2022年底,ChatGPT的诞生引发变革,以GPT系列模型为代表的大语言模型(Large Language Model,LLM)成为人工智能领域的研究热点,LLM在此背景下基于预训练语言模型取得突破性进展。本书分为基础知识与实战应用两大部分,基础知识部分包含第1~4章,首先介绍NLP的基本任务及文本表示的发展历程,接着阐述LLM基本架构Transformer和经典PLM架构,最后详述LLM的特点、能力和训练过程;实战应用部分包含第5~7章,依次讲解基于PyTorch搭建LLM的全流程,借助主流框架实现LLM训练,以及LLM的各类应用,帮助读者构建完整的LLM知识体系。
本书适合具备一定编程经验(尤其对Python编程语言有所了解)、掌握深度学习相关知识且了解NLP领域相关概念和术语的大学生、研究人员及LLM爱好者阅读。
图书摘要
版权信息
书名:Happy-LLM:从零开始构建大模型
ISBN:978-7-115-68503-2
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
版 权
编 著 朱信忠 宋志学 邹雨衡
责任编辑 武少波
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线:(010)81055410
反盗版热线:(010)81055315
内 容 提 要
2022 年底,ChatGPT的诞生引发变革,以GPT系列模型为代表的大语言模型(Large Language Model,LLM)成为人工智能领域的研究热点,LLM在此背景下基于预训练语言模型取得突破性进展。本书分为基础知识与实战应用两大部分,基础知识部分包含第1~4章,首先介绍NLP的基本任务及文本表示的发展历程,接着阐述LLM基本架构Transformer和经典PLM架构,最后详述LLM的特点、能力和训练过程;实战应用部分包含第5~7章,依次讲解基于PyTorch搭建LLM的全流程,借助主流框架实现LLM训练,以及LLM的各类应用,帮助读者构建完整的LLM知识体系。
2022年底,ChatGPT的横空出世改变了人们对人工智能的认知,也给自然语言处理(Natural Language Processing,NLP)领域带来了阶段性的变革,以生成式预训练Transformer(Generative Pre-trained Transformer,GPT)系列模型为代表的大语言模型(Large Language Model,LLM)成为NLP乃至整个人工智能领域的研究主流。自2023年至今,LLM始终是人工智能领域的核心话题,持续引发一轮又一轮的科技浪潮。
LLM本质上是NLP经典研究方法——预训练语言模型(Pre-trained Language Model,PLM)的一种突破性发展形态。NLP领域专注于对人类自然语言文本的处理、理解和生成,其发展历程经历了符号主义阶段、统计学习阶段、深度学习阶段、预训练模型阶段,直至当前的大模型阶段。以GPT和BERT(Bidirectional Encoder Represantations from Transformers,基于Transformer的双向编码器表征)为代表的PLM是上一阶段的核心研究成果,它们以注意力机制为核心架构,通过“预训练+微调”范式在海量无监督文本上进行自监督预训练,实现了强大的自然语言理解能力。但是,传统的PLM大多依赖一定量的有监督数据进行下游任务微调,且在自然语言生成任务上性能不尽如人意,NLP系统的性能离人们所期待的通用人工智能仍有不小的差距。
LLM是在PLM的基础上,通过扩大模型参数、预训练数据规模,并引入指令微调、人类反馈强化学习(Reinforcement Learning from Human Feedback,RLHF)等手段实现的突破性成果。相较于传统PLM,LLM不仅具备涌现能力,而且具有强大的上下文学习、指令理解和文本生成能力。在大模型阶段,NLP研究者可以一定程度上放弃大量的监督数据标注工作,通过提供少量监督样本,LLM即可在指定的下游任务上达到媲美全量微调PLM的性能。同时,强大的指令理解能力与文本生成能力使LLM能够直接、高效、准确地响应用户指令,从而向通用人工智能的目标迈出了坚实一步。
20世纪70年代以后,NLP研究者开始探索新的领域,包括逻辑基础的范式和自然语言理解(Natural Language Understanding,NLU)。这一时期,研究者分为符号主义(或规则基础)和统计方法两大阵营。符号主义研究者关注形式语言和生成语法,而统计方法的研究者更加关注统计和概率方法。20世纪80年代,随着计算能力的提升和机器学习算法的引入,NLP领域出现了革命性的变化,统计模型开始取代复杂的“手写”规则。
n-gram模型通过条件概率链式法则来估计整个句子成立的概率。具体而言,对于给定的一个句子,模型会基于n计算一组条件概率,并将这些条件概率相乘得到整个句子成立的概率。例如,对于句子“The quick brown fox”,若使用trigram(前缀tri-表示n=3)模型,那么需要计算、等概率,并将它们相乘。
Word2Vec模型主要有两种架构的模型,分别为连续词袋模型(Continuous Bag Of Words,CBOW)和Skip-Gram模型。CBOW模型根据目标词上下文中的词对应的词向量,计算并输出目标词的向量表示;Skip-Gram模型则与CBOW模型相反,其利用目标词的向量表示来计算上下文中的词向量。实践证明,CBOW模型适用于小型数据集,而Skip-Gram模型在大型数据集中表现更好。
ELMo(全称为Embeddings from Language Models,语言模型嵌入)实现了一词多义和静态词向量到动态词向量的跨越式转变。我们首先需要在大型语料库上训练语言模型,得到词向量模型;然后在特定任务上对模型进行微调,得到更适合该任务的词向量。ELMo首次将预训练思想引入词向量的生成中,使用双向LSTM结构,能够捕捉到词的上下文信息,生成更加丰富和准确的词向量表示。
[1] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[EB/OL]. arXiv: 1310. 4546.
[2] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[EB/OL]. arXiv: 1810. 04805.
[3] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Advances in Neural Information Processing Systems, 2017:5998-6008.
[4] HAJEIM M, LATIRI C. Combining IR and LDA topic modeling for filtering microblogs[C]//International Conference on Knowledge-Based and Intelligent Information & Engineering Systems (KES). 2017: 761-770.
[5] PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations[EB/OL]. arXiv: 1802. 05365.
[6] SALTON G. A vector space model for automatic indexing[J]. Communications of the ACM, 1975, 18(11): 613-620.



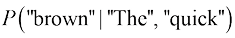 、
、 等概率,并将它们相乘。
等概率,并将它们相乘。




