和体积
和体积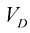 的计算公式。为此,可以考虑将笛卡儿坐标转换为极坐标后得到的以下结果:
的计算公式。为此,可以考虑将笛卡儿坐标转换为极坐标后得到的以下结果: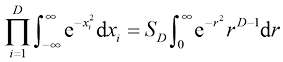 (1.142)
(1.142)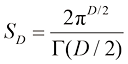 (1.143)
(1.143)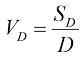 (1.144)
(1.144)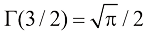 证明对于
证明对于 和
和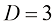 的情形,式(1.143)和式(1.144)可以简化为经典的表达式形式。
的情形,式(1.143)和式(1.144)可以简化为经典的表达式形式。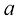 的
的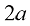 的同心超立方体,使球体与超立方体每边的中心相切。利用习题1.18的结果,证明球体的体积与超立方体的体积之比为
的同心超立方体,使球体与超立方体每边的中心相切。利用习题1.18的结果,证明球体的体积与超立方体的体积之比为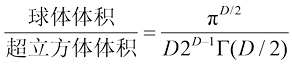 (1.145)
(1.145)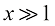 有效的斯特林近似公式
有效的斯特林近似公式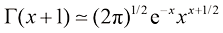 (1.146)
(1.146)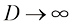 时,式(1.145)所示的比值趋近于零。
时,式(1.145)所示的比值趋近于零。 ,因此当
,因此当 (1.147)
(1.147) 、厚度为
、厚度为 的薄壳上的概率密度的积分由
的薄壳上的概率密度的积分由 给出,其中
给出,其中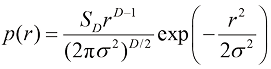 (1.148)
(1.148)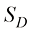 是
是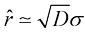 处。通过分析
处。通过分析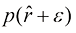 ,其中
,其中 ,证明对于大
,证明对于大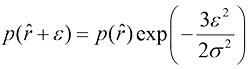 (1.149)
(1.149)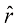 是径向概率密度的最大值,并且
是径向概率密度的最大值,并且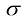 从
从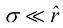 适用于大
适用于大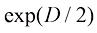 倍。由此可见,高维高斯分布中的大部分概率质量位于与高概率密度区域不同的半径位置。等到后续章节讨论模型参数的贝叶斯推断时,高维空间分布的这一特性将产生重要影响。
倍。由此可见,高维高斯分布中的大部分概率质量位于与高概率密度区域不同的半径位置。等到后续章节讨论模型参数的贝叶斯推断时,高维空间分布的这一特性将产生重要影响。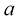 和
和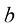 ,并证明如果
,并证明如果 ,那么
,那么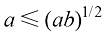 。用这一结果证明,如果二分类问题的决策区域的选择是为了最小化误分类的概率,那么这一概率将满足
。用这一结果证明,如果二分类问题的决策区域的选择是为了最小化误分类的概率,那么这一概率将满足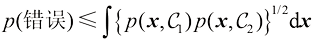 (1.150)
(1.150)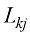 的损失矩阵,如果对于每个样本,我们选择的类别能使式(1.81)取最小值,则期望风险最小。证明当损失矩阵为
的损失矩阵,如果对于每个样本,我们选择的类别能使式(1.81)取最小值,则期望风险最小。证明当损失矩阵为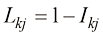 时(其中
时(其中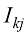 为单位矩阵的元素),这一准则退化为选择后验概率最大的类别。这种形式的损失矩阵作何解释?
为单位矩阵的元素),这一准则退化为选择后验概率最大的类别。这种形式的损失矩阵作何解释?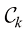 类的输入向量被分类为属于
类的输入向量被分类为属于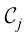 类时,所产生的损失由损失矩阵
类时,所产生的损失由损失矩阵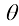 之间的关系是什么?
之间的关系是什么?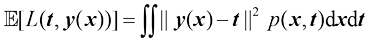 (1.151)
(1.151)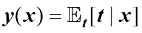 。证明在单一目标变量t的情况下,这一结果可简化为式(1.89)。
。证明在单一目标变量t的情况下,这一结果可简化为式(1.89)。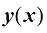 是由t的条件期望给出的。
是由t的条件期望给出的。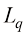 损失函数下回归问题的预期损失。写出
损失函数下回归问题的预期损失。写出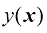 为了最小化
为了最小化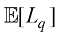 而必须满足的条件。证明对于
而必须满足的条件。证明对于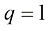 ,此解代表条件中位数,函数
,此解代表条件中位数,函数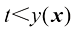 的概率质量与
的概率质量与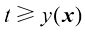 的概率质量相同。同时证明
的概率质量相同。同时证明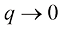 时的最小期望损失是由条件众数给出的,换言之,由对每个x最大化
时的最小期望损失是由条件众数给出的,换言之,由对每个x最大化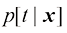 的
的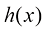 的概念,即通过观测具有分布
的概念,即通过观测具有分布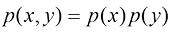 的自变量
的自变量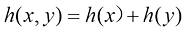 。下面我们以函数
。下面我们以函数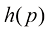 的形式推导
的形式推导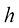 与
与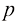 之间的关系。首先证明
之间的关系。首先证明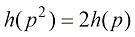 ,进而归纳出
,进而归纳出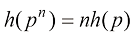 ,其中
,其中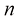 为正整数。由此进一步证明
为正整数。由此进一步证明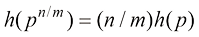 ,其中
,其中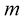 也是正整数。这意味着
也是正整数。这意味着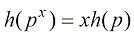 ,其中
,其中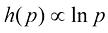 的形式。
的形式。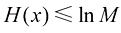 。
。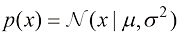 和
和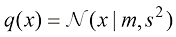 之间的
之间的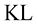 散度[见式(1.113)]。
散度[见式(1.113)]。 的两个向量x和y。证明这对向量的微分熵满足
的两个向量x和y。证明这对向量的微分熵满足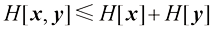 (1.152)
(1.152)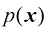 ,相应的熵为
,相应的熵为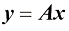 。证明相应的熵为
。证明相应的熵为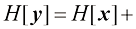
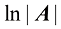 ,其中
,其中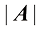 表示
表示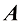 的行列式。
的行列式。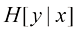 为零。证明对于所有
为零。证明对于所有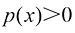 的
的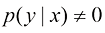 。
。 (c)
(c) (e)
(e)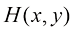
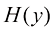 (d)
(d)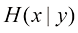 (f)
(f)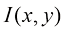
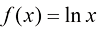 的詹森不等式[见式(1.115)],证明一组实数的算术平均数永远不会小于它们的几何平均数。
的詹森不等式[见式(1.115)],证明一组实数的算术平均数永远不会小于它们的几何平均数。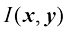 满足式(1.121)所示的关系。
满足式(1.121)所示的关系。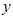 的联合分布
的联合分布