版权信息 书名:机器学习:算法原理与代码实现
ISBN:978-7-115-66000-8
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
版 权 著 童永清
责任编辑 刘雅思
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线: (010)81055410
反盗版热线: (010)81055315
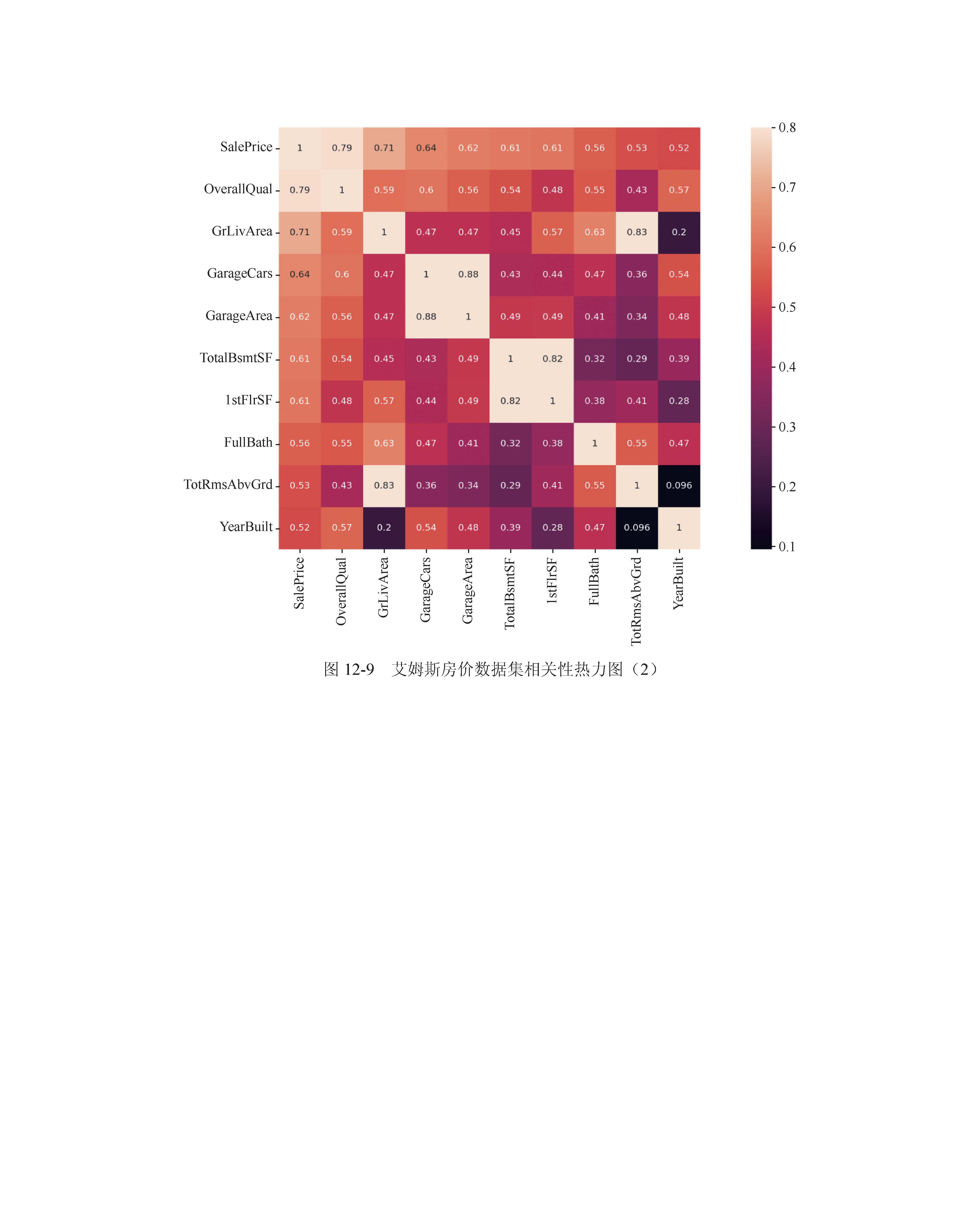
内 容 提 要 本书系统地介绍机器学习基础模型的算法原理与代码实现,是一本理论与实践并重的图书。
本书第1章介绍机器学习的基本概念、发展历程和主要应用等;第2章~第11章介绍监督学习,包括线性回归、感知机、逻辑斯谛回归与Softmax回归、正则化、线性判别分析、k 近邻、朴素贝叶斯、决策树、支持向量机、人工神经网络;第12章和第13章介绍特征工程、模型评估与选择等。
本书的读者对象为人工智能、计算机、大数据、自动化等专业的本科生,以及从事机器学习研究与开发工作的专业人员。本书可作为机器学习课程的教材或参考书,也可供人工智能领域的技术人员参考。
前 言 2016年,谷歌旗下DeepMind公司研发的AlphaGo战胜世界围棋冠军。在此前后,深度学习技术在人脸识别、语音识别等领域的表现超过了人类,深度学习技术从实验室走向商用。2023年,ChatGPT的惊艳表现和快速流行引发新一轮人工智能热潮,国内外厂商和研究机构迅速跟进,加强了人工智能(特别是机器学习)技术的研发力度,推出各自的大模型系统,通用人工智能时代已经来临。
人工智能正在引领“第四次工业革命”,人工智能将像电力、移动互联网一样,成为现代社会的基础设施和不可或缺的组成部分。谁掌握了人工智能的核心技术,谁就会在未来拥有主导权。而机器学习正是人工智能的核心技术和主要实现方法。
机器学习是人工智能专业的核心课程,也是计算机、大数据、自动化等专业的重要课程。市面上关于机器学习的图书很多,写作本书主要是为了降低机器学习的学习难度,让更多的科研人员掌握机器学习的底层原理,为中国人工智能事业的发展和进步贡献一点微薄的力量。我们不应只满足于使用别人制造的“轮子”,而要自己掌握如何改进别人制造的“轮子”甚至制造自己的“轮子”。
关于本书 由于机器学习知识体系涵盖范围广泛,相关内容分为两篇系统呈现,每篇都构建了相对完整的知识体系。本书主要介绍机器学习中的基础技术和经典模型,包括监督学习、特征工程、模型评估与选择等内容,正在创作中的提高篇主要介绍机器学习中的一些高级技术和相对复杂的模型,包括集成学习、无监督学习、概率图模型和强化学习等内容。对于初学者,建议先阅读本书,再学习提高篇;有一定基础的读者可根据自己的兴趣选择阅读本书或提高篇中的部分模型。
本书的写作方法是“徒手推公式,从零撸代码”。所有模型和算法,都从机器学习面临的问题讲起,从模型设计或改进的角度讲解原理,一步一步推导公式,最终形成算法,数学公式的推导有时到了过繁过细的地步,但宁愿让读者觉得啰唆,也不希望读者在阅读时“卡壳”。本书旨在讲清各个模型和算法的来龙去脉,让读者不仅掌握原理,还掌握模型设计和改进的方法,授人以渔而不是授人以鱼。
本书的所有模型、算法、程序代码,都从零开始实现,没有使用现成的框架,也没有调用库,更不针对某个简单特殊的数据集。本书代码具有通用性,并与scikit-learn库做对比,以判断程序代码是否达到预期效果。从算法原理到代码实现,中间有时是有“坑”的,要学会“避坑”,需要实践。通过编写代码实现算法可以更好地理解和掌握算法原理。本书代码的注释非常详细,基本每行代码都有注释。
每章包括6个部分:机器学习面临的问题,算法原理和公式推导,算法实现,模型应用,笔试、面试题目选讲,习题。对于每种模型和算法,从“是什么”“为什么”“怎么实现”“怎么应用”“怎么改进”几个角度来介绍。本书以探究的形式,培养读者对机器学习的兴趣,帮助读者厘清解决问题的思路,锤炼解决问题的能力。
本书的特点是6多:实例多、图表多、公式多、算法多、代码多、习题多。本书注重通过实例和图表介绍算法,将原本应放在草稿纸上推导的中间部分的公式也作为正文内容呈现出来,一个公式甚至有十多步的推导。对于相关模型,介绍多种算法,例如在线性回归模型中介绍了两类方法(共6种算法),在感知机模型中介绍了3种算法。
本书提供了丰富的笔试、面试题,读者可借此对相关模型和算法进行总结和对比;本书还提供了丰富的习题,习题分为3类:数值实例题、理论分析题、编程实践题。数值实例题一般比较简单,主要用于测试读者对算法过程的理解和对数学背景知识的掌握;理论分析题侧重于测试读者对算法原理的理解和公式推导能力,部分分析有一定难度,少量分析是开放式的,没有标准答案;编程实践题旨在引导读者在本书代码的基础上进行修改和扩展。
关于数学 机器学习的门槛较高,入门较难,这让许多学生和研发人员望而却步,萌生退意,主要原因有需要掌握一定的数学基础知识、公式推导较为复杂、算法实现比较困难等。本书的目标是让读者从算法原理、公式推导、代码实现、模型应用上真正理解和掌握机器学习的理论和技术。
传统数学教育(特别是工科数学教学)较为强调计算能力,而在机器学习中,则侧重于对数学原理的理解和运用。在学习机器学习时,需要转换思维,不以计算和考试为目的,而是以探究模型算法背后的数学原理为重点。机器学习中的公式推导看似复杂,实则非常简单。
希望本书能够帮助读者克服对数学和公式推导的“恐惧”心理并喜欢上机器学习,即使以后阅读学术论文,也不惧怕数学公式,甚至能发现其中的推导错误和可改进之处。本书将在介绍部分模型之前回顾必要的数学知识。
关于代码 本书的源代码以简单、易读为主要目标,在实现算法时,较少使用NumPy模块中简洁和执行效率高的方法,代码重在功能实现,未进行优化,因此执行速度偏慢。代码注释十分详细,有时甚至到了过繁过细的地步,主要目的也是增加代码的可读性。每行代码偏短,主要是为了留出注释空间。
本书源代码基本未对输入参数做检查,通常假定参数是合法的。参数校验的代码较长,且与机器学习主体功能关系不大。但在实际研发中,参数检查和校验是极为重要的,非法参数会导致程序运行错误、系统崩溃、本地或远程的非授权访问等异常或安全漏洞。
源代码中函数和参数的命名仿照scikit-learn官方库,执行效果与官方库基本一致,有时更优。但本书源代码执行速度略慢,主要原因在于为了保证代码的可读性,本书未使用简洁高效的写法,也未对代码进行优化。
致谢 感谢妻子雷燕的理解和支持,使我能利用空闲时间专心写作。感谢女儿悦悦,你是我的天使和动力。感谢父母的养育和培养。感谢人民邮电出版社刘雅思编辑和李齐强编辑的大力支持和辛苦付出。在写作过程中,笔者在博客园、CSDN、知乎和哔哩哔哩网站搜集了大量关于机器学习模型和算法的提问和解答,在此对上述提问者和解答者表示感谢。
由于本人水平有限,书中难免有不当之处,欢迎各位专家和读者给予批评指正,笔者邮箱为4203995@qq.com。
童永清
2024年2月于海口
资源与支持 资源获取 本书提供如下资源:
• 配套源代码;
• 数据集。
要获得以上资源,可扫描右侧二维码,根据指引领取。
提交勘误 作者和编辑尽最大努力来确保书中内容的准确性,但难免会存在疏漏。欢迎您将发现的问题反馈给我们,帮助我们提升图书的质量。
当您发现错误时,请登录异步社区(https://www.epubit.com),按书名搜索,进入本书页面,点击“发表勘误”,输入错误相关信息,点击“提交勘误”按钮即可(见下图)。本书的作者和编辑会对您提交的勘误进行审核,确认并接受后,您将获赠异步社区的100积分。积分可用于在异步社区兑换优惠券、样书或奖品。
与我们联系 我们的联系邮箱是contact@epubit.com.cn。
如果您对本书有任何疑问或建议,请您发邮件给我们,并请在邮件标题中注明本书书名,以便我们更高效地做出反馈。
如果您有兴趣出版图书、录制教学视频,或者参与图书翻译、技术审校等工作,可以发邮件给我们。
如果您所在的学校、培训机构或企业,想批量购买本书或异步社区出版的其他图书,也可以发邮件给我们。
如果您在网上发现有针对异步社区出品图书的各种形式的盗版行为,包括对图书全部或部分内容的非授权传播,请您将怀疑有侵权行为的链接发邮件给我们。您的这一举动是对作者权益的保护,也是我们持续为您提供有价值的内容的动力之源。
关于异步社区和异步图书 “异步社区”(www.epubit.com)是由人民邮电出版社创办的IT专业图书社区,于2015年8月上线运营,致力于优质内容的出版和分享,为读者提供高品质的学习内容,为作译者提供专业的出版服务,实现作者与读者在线交流互动,以及传统出版与数字出版的融合发展。
“异步图书”是异步社区策划出版的精品IT图书的品牌,依托于人民邮电出版社在计算机图书领域40余年的发展与积淀。异步图书面向IT行业以及使用IT相关技术的用户。
彩图
第1章 绪 论 本章介绍机器学习的历史背景、现实状况和未来展望;人工智能、机器学习和深度学习的关系;机器学习的基本概念,包括基本术语、算法的主要类型和基本元素;机器学习发展历程;机器学习主要应用;机器学习相关背景,包括数学基础、Python和scikit-learn库;数据集操作实例等。
1.1 历史背景、现实状况和未来展望近现代以来,4次由科学和技术推动的工业革命,极大地改变了世界格局和社会面貌。
第一次工业革命以蒸汽机、蒸汽轮船、蒸汽火车为代表,标志着人类进入蒸汽时代,开创了以机器替代手工的时代。
第二次工业革命以电力、内燃机、汽车、飞机等为代表,标志着人类进入电气时代。随着发电机、电动机被相继发明和远距离输电技术的出现,电气工业迅速发展,电话、无线电报等开始投入应用。
第三次工业革命以计算机、原子能、航空航天和生物工程技术为代表,标志着人类进入信息时代,由电子、信息技术的使用和自动化在工业生产中的应用推动,互联网和移动通信技术开始普及。
第四次工业革命以人工智能、清洁能源、量子信息技术、生物技术和虚拟现实技术为代表,标志着人类进入智能和绿色能源时代,由人工智能、计算机、通信、工业自动化等技术融合而推动。
人工智能和机器学习在工农业生产、商业商贸、金融服务等领域得到广泛应用,同时深刻影响着我们的生活、娱乐和社交等。与之前的工业革命相比,第四次工业革命有着质的不同。之前的工业革命是人类的体力劳动逐渐被机器取代,而在当前正在进行的第四次工业革命中,脑力劳动开始被机器取代。在这一历史变革的中心,机器学习便是其中的一个关键赋能技术,它通过提取隐藏在数据中的信息和知识,做出高准确性的预测及行动决策。这类似于人类通过感官、个人经验和世代相传的知识进行学习并做出决定,是人类智能的核心。
以色列历史学家尤瓦尔·赫拉利(Yuval Harari)在其所著的《人类简史:历史的主宰》中揭示了人类从哪里来,在《未来简史:从智人到智神》中探讨了人类将走向哪里。尤瓦尔认为:生物生命都由生化算法控制,信息科学家也已掌握越来越复杂的电子算法。数学定律同时适用于生化算法和电子算法,两者可以合二为一,消除人类与机器之间的隔阂。
尤瓦尔同时表达了对未来的担忧:随着机器学习和人工智能技术的兴起,越来越多的算法会独立进化,自我改进,从自己的错误中学习。它们能够找到人类找不出的模式,采用人类意想不到的策略。最早的种子算法或许是人类开发的,但随着算法逐渐发展和演化,它们会走出自己的路,前往人类未曾踏足之地,而人类却无力追寻。
人类的未来是浩瀚星辰和无边宇宙,我们现在所从事的机器学习的研究与应用,在遥远的未来也许微不足道,但在前进的道路上,这是必须脚踏实地走出的一步。
1.2 人工智能、机器学习和深度学习的关系人工智能 (artificial intelligence,AI)是一门研究、开发用于模拟、延伸和扩展人类智能的理论、技术和应用系统的新兴学科。人工智能是计算机科学的一个分支,主要研究怎样使机器拥有人类智能,研究领域包括机器学习、机器视觉、自然语言处理、专家系统和机器人等。
众所周知,当前人工智能正蓬勃发展,取得了举世瞩目的成就,受到社会各界的广泛关注。我国高度重视人工智能,专门出台新一代人工智能发展规划,计划在2030年人工智能核心产业规模产值超过1万亿元,并带动相关产业产值超过10万亿元。上海交通大学、南京大学、中国人民大学等先后成立人工智能学院,招收本科生、硕士生、博士生等不同层次的学生。
机器学习是人工智能的一个分支,并受到统计学的深刻影响。机器学习很早就被认为是实现人工智能的方法之一,现在已经成为人工智能的核心和主要实现方法,直接推动了人工智能研究和应用的第三次高潮。
机器学习 (machine learning,ML)的本质是能够从经验中学习。我们引用汤姆·M.米切尔(Tom M. Mitchell)在第一本机器学习教材《机器学习》中给机器学习下的定义:对于任务T 和性能度量P ,一个计算机程序被认为可以从经验E 中学习是指通过经验E 的改进后,它在任务T 上由性能度量P 所衡量的性能可以提高。这里的经验通常指数据。
机器学习已经有几十年的发展历史,以微积分、线性代数、概率统计等数学知识为基础,利用数据或经验,模拟人类的学习行为,不断改善自身的性能。机器学习具有一定的门槛,需要具备较好的理论基础和编程能力。
关于机器学习,不得不提深度学习,深度学习是机器学习的一个重要分支。2016年至2017年,DeepMind公司的AlphaGo因先后战胜世界级围棋高手李世石和柯洁而轰动一时,引发了一股人工智能和机器学习的热潮。此前人工智能专家们普遍认为短期内机器在围棋领域不可能战胜人类,使用深度学习技术的AlphaGo却做到了。
深度学习 (deep learning,DL)是一种基于多层神经网络的机器学习算法。深度学习在语音识别、计算机视觉、自然语言处理等领域取得了压倒性胜利,是目前炙手可热的机器学习技术。一般认为,深度学习始于2006年。在深度学习出现之前,多层感知机、卷积神经网络、循环神经网络等深度学习的主要网络结构已经在机器学习中存在。深度学习极大地提升了机器学习的表达能力和泛化性能。
学好了机器学习,就掌握了人工智能的核心技术,同时为精通深度学习打下了坚实的基础。
1.3 机器学习的基本概念本节介绍机器学习的基本概念,包括机器学习的基本术语、算法的主要类型和基本元素等,这些是深入理解机器学习的基础。
1.3.1 机器学习的基本术语 机器学习主要研究通过计算的方式,利用经验改善系统自身的性能。在机器学习中,机器具有独立学习的能力。与传统的为解决特定任务而硬编码的程序不同,机器学习使用大量的数据来训练,通过算法从数据中学习,以完成特定的任务,对真实世界中的事件做出预测或决策。本节通过一个实例来引入机器学习的相关概念。
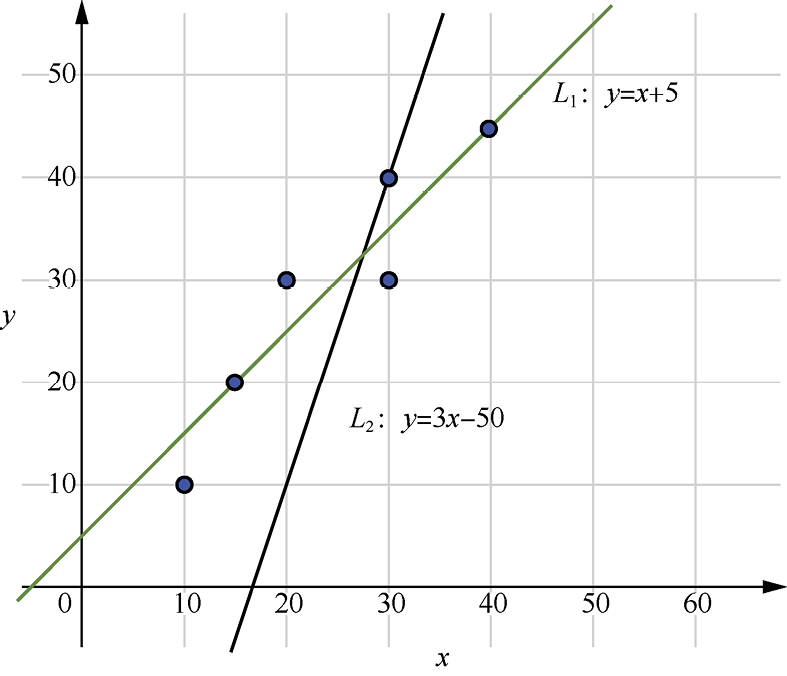
实例1.1 统计某网店今年 1 月至 6 月某商品流量费投入与利润额的关系,流量费与利润额数据如表1-1所示。店主拟大幅增加流量费投入,假设7月投入流量费80万元,请预测该商品的利润额为多少。
表1-1 某网店流量费与利润额
月份
流量费x /万元
利润额y /万元
月份
流量费x /万元
利润额y /万元
1
10
10
4
30
30
2
15
20
5
30
40
3
20
30
6
40
45
对于该问题,可以使用机器学习的方法进行求解。在二维平面上展示表1-1所示的数据,如图1-1所示,横轴为流量费x ,纵轴为利润额y ,每个数据为图中的一个点。用直线y =wx +b 拟合数据点,得到拟合直线后即可根据投入的流量费预测利润额。显然,图中直线L 1 的拟合效果优于L 2 ,使用L 1 进行预测更为准确。
图1-1 某网店月投入流量费与利润额(单位:万元)
在机器学习中,流量费的集合D = {x 1 , x 2 , …, x 5 }称为数据集 (data set)。数据集中每条记录x 是关于一个事件或对象的描述,称为数据 (data)或样本 (sample),数据集中记录的总数称为数据量 或样本数 。在本例中,x 为标量,通常x x x 属性 (attribute)或特征 (feature),x 特征向量 (feature vector)。x 输入空间 (input space),或称样本空间 (sample space),x 维度数 (dimensionality)或维数 。
数据x y 称为标签 (label),其所有取值构成输出空间 (output space),或称标签空间 (label space)。通常y 为标量,如果y 的取值为有限个离散值,则称该问题为分类 (classification)问题,y 也称为分类标签 ;如果y 的取值为连续值,则称该问题为回归 (regression)问题。显然本例是一个回归问题。如果每个数据都有一个真实值,则为监督学习 (supervised learning),否则为无监督学习 (unsupervised learning)。
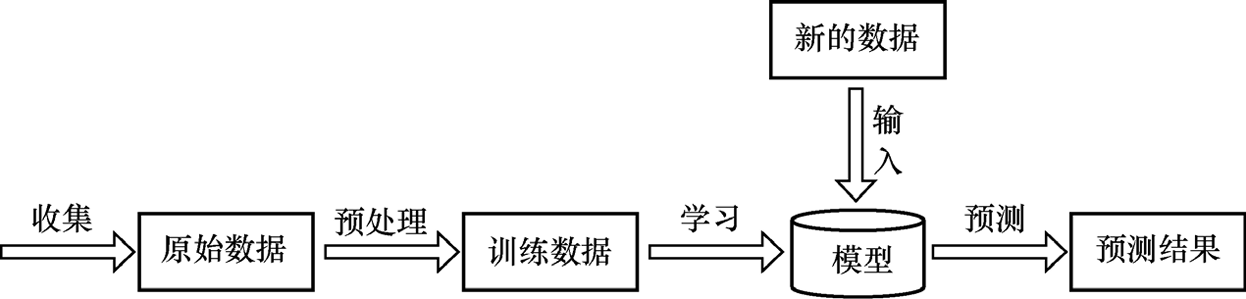
机器学习的一般过程如图1-2所示。
图1-2 机器学习的一般过程
机器学习通常从收集数据开始(很多情况下数据是现成的),收集到的原始数据一般要经过预处理才能使用,比如删除重复数据、处理缺失值、去除无用特征等。根据数据和问题的特点选择算法,使用训练数据学习得到模型,该过程称为学习 (learning)、训练 (training)或拟合 (fitting)。得到模型之后,可以对新的数据进行预测,得到预测结果。
在本例中,流量费和利润额为训练数据和真实值,训练得到线性回归模型y =wx +b ,其中w 、b 为模型待学习的参数(第2章将介绍使用最小二乘法、梯度下降法求解模型参数)。得到模型之后,可进行预测。假设学得的模型为y =x +5,当流量费投入为80万元时,预测利润额为85万元。
通常情况下,一个数据集会按照一定的比例(如7∶3或8∶2)划分为训练集 (training set)和测试集 (testing set),训练集中的数据称为“训练数据”或“训练样本”,测试集中的数据称为“测试数据”或“测试样本”。顾名思义,训练集中的数据用于训练和生成模型,测试集中的数据用于测试生成的模型的预测准确度。
机器学习的重点是算法的选择和模型参数的求解。从数学的角度讲,在大多数情况下,机器学习要确定一个从训练数据到真实值的映射函数f 以及函数的参数θ
式(1.1)中,x y 为函数的输出,通常为一个标量,也称预测值;θ f 称为“预测函数”或“决策函数”。f 可能非常简单,如实例1.1中的y =wx +b ;也可能非常复杂,如神经网络。
在监督学习中,输入和输出可以看作随机向量X Y P (X Y P (X Y
监督学习的目标是学习一个从输入到输出的映射f ,这一映射由模型来表示。模型属于输入空间到输出空间映射的集合,该集合称为假设空间 (hypothesis space)。学习的目的是从假设空间中找到最好的模型。监督学习的模型可以是“概率模型”或“非概率模型”,前者通常由条件概率P (Y X y=f (x
机器学习的目标是学得的模型可以很好地预测新数据,而不仅仅是很好地拟合训练数据。模型对新数据的预测能力称为泛化 (generalization)性能 。有时生成的模型很好地拟合了训练数据,但对新数据的预测能力却很差,这种现象称为过拟合 (overfitting)。有的模型没有很好地拟合训练数据,这种现象称为欠拟合 (underfitting)。过拟合和欠拟合是机器学习中的常见问题。
机器学习让计算机算法具有类似人的学习能力,能够像人一样从样本(数据)中学到经验和知识,从而具备判断和预测的能力。这里的样本(数据)可以是数字、文本,也可以是图像、声音等。
1.3.2 机器学习算法的主要类型 机器学习算法种类繁多,不同算法适合处理不同的问题,各有优劣。我们尝试从不同的角度对这些算法进行分类。需要说明的是,这些类型只是大致上的总体划分,并不能穷尽所有算法,机器学习算法本身也在不断丰富和发展中。
1.依据数据可提供的信息分类 机器学习的本质是从数据中学习,数据的可用信息尤为重要。依据数据可提供的信息分类是机器学习最主要的分类方式,可分为监督学习、无监督学习、弱监督学习等,如图1-3所示。
图1-3 依据数据可提供的信息分类
(1)监督学习。
监督学习是一种从有标签数据中学习预测模型的机器学习算法。其数据集的一般形式为
数据集中每个数据x i y i i = 1, 2, …, m 。(x i y i i 为样例的序号。通常x i y i y i x i x y i
(2)无监督学习。
无监督学习是一种从无标签数据中学习预测模型的机器学习算法。其数据集的一般形式为
由于数据没有标签,因此并不知道x i
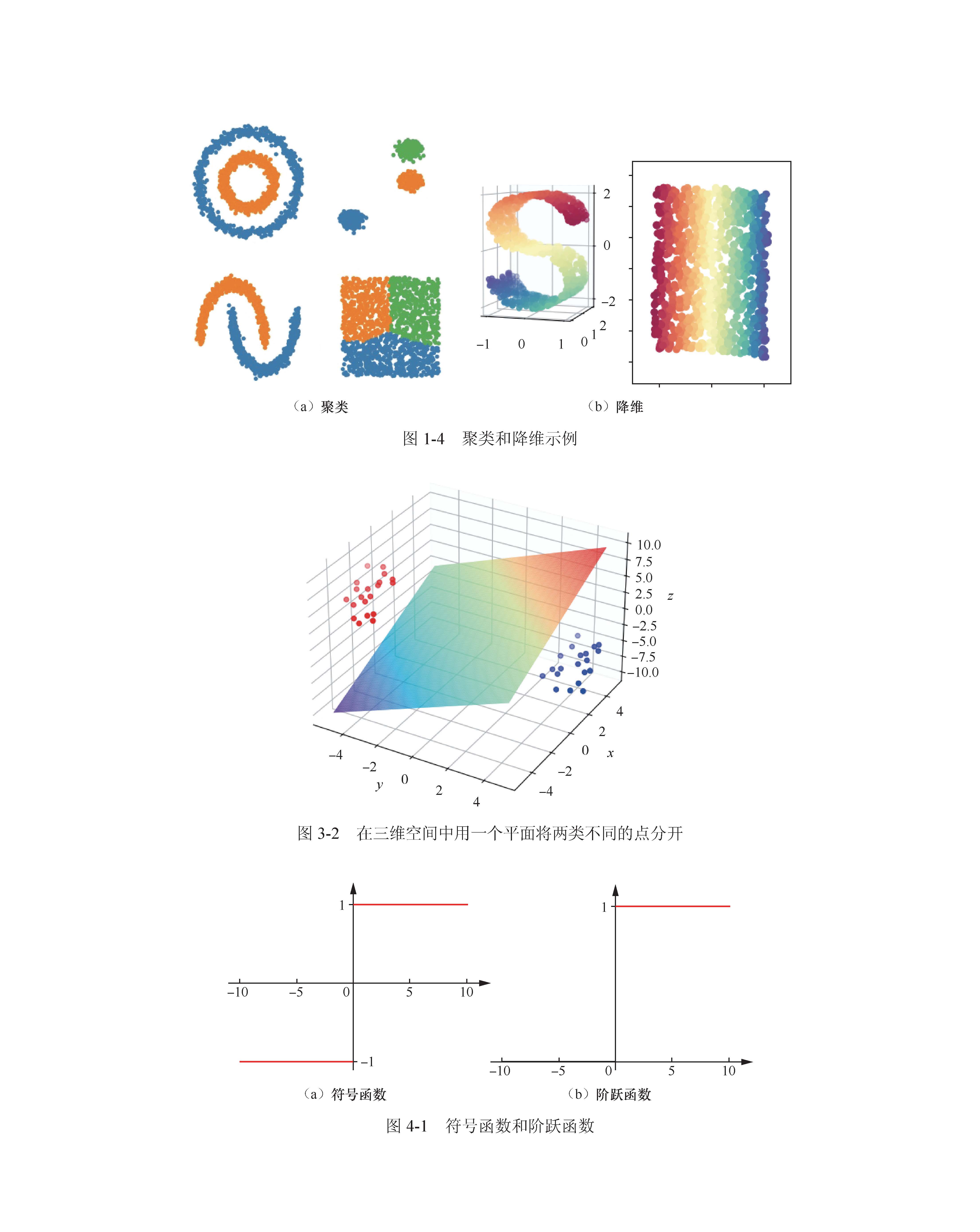
聚类是最常见的无监督学习类型,它从数据中发现聚集现象,数据聚集形成多个类,每个类有一些共同的性质。图1-4(a)是一些聚类示例。降维也是常见的无监督学习类型,将输入的高维向量用低维向量近似表示。用低维向量代替高维向量作为机器学习的输入,可简化模型、减少计算量、缩短训练时间,还可用于数据可视化。图1-4(b)所示为将一个三维流形降为二维的示例。
图1-4 聚类和降维示例(另见彩插)
(3)弱监督学习。
弱监督学习介于监督学习和无监督学习之间,只有少部分数据是有标签的,其他大部分数据难以获取或不存在标签,也有可能存在大量不精确或不确切的标签,典型例子有半监督学习、强化学习和主动学习。
半监督学习 (semi-supervised learning)是指利用少量有标签数据和大量无标签数据学习预测模型的机器学习算法。随着大数据技术的发展和应用,收集大量无标签数据相对容易,而获取大量有标签数据可能比较困难,往往需要大量的人力、物力、财力或时间成本。只有少量的有标签数据,不足以训练出好的模型,半监督学习大多结合监督学习和无监督学习算法,最大限度发挥少量有标签数据的价值,同时充分利用大量无标签数据改善模型性能。
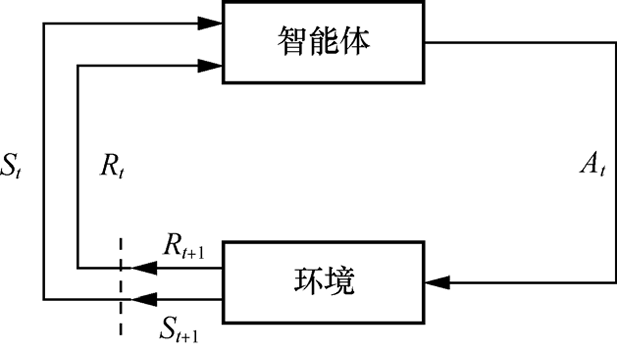
强化学习 (reinforcement learning)是指智能体在与环境的连续互动中学习最优行动策略的机器学习算法。战胜世界围棋冠军的AlphaGo和AlphaGo Zero的核心技术就是强化学习技术,同时使用了深度神经网络。
强化学习的原理如图1-5所示,假设在时刻t (t = 1, 2, …n ),智能体从环境中观测到一个状态S t R t A t S t +1 ,并反馈给智能体一个奖励R t +1 。智能体要学习的策略是给定状态下采取的动作。强化学习的目标是在长期奖励最大化原则的指导下,找到最优或近似最优的策略。
图1-5 强化学习的原理
主动学习 (active learning)是在样本标签不够的情况下,根据样本的信息量主动挑选样本,向人类“导师”查询标签,从而补充训练样本的机器学习算法。一般而言,越靠近决策边界的数据点,其信息量越大,人工标注的价值越高。主动学习的过程为:①利用当前样本集训练模型;②用模型挑选出信息量大的样本,人工标注后加入样本集;③重复步骤①、步骤②,直到模型收敛。主动学习主要应用于自然语言处理领域,比如文本分类、语音识别、信息检索等。在这些领域,样本标注难度大、成本高,需要挑选对模型改进有价值的样本进行人工标注。
2.依据模型中变量之间的关系分类 依据模型中变量之间的关系,可将机器学习算法分为线性模型和非线性模型。线性模型 (linear model)一般是指模型参数与学习目标之间具有线性关系,而两者不具有线性关系的为非线性模型 (non-linear model)。
线性回归、线性分类是典型的线性模型,逻辑斯谛回归 (logistical regression)是广义线性模型。决策树、人工神经网络是典型的非线性模型。一般而言,线性模型泛化能力较强,但表达能力较弱;非线性模型表达能力强,但泛化能力弱,容易产生过拟合现象。在实际问题中,一般首先使用线性模型,如果效果不佳再考虑使用非线性模型。
3.依据模型的表达形式分类 依据模型的表达形式,可将机器学习算法分为参数模型和非参数模型。参数模型 (parameter model)是结构固定、可由一组参数描述的模型。例如,实例1.1是典型的参数模型,模型中w 和b 为待求解的参数。当模型的参数确定了,模型也就确定了。参数模型的一般形式为
式(1.4)中,特征向量x y 为预测值,是模型的输出;h 是从输入到输出的映射,是假设空间的一个函数;θ x θ x θ x θ
目前机器学习中有许多非常复杂的参数模型,如深度神经网络可能拥有百万数量级甚至更多的参数,一旦网络结构确定,其参数的数量和作用也就确定了,可以使用一定的训练方法自动求得所有参数。
非参数模型 (non-parameter model)没有固定的模型结构,参数数量通常与训练数据相关。非参数模型最典型的代表是k 近邻模型。与参数模型相比,非参数模型并非完全没有参数,只是不显式地依赖固定的参数集。
4.依据模型训练所使用的特殊技巧分类 依据模型训练所使用的特殊技巧,可将机器学习算法分为迁移学习、在线学习、多任务学习、集成学习、联邦学习等。
迁移学习 (transfer learning)利用为某一任务训练的模型来训练另一个任务的模型,以解决模型训练数据不够或训练时间过长等问题。
迁移学习的应用场景有:
• 图像识别,例如用识别猫的模型来迁移识别老虎;
• 自动驾驶,例如用小汽车的自动驾驶模型来迁移训练大卡车的自动驾驶;
• 语音识别,例如用识别普通话的模型来迁移识别四川话。
在线学习 (online learning)是基于流式数据进行学习的机器学习算法,用持续产生的新数据训练和更新模型,使得模型能更好地预测未来数据。例如,预测黑客攻击的模型利用黑客攻击的新数据训练和更新模型,使得模型能更好地识别黑客攻击行为。
多任务学习 (multi-task learning)是指在一个数据集上训练一个模型,同时解决多个相关的问题,代表算法有多任务神经网络。多任务学习适用于只有一个数据集,但是需要同时优化两个或两个以上目标的场景,例如广告优化算法需要同时优化点击率和转化率两个目标。
集成学习 (ensemble learning)通过训练和综合多个模型来提高模型预测的准确性和泛化性能。在集成学习中,每个弱学习器只学习部分数据或全部数据的部分模式,将各个弱学习器集成得到强学习器,强学习器往往可以具有很高的性能。集成学习的主要方法有装袋 (bagging)法和提升 (boosting)法,代表算法有随机森林、AdaBoost、梯度提升树、XGBoost等。
联邦学习 (federated learning)是一种基于隐私计算技术的机器学习算法,以加密的方式,综合多个参与方的数据训练模型。联邦学习旨在保护各个参与方的数据隐私,做到数据可用而不可见,通常应用在金融、医疗等对数据隐私特别敏感的领域。
1.3.3 机器学习的基本元素 一般情况下,一个完整的机器学习系统由4个基本元素构成:数据集、模型、目标函数和算法。下面我们逐一介绍。
1.数据集 机器学习是从数据中进行学习的,数据集是必需的元素。1.3.1节提到,机器学习的一般过程从收集数据开始。基于训练数据,使用一定的算法学习得到模型,之后可以使用模型根据新数据进行预测或做出决策。在机器学习的学习研究和实际应用中,数据有两个主要来源:在学习研究中,通常使用公开的标准数据集;在实际应用中,根据问题的具体要求采集相关数据。
在本书中,通常使用scikit-learn官方库自带的数据集。在聚类、降维和流形学习等主题中,使用scikit-learn官方库提供的库函数生成相关数据集。本书使用的数据集有以下6个。
(1)鸢尾花数据集(用于分类问题)。
该数据集是一个经典的数据集,被广泛用于测试各种分类算法。该数据集包含3种鸢尾花数据,分别为山鸢尾(iris-setosa)、变色鸢尾(iris-versicolor)和维吉尼亚鸢尾(iris-virginica),共150个数据样本,每种鸢尾花各50个,每个数据有4个特征,分别为萼片长度(sepal length)、萼片宽度(sepal width)、花瓣长度(petal length)和花瓣宽度(petal width)。该数据集是一个150×4的数据表,前50行为山鸢尾,中间50行为变色鸢尾,后50行为维吉尼亚鸢尾,其中山鸢尾与变色鸢尾、山鸢尾与维吉尼亚鸢尾是线性可分的,变色鸢尾与维吉尼亚鸢尾线性不可分。每个数据的分类标签(真实值)分别为0、1和2。鸢尾花数据集样例如表1-2所示。
表1-2 鸢尾花数据集样例
编号
sepal length
sepal width
petal length
petal width
分类标签
1
5.1
3.5
1.4
0.2
0
2
4.9
3.0
1.4
0.2
0
……
……
0
51
7.0
3.2
4.7
1.4
1
52
6.4
3.2
4.5
1.5
1
……
……
1
101
6.3
3.3
6.0
2.5
2
102
5.8
2.7
5.1
1.9
2
……
……
2
(2)波士顿房价数据集(用于回归问题)。
该数据集包含美国马萨诸塞州波士顿市住房价格的有关信息,共506个数据样本。每个数据样本有13个属性和1个真实值,具体情况如下。
① crim:城镇人均犯罪率。
② zn:住宅用地所占比例。
③ indus:城镇中非商业用地所占比例。
④ chas:查尔斯河虚拟变量(如果为河道则值为1,否则为0)。
⑤ nox:一氧化氮浓度。
⑥ rm:每套住宅的房间数。
⑦ age:1940年以前建造的自住单位比例。
⑧ dis:与波士顿5个就业中心的加权距离。
⑨ rad:高速公路的可达性指数。
⑩ tax:每1万美元的不动产税率。
⑪ ptratio:城镇中教师与学生的比例。
⑫ b:城镇中某一群体人员的比例。
⑬ lstat:房东属于低等收入阶层的比例。
⑭ medv:自住房屋价格的中位数(单位:千美元)。
该数据集的前5行如表1-3所示。
表1-3 波士顿房价数据集的前5行
编号
crim
zn
indus
……
lstat
medv
1
0.00632
18
2.31
……
4.98
24
2
0.02731
0
7.07
……
9.14
21.6
3
0.02729
0
7.07
……
4.03
34.7
4
0.03237
0
2.18
……
2.94
33.4
5
0.06905
0
2.18
……
5.33
36.2
需要说明的是,波士顿房价数据集在scikit-learn 1.2版本中被移除,因此本书使用scikit-learn 1.0.2这个包含波士顿房价数据集的版本。安装scikit-learn库时,可以指定安装的具体版本,也可以从相关网站免费下载该数据集。
(3)乳腺癌数据集(用于分类问题)。
该数据集根据乳房肿块图像的多种属性判断是否癌变。该数据集有569个数据样本,每个数据样本有30个属性,另有1个分类标签,标签0表示恶性,1表示良性。该数据集的前5行如表1-4所示。
表1-4 乳腺癌数据集的前5行
编号
mean radius
mean texture
……
worst fractal dimension
分类标签
1
17.99
10.38
……
0.11890
0
2
20.57
17.77
……
0.08902
0
3
19.69
21.25
……
0.08758
0
4
11.42
20.38
……
0.17300
0
5
20.29
14.34
……
0.07678
0
(4)糖尿病数据集(用于回归问题)。
该数据集统计了442名糖尿病患者的10个特征,以及1个用于回归的真实值。该数据集的前5行如表1-5所示。
表1-5 糖尿病数据集的前5行
编号
年龄
性别
BMI
BP
S1
S2
S3
S4
S5
S6
真实值
1
59
2
32.1
101
157
93.2
38
4
4.8598
87
151
2
48
1
21.6
87
183
103.2
70
3
3.9818
69
75
3
72
2
30.5
93
156
93.6
41
4
4.6728
85
141
4
24
1
25.3
84
198
131.4
40
5
4.8903
89
206
5
50
1
23.0
101
192
125.4
52
4
4.2905
80
135
(5)手写数字数据集(用于分类问题)。
该数据集的原始数据为二维图像,共有1797个数据样本,每个数据样本有64个属性,对应于1个8像素×8像素灰度图,每个属性值是像素的灰度值(0~16);分类标签的值为0~9,用于指示图像所表示的数字。该数据集第1个数据显示的图像(表示数字0)如图1-6所示。
图1-6 手写数字数据示例
图1-6对应的数据(8×8矩阵)为
[0, 0, 5, 13, 9, 1, 0, 0,
0, 0, 13, 15, 10, 15, 5, 0,
0, 3, 15, 2, 0, 11, 8, 0,
0, 4, 12, 0, 0, 8, 8, 0,
0, 5, 8, 0, 0, 9, 8, 0,
0, 4, 11, 0, 1, 12, 7, 0,
0, 2, 14, 5, 10, 12, 0, 0,
0, 0, 6, 13, 10, 0, 0, 0]
(6)葡萄酒识别数据集(用于分类问题)。
该数据集是对意大利同一地区3种葡萄酒进行化学分析的结果,共有178个数据样本,每个数据样本有13个属性,即13个化学成分值,如酒精含量(alcohol)、苹果酸含量(malic_acid)、灰分含量(ash)、脯氨酸含量(proline)等;另有1个分类标签,标签值有3个——0、1、2,分别表示3种葡萄酒。该数据集的前5行如表1-6所示。
表1-6 葡萄酒识别数据集的前5行
编号
alcohol
malic_acid
ash
……
proline
分类标签
1
14.23
1.71
2.43
……
1065.0
0
2
13.20
1.78
2.14
……
1050.0
0
3
13.16
2.36
2.67
……
1185.0
0
4
14.37
1.95
2.50
……
1480.0
0
5
13.24
2.59
2.87
……
735.0
0
2.模型 模型 (model)是指机器学习问题采用的具体数学表达形式。在监督学习中,模型是要学习的决策函数(非概率模型)或条件概率分布(概率模型)。在实例1.1中,用一条直线拟合所有训练数据,模型为直线的数学表达式y =wx +b ,其中w 、b 为模型待求解的参数。求得参数后,可以使用模型y =wx +b 进行预测。显然,这是一个非概率模型,y =wx +b 也称为决策函数。w 、b 所有可能取值构成假设空间,在该问题中,假设空间是所有直线的集合,这样的直线有无穷多条。一般地,假设空间中的模型有无穷多个,通过学习算法找到最优或近似最优者。
经过数十年的研究,在机器学习中,已经构建出许多模型,如线性回归、支持向量机、决策树、人工神经网络等。一些模型可能更适合某类问题,没有一种模型对所有问题都是最优的。即使是非常强大的深度神经网络,在一些表格型的小数据集上,其性能也不如集成学习。模型并不是越复杂越好。模型越复杂,拟合能力越强,但也可能将数据集中的噪声和异常也进行了拟合。使用这样的模型进行预测,效果通常不是最好的,这就是过拟合现象。解决过拟合问题的一种常用方法是正则化 (regularization)。第5章将介绍过拟合和正则化。
3.目标函数 一个机器学习系统要完成一种任务,需要一个评价函数来衡量目标的完成情况,即要有一个目标函数。评价系统是否达到所要求的目标,一种常见做法是引入损失函数 (loss function)评价实际情况与目标之间的差距;另一种常见做法是评价系统的收益,如强化学习的奖励机制。前者要求损失函数最小化,后者要求目标收益最大化。在大多数情况下,要求目标函数或损失函数最小化。对于函数f (x f (x
以监督学习为例,将式(1.1)的模型写为如下一般形式:
在机器学习中,通常用y 表示训练数据的真实值(事先给定),f 对x y =
通常将数据集按比例划分为训练数据集和测试数据集,定义训练误差为训练数据集的平均损失:
式(1.7)中,m 为训练数据集的数据量。
式(1.7)也被称为经验损失函数,因为该损失函数是通过样本计算得到的,样本可以看作一种经验。为了学习得到最优模型,通过最小化式(1.7)经验损失函数,求得参数θ
例如,在实例1.1中可以定义如下形式的单个样本的损失函数:
式(1.8)中,以平方损失作为单个样本的损失函数。
在实例1.1中,假设求得的模型为y =x +5,数据点(10, 10)的误差为[10−(10+5)]2 =25,数据点(15, 20)的误差为[20−(15+5)]2 =0。
在实例1.1中,训练误差为
式(1.9)中,训练数据(x i y i i = 1, 2, …, m ,m =6,w 、b 为待求的参数。可以使用最小二乘法或梯度下降法求得使训练误差L train 最小的w 、b 。
求得模型参数后,通常需要使用测试集测试模型对新数据的预测能力,得到测试误差。测试误差与训练误差的计算方法一样,计算方式为
式(1.10)与式(1.7)的区别仅在于使用的数据集不同,式(1.10)中测试数据集的样本数为n 。
通常将测试误差作为模型的泛化误差,代表模型的泛化能力。我们要求训练得到的模型不仅训练误差小,更重要的是测试误差也小。训练误差小而测试误差大,说明存在过拟合现象,学习算法对训练数据拟合得太好,对噪声和异常也进行了拟合,导致泛化能力较差。
4.算法 在一个机器学习问题中,收集了数据,确定了模型,定义了目标函数,之后便是使用算法求解模型参数。对于较复杂的模型,难以求得或不存在公式解(解析解),需要使用优化算法。在实例1.1中,假设采用线性回归模型,使用最小二乘法可求得解析解,也可使用梯度下降法求得模型参数w 、b ,具体求解方法将在第2章介绍。
1.4 机器学习发展历程机器学习的起源可以追溯至20世纪50年代,但在20世纪80年代它才成为一个独立的研究方向。20世纪90年代至21世纪初,机器学习蓬勃发展,大量经典的模型和算法在这一时期被提出。2006年,深度学习技术兴起,机器学习(特别是深度学习技术)在诸多领域取得突破性进展并走向大规模商用,成为人工智能主要的实现方式。
1.5 机器学习主要应用随着智能时代的到来,机器学习的应用变得十分广泛。在日常生活中,常见的应用包括电商和外卖平台的商品推荐,新闻聚合平台的新闻推荐、小视频推荐,安防领域的人脸识别、指纹识别、车牌识别,通用领域的语音输入法、聊天机器人、智能客服等。在研究领域中,机器学习在计算机视觉、语音识别、自然语言处理、大数据与数据挖掘、推荐系统、搜索引擎、自动驾驶等领域都有广泛应用。此外,机器学习在教育、交通、农业、环境、能源、物流和城市管理等诸多领域都有应用,例如金融领域的用户识别与画像、智能投资顾问、反欺诈,生物医疗领域的生物信息学、蛋白质结构预测、手术机器人、智能诊疗、医学影像识别,政府和军队领域的电子政务服务、智慧法庭、风险预警与应急处置、察打一体无人机、智能火力控制系统、智能兵棋推演系统,工业制造领域的智能芯片制造、工业机器人、虚拟现实与增强现实、智能终端和可穿戴设备等。
1.6 机器学习相关背景机器学习的应用十分广泛,在学习机器学习之前需要掌握和了解一定的背景知识,在理论方面主要是数学基础知识,在实践方面主要是Python编程语言,同时需要了解机器学习领域使用较广泛的scikit-learn库。
1.6.1 数学基础 机器学习的模型和算法大多基于一定的数学原理,学习机器学习需要掌握一定的数学基础知识。不同的学习目标,对数学的要求也不同。我认为学习机器学习有3个层次,一是应用机器学习模型和算法,二是从事机器学习相关软件开发,三是从事机器学习科研和高级研发。对于第一个层次,基本不需要掌握机器学习的数学原理,只需了解模型和算法的适用情况;对于第二个层次,只需看懂算法的推导结果,如果能了解推导过程则更有利于机器学习软件开发;对于第三个层次,需要掌握机器学习的数学原理和推导过程,甚至需要改进和设计新的模型和算法。
具体而言,在机器学习中用到的数学知识主要有:微积分中一元函数的导数、多元函数的偏导数和梯度、凹凸性与极值、泰勒公式、矩阵向量求导等;线性代数中的向量和矩阵、特征值与特征向量、矩阵分解等;概率论与数理统计中的随机变量、条件概率、贝叶斯公式、概率分布和极大似然估计等;最优化理论中的梯度下降法、拉格朗日乘子法、凸优化方法;信息论中的交叉熵、条件熵等。
1.6.2 Python 从事机器学习的研究与开发,应掌握一门计算机语言。Python是人工智能、机器学习和深度学习领域常用的语言。Python语法简单,易学易用,可以跨平台运行,机器学习相关模块丰富。学习机器学习,需掌握Python的基本使用方法,例如变量、函数的定义与使用,列表、元组、字符串的使用,条件、循环流程控制,类和对象的定义和使用,模块的导入和使用等。机器学习还涉及大量矩阵和向量操作,因此需要熟练掌握NumPy模块的使用。本书使用Python 3.8和NumPy 1.22。
1.6.3 scikit-learn库 scikit-learn(简称sklearn)官方库是使用Python编写的机器学习模型和算法库。scikit-learn官方库最初由大卫·库尔纳佩(David Cournapeau)于2007年在Google夏季代码项目中开发。2010年,法国国家信息与自动化研究所(institut national de recherche en informatique et en automatique,INRIA)参与其中,并于2010年1月发布第一个公开版本0.1 beta,本书使用scikit-learn 1.0.2。
scikit-learn官方库是一个支持监督学习和无监督学习的开源机器学习库,包含线性模型、支持向量机、朴素贝叶斯、决策树、集成学习、半监督学习、高斯混合模型、降维、聚类、流形学习等算法,还提供模型选择与评估、数据预处理、特征选择、通用数据集和诸多实用程序。scikit-learn官方库中模型众多,性能强悍,文档丰富。本书在实现机器学习模型和算法时,以scikit-learn官方库为参照物。
CDA数据科学研究院将scikit-learn文档翻译为中文,搭建了scikit-learn中文社区。图1-7为scikit-learn中文社区首页,scikit-learn包含六大模块,即分类、回归、聚类、降维、模型选择和预处理。scikit-learn的文档相当丰富,包括所有模型和算法的API使用说明,还有大量的算法原理介绍、示例代码、图形化展示等。
图1-7 scikit-learn中文社区首页
1.7 数据集操作实例导入和查看鸢尾花数据集的代码(文件名为view_dataset.py)如下:
# encoding=utf-8
import numpy as np # 导入NumPy模块并重命名为np
import pandas as pd # 导入pandas模块并重命名为pd
from sklearn import datasets # 从sklearn模块导入数据集
# 使用NumPy模块的loadtxt()函数从D盘根目录读取鸢尾花数据集文件(.csv格式)
np_iris = np.loadtxt("D:/iris.csv", delimiter=",", dtype="float", encoding="utf-8")
# 输出鸢尾花数据集的前5行
print(np_iris[:5], "\n")
# 使用pandas模块的read_csv()函数从D盘根目录读取未经处理的鸢尾花数据集文件(.csv格式)
df_iris = pd.read_csv("D:/iris_unprocessed.csv", encoding="utf-8")
# 输出未经处理的鸢尾花数据集
print(df_iris, "\n")
iris = datasets.load_iris() # 从scikit-learn库加载鸢尾花数据集
print("keys of iris: ", iris.keys()) # 查看鸢尾花数据集的构成
print("shape of data: ", iris.data.shape) # 查看鸢尾花数据的维度
print("shape of target:", iris.target.shape) # 查看鸢尾花标签的维度
print("feature_names: ", iris.feature_names) # 查看鸢尾花特征的名称
print("target_names: ", iris.target_names, "\n") # 查看鸢尾花标签的名称
# 从iris对象中读取鸢尾花数据和标签,存放到X和y中
X, y = iris.data, iris.target
# 输出X和y的类型、维度
print("type and shape of X:", type(X), X.shape)
print("type and shape of y:", type(y), y.shape)
# 输出鸢尾花数据和标签的前5行
print(X[:5])
print(y[:5]) 以上程序运行后,输出结果如下:
[[5.1 3.5 1.4 0.2 0. ]
[4.9 3. 1.4 0.2 0. ]
[4.7 3.2 1.3 0.2 0. ]
[4.6 3.1 1.5 0.2 0. ]
[5. 3.6 1.4 0.2 0. ]]
Id SepalLengthCm ... PetalWidthCm Species
0 1 5.1 ... 0.2 Iris-setosa
1 2 4.9 ... 0.2 Iris-setosa
2 3 4.7 ... 0.2 Iris-setosa
3 4 4.6 ... 0.2 Iris-setosa
4 5 5.0 ... 0.2 Iris-setosa
.. ... ... ... ... ...
145 146 6.7 ... 2.3 Iris-virginica
146 147 6.3 ... 1.9 Iris-virginica
147 148 6.5 ... 2.0 Iris-virginica
148 149 6.2 ... 2.3 Iris-virginica
149 150 5.9 ... 1.8 Iris-virginica
[150 rows x 6 columns]
keys of iris: dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
shape of data: (150, 4)
shape of target: (150,)
feature_names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
target_names: ['setosa' 'versicolor' 'virginica']
type and shape of X: <class 'numpy.ndarray'> (150, 4)
type and shape of y: <class 'numpy.ndarray'> (150,)
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
[0 0 0 0 0] 程序和输出结果说明如下。
(1)本书使用的所有数据集均为开源、免费的数据集,可以在随书源代码中找到,常用的数据集也可以从scikit-learn官方库中载入。本程序演示了从计算机硬盘中读取鸢尾花数据集和从scikit-learn官方库中读取鸢尾花数据集。
(2)运行程序前,需将随书源代码中的鸢尾花数据集文件复制到D盘根目录下,其中文件iris.csv是机器学习算法可直接使用的鸢尾花数据集,文件iris_unprocessed.csv是未经处理的鸢尾花数据集,包含编号和表头等。.csv是一种通用、简单的文件格式,数据之间以逗号为分隔符,也可使用空格等分隔符,可使用Excel软件打开,也可以作为文本文件打开。
(3)使用NumPy模块的loadtxt()函数读取数据集文件时,一般应指定目录和文件、分隔符、数据类型、编码格式等,也可以使用pandas模块的read_csv()函数读取数据集。scikit-learn官方库自带一些常用的数据集,用于测试分类和回归算法的性能。
(4)由输出结果可知,iris.keys()返回数据集包含的内容,iris.data存放鸢尾花数据,共150行4列(150个数据,每个数据有4个特征),iris.target存放鸢尾花数据的标签,共150行(每行1个数字,其值为0、1或2,分别代表1种鸢尾花)。本书后面主要使用本程序中的X和y,两者分别存放数据集和标签,且都是numpy.ndarray数组。本程序中X为矩阵,其维度是(150, 4);y为向量,其维度是(150, )。
小结 (1)人工智能是一门研究、开发用于模拟、延伸和扩展人类智能的理论、技术和应用系统的新兴学科。机器学习的本质是从经验中学习。深度学习是一种基于多层神经网络的机器学习算法。
(2)机器学习的基本术语有数据集、样本、特征、输入空间、维数、输出空间、分类、回归、监督学习、无监督学习、过拟合、欠拟合等。
(3)根据数据可提供的信息进行分类是机器学习最主要的分类方式,可分为监督学习、无监督学习和弱监督学习等。
(4)一个完整的机器学习系统由几个基本元素构成:数据集、模型、目标函数和算法等。
(5)本书常用的数据集为scikit-learn官方库自带的鸢尾花数据集(用于分类问题)、波士顿房价数据集(用于回归问题)、乳腺癌数据集(用于分类问题)、糖尿病数据集(用于回归问题)、手写数字数据集(用于分类问题)和葡萄酒识别数据集(用于分类问题)。
笔试、面试题目选讲 试题(1):机器学习有哪些分类方式?
参考1.2节。
试题(2):什么是监督学习、无监督学习、弱监督学习?
参考1.3节。
试题(3):机器学习的主要应用有哪些?
参考1.5节。
习题 1.理论分析题 (1)什么是机器学习?机器学习与人工智能、深度学习的关系是什么?(画图说明。)
(2)机器学习最主要的分类方式是什么?
(3)一个完整的机器学习系统包含哪些基本元素?
(4)名词解释:数据集、样本、特征、输入空间、维数、输出空间、假设空间。
(5)名词解释:过拟合、欠拟合。为什么会产生过拟合、欠拟合现象?
2.编程实践题 (1)安装Python 3.8、NumPy 1.22、scikit-learn 1.0.2和一种Python集成开发环境(如社区免费版的PyCharm),编写一个输出“Hello World!”的程序。
(2)查阅scikit-learn文档,编写Python程序,从硬盘或scikit-learn官方库中导入和查看波士顿房价数据集、乳腺癌数据集、糖尿病数据集、手写数字数据集和葡萄酒识别数据集。
(3)查阅scikit-learn文档,编写Python程序,基于实例1.1的数据生成和训练线性回归模型,并预测当流量费为85万元时利润额是多少。
参考文献 [1] 李航. 统计学习方法(第2版)[M]. 北京: 清华大学出版社, 2019.
[2] 周志华. 机器学习[M]. 北京: 清华大学出版社, 2017.
[3] 张旭东. 机器学习导论[M]. 北京: 清华大学出版社, 2022.
[4] 王东. 机器学习导论[M]. 北京: 清华大学出版社, 2021.
[5] 伊恩·古德费洛, 约书亚·本吉奥, 亚伦·库维尔, 深度学习[M]. 赵申剑, 黎彧君, 符天凡,等译. 北京: 人民邮电出版社, 2017.
[6] TURING A M. Computing machinery and intelligence [M]. Springer Netherlands, 2009.
[7] HINTON G E, OSINDERO S, TEH Y W et al. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006.



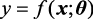 (1.1)
(1.1)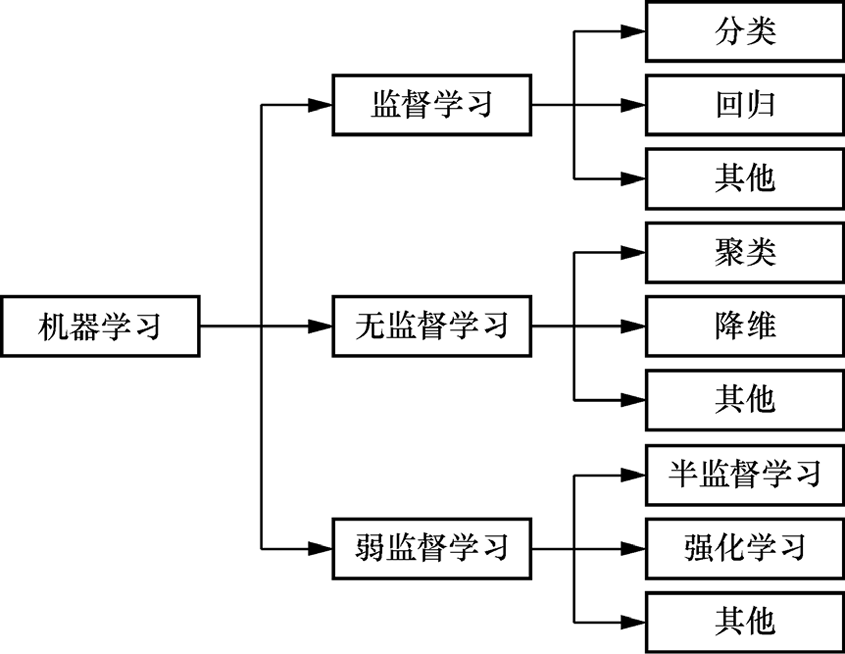
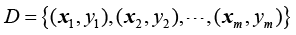 (1.2)
(1.2)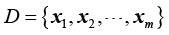 (1.3)
(1.3)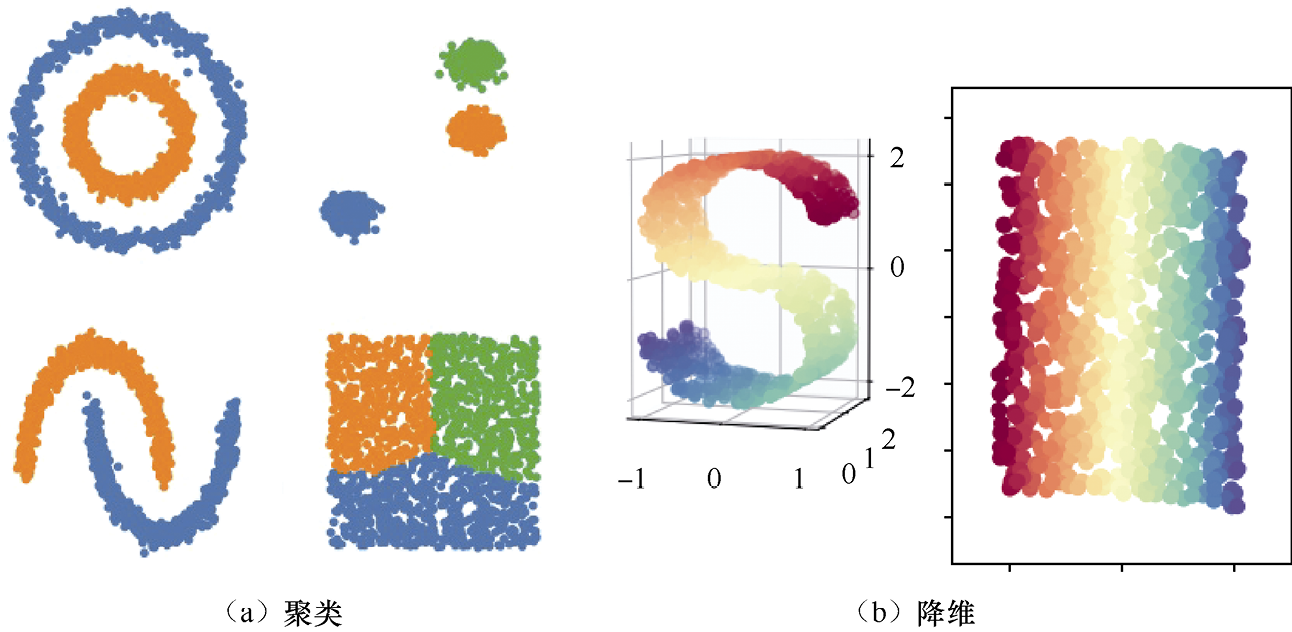
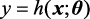 (1.4)
(1.4)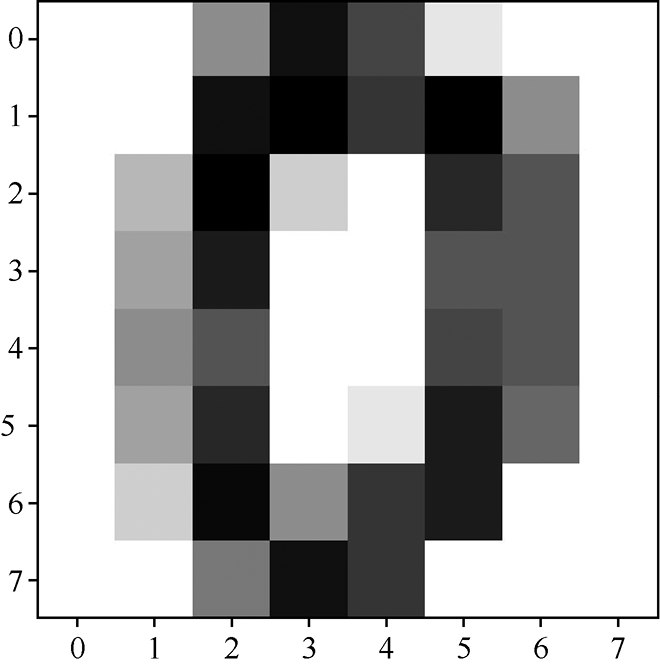
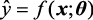 (1.5)
(1.5)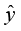 表示使用模型f对x进行预测得到的预测值。最理想情况下,对于每个样本,预测值等于真实值,即y =
表示使用模型f对x进行预测得到的预测值。最理想情况下,对于每个样本,预测值等于真实值,即y =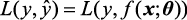 (1.6)
(1.6)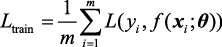 (1.7)
(1.7)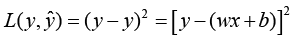 (1.8)
(1.8)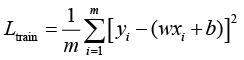 (1.9)
(1.9)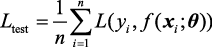 (1.10)
(1.10)





