版权信息 书名:高性能计算算法引擎 线性代数与异构计算的融合
ISBN:978-7-115-66005-3
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
版 权 著 赵先明 邹晓虎 刘钧文 夏 津 窦兴林
责任编辑 卜一凡
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线: (010)81055410
反盗版热线: (010)81055315
内容提要 本书主要探讨线性代数与高性能计算之间的紧密联系,并着重介绍在芯片架构算法优化中如何应用BLAS库。本书分为四部分,共12章。第一部分从线性代数的基础知识开始介绍,逐步深入介绍矩阵运算、向量空间、线性变换以及特征值和特征向量等核心概念;第二部分主要介绍计算机体系结构及其衍生出来的多种处理芯片(CPU、GPGPU等)和分布式计算;第三部分主要介绍高性能计算数学库BLAS的基本概念和基础的实现思路,以及高性能计算数学库的实现框架,如OpenBLAS、CUDA(及其BLAS库,包括cuBLAS、CUTLASS)、OpenCL、CLBlast、Spark和Spark MLlib BLAS;第四部分主要介绍BLAS库在人工智能方面的应用。
本书适合对线性代数和芯片架构算法优化感兴趣的读者阅读。无论是计算机相关专业的学生、高性能计算爱好者、算法工程师,还是希望进入高性能计算行业的人士,都能从中找到适合自己的学习内容。
推荐序1 在当前人工智能技术迅猛发展的时代,中国发展人工智能和高性能计算的“痛点”是算力芯片,高性能算力芯片的“痛点”是集成电路因“路径依赖”而面临“十面埋伏”式的围堵。要突破这一不利局面,我们需要从第一原理出发,进行创新,重构技术体系。这意味着要在数学、算法和芯片体系架构方面实现创新并开源,且进一步扩展到芯片的设计与制造,以形成新的技术路径和发展生态。
线性代数不仅是理解算法的基础,也是确保算法高效运行的关键。本书精确地描述了在多种芯片上用线性代数进行异构计算的方法,并强调了高性能线性代数算法与人工智能之间的紧密联系。作为一名专注于微电子技术研究的科研人员,我深刻认识到,无论是CPU、GPU还是其他专用加速器,线性代数算法的优化对于提高计算效率都至关重要。本书通过丰富的案例,展示了如何在异构计算环境中利用线性代数知识来优化算法,这对于推动人工智能技术的创新与发展具有重大意义。我向所有从事或关注高性能计算和人工智能领域的同人推荐这本书,它将为您在异构计算时代的探索提供坚实的理论支撑和实践指导。
国际欧亚科学院院士
推荐序2 在后摩尔时代,基于投影光刻的图形转移技术在技术和成本上已接近极限,因此利用人工智能来挖掘芯片制造系统的潜力,以可控的成本迈向更小的技术节点,已成为未来的发展趋势。同时,微电子科技的发展带来的算力提升也在不断推动人工智能达到新的高度。在集成电路技术和人工智能算法领域,线性代数算法的重要性不言而喻。
本书不仅深入剖析了线性代数与人工智能之间的紧密联系,还特别强调了在异构计算环境下,如何有效地利用不同类型的芯片来提升算法性能。基于我在集成电路研发和生产领域的长期经验,我深知线性代数算法在芯片设计和算法优化中的重要地位。本书的作者团队凭借其丰富的专业知识和实践经验,为我们呈现了一本兼顾理论与实践的佳作。我诚挚地向人工智能和微电子领域的所有研究人员和工程师推荐这本书,它将成为您在异构计算新时代的宝贵学术资源。
东方晶源微电子科技(北京)股份有限公司创始人、董事长
前 言 关于本书 首先,我们由衷地感谢您选择阅读这本关于线性代数和芯片架构算法优化的书。在这个人工智能和大模型技术高速发展的时代,人们正处在一个令人振奋的变革期。人工智能已经渗透到各个领域,推动着人们向智能化的未来迈进,而大模型技术则是人工智能发展的关键驱动力之一。
人工智能的快速发展得益于人们对数据的深入理解和数据处理能力的提升。线性代数作为数学的一个重要分支,提供了一种抽象的数学语言,可以用于描述和解决现实世界中的问题。在自然语言处理、图像识别、智能推荐等领域,线性代数都扮演着重要的角色,它作为一种有效的工具,可以帮助人们理解和分析复杂的数据结构,并构建出高效的算法。
与此同时,芯片架构算法优化对人工智能应用具有至关重要的作用。随着人工智能模型的不断发展和数据规模的爆炸式增长,使用优化算法来提高计算效率和性能成为一项紧迫的任务。芯片架构对算法的执行效果有着重要的影响,因此深入了解不同芯片架构的特点,并为不同芯片定制化地优化算法,将极大地提高计算效率和芯片性能。
本书将带领读者深入学习线性代数的基本概念,并着重介绍如何将这些概念与不同芯片架构的优化技术相结合。通过学习本书,读者将掌握一套强大的工具和方法,以更好地理解和应用线性代数,并在实际应用中提高算法的执行效率。
在编写本书的过程中,我们不仅参考了众多经典的线性代数教材和算法优化技术资料,还借鉴了人工智能和大模型技术的新成果。
读者对象 本书的读者对象包括但不限于以下群体。
■ 计算机相关专业的学生:本书从线性代数基础知识入手,逐步深入讲解芯片架构和算法优化,为计算机相关专业的学生提供了系统的知识体系和学习路径。
■ 高性能计算爱好者:本书详细介绍了BLAS库的各种实现框架和应用案例,以及针对不同芯片架构的算法优化方法,能够满足高性能计算爱好者的学习和探索需求。
■ 希望成为算法工程师的人士:本书深入分析了BLAS库的优化思路和技巧,以及线性代数算法在高性能计算中的应用,为算法工程师提供了新的思路和工具,帮助其提升算法性能。
■ 希望进入高性能计算行业工作(如成为高性能计算工程师)的人士:本书全面介绍了高性能计算领域的知识和技术,包括线性代数、芯片架构、算法优化和BLAS库等,为希望进入高性能计算行业工作的人士提供了必要的知识和技能储备。
内容安排 本书分为四部分。
第一部分:线性代数前置知识(第1章、第2章)。
第二部分:计算机体系结构和算法优化(第3章~第6章)。
第三部分:BLAS库与多种硬件平台(第7章~第11章)。
第四部分:BLAS库与人工智能(第12章)。
对于本书,建议读者先阅读第一部分,并根据自己的基础阅读第2章中线性代数方面的数学知识。第二部分涉及很多计算机体系结构的内容,建议读者先略读,等到读完第三部分,或者调试一些代码以后,再来理解第二部分的内容。第三部分是本书比较核心的内容,不过因为不同读者使用的编程模型以及开源组件不同,所以建议读者选择其中感兴趣的部分阅读。第四部分讲述BLAS库在人工智能方面的应用,但从人工智能的角度来说,这一部分介绍得略浅,因此只能帮助读者对二者的结合有大概的了解。
第1章介绍基础线性代数算法和高性能计算领域的发展及其基本知识。高性能计算是计算机技术的重要分支之一,而且脱胎于科研和军事方面的需求。随着计算需求的不断增长,专门用于数学计算的高性能计算数学库逐渐出现,通过这些数学库,科研人员可以非常便捷地完成科学计算任务,而且使用经过充分优化的数学库,往往可以充分利用硬件资源。在这些数学库中,较典型的是针对线性代数的数学库。
第2章介绍线性代数方面的数学基础知识,其中包含线性代数的基本概念、矩阵乘法、多项式方程组求解三大部分。这些都是了解BLAS必备的知识,而且BLAS库中对线性代数的相关功能进行了定义和实现。
第3章对计算机体系结构的基础知识进行说明。为了协调不同的电子元件,使它们能够完成计算任务,前人对计算机的架构进行了设计,其中影响最为深远的就是冯·诺依曼架构。基于此架构,又衍生出了很多子系统,如存储系统、控制系统、通信系统等。为了实现多服务器的扩展,衍生出了分布式架构等。
第4章对CPU向量指令系统以及CPU算法优化方法进行介绍。CPU是信息处理、程序运行的最终执行单元,因此在很多系统架构中承担了大量数学计算的任务。本章从CPU概述、CPU向量指令系统、CPU算法优化方法3个方面进行介绍,并且提供了一个实战案例,阐述在CPU上优化矩阵乘法的方法。
第 5 章介绍 GPGPU 架构以及并行计算算法优化方法。随着数学计算需求的不断增多,GPGPU的作用逐渐凸显,因为GPGPU能够实现海量数据的并行计算,尤其是对于线性代数算法这种可以进行拆分和并行计算的任务,可以起到非常好的加速作用。本章从GPGPU概述、GPGPU架构介绍、开源GPGPU项目以及并行计算算法优化方法4个方面进行介绍。
第6章讲述分布式计算。分布式计算起源于大数据技术,随着数据量的增大,原有的单一服务器无法承载海量的数据存储和计算任务,因此需要使用分布式计算系统来进行计算任务的调度。本章从分布式计算概述、大数据时代分布式计算架构、分布式计算算法优化方法3个方面进行介绍。
第7章正式开始介绍BLAS库的基本情况。首先对BLAS进行概述,其中包含BLAS的发展历史、特性以及如今的生态系统。然后介绍 BLAS 函数参考的信息,因为线性代数中有很多基础计算逻辑,所以BLAS库对这些计算逻辑进行了定义,随之出现了很多定义参数。最后介绍BLAS函数,对BLAS库中各个函数的功能和计算逻辑进行解释。
第8章介绍OpenBLAS。OpenBLAS是一个非常具有代表性的开源BLAS库,如今,它在很多领域都得到了应用。本章首先对OpenBLAS的基本情况(OpenBLAS的负责人张先轶先生、OpenBLAS的前世今生以及OpenBLAS的现状)进行介绍,然后介绍OpenBLAS的安装、使用方法以及架构设计,最后对OpenBLAS GEMM算法进行详解。
第9章介绍CUDA,以及基于CUDA的两个BLAS库——cuBLAS和CUTLASS。CUDA作为NVIDIA主推的编程模型,目前在各行各业的高性能计算领域都得到了广泛的应用,为了有针对性地解决线性代数问题,NVIDIA提供了闭源的cuBLAS和开源的CUTLASS,程序员可以比较轻松地调用这两个库,最大限度地利用NVIDIA的硬件性能优势。
第10章介绍通用编程接口OpenCL以及基于它开发的BLAS库——CLBlast。作为一套开源的通用编程接口,OpenCL并不强制绑定NVIDIA的硬件,而是支持更多的硬件,如CPU、DSP、FPGA等。基于OpenCL的BLAS库有很多,本章主要介绍其中比较有代表性的CLBlast,并对CLBlast GEMM算法的执行逻辑进行深入介绍,以帮助读者理解。
第11章对典型的分布式计算组件Spark进行介绍。分布式计算在大数据时代扮演着非常重要的角色,Spark 作为典型的分布式计算组件,已经成为行业通用的组件。在线性代数方面,它提供了很多计算的接口,如Spark MLlib BLAS,用户可以非常方便地调用它,实现对分布式计算集群的调度。
第12章主要对BLAS库在人工智能方面的应用进行阐述。当前人工智能主流的技术方向是以机器学习为基础的一系列技术栈,而在机器学习中,线性代数计算扮演了非常重要的角色。本章从卷积神经网络的计算流程、卷积神经网络的并行加速以及卷积神经网络加速实战3个方面介绍BLAS库在人工智能领域起到的重要作用。
致谢 感谢帮助我们完成本书的伙伴:吴瑞东、张威威、张玉栋以及红山微电子高性能计算团队全体成员。
刘钧文
资源与支持 资源获取 本书提供如下资源:
• 本书全部彩色插图;
• 本书的思维导图;
• 异步社区7天VIP会员。
要获得以上资源,您可以扫描下方二维码,根据指引领取。
提交勘误信息 作者和编辑尽最大努力来确保书中内容的准确性,但难免会存在疏漏。欢迎您将发现的问题反馈给我们,帮助我们提升图书的质量。
当您发现错误时,请登录异步社区(https://www.epubit.com),按书名搜索,进入本书页面,单击“发表勘误”,输入勘误信息,单击“提交勘误”按钮即可(见下图)。本书的作者和编辑会对您提交的勘误信息进行审核,确认并接受后,您将获赠异步社区的100积分。积分可用于在异步社区兑换优惠券、样书或奖品。
与我们联系 我们的联系邮箱是contact@epubit.com.cn。
如果您对本书有任何疑问或建议,请发邮件给我们,并请在邮件标题中注明本书书名,以便我们更高效地做出反馈。
如果您有兴趣出版图书、录制教学视频,或者参与图书翻译、技术审校等工作,可以发邮件给我们。
如果您所在的学校、培训机构或企业想批量购买本书或异步社区出版的其他图书,也可以发邮件给我们。
如果您在网上发现有针对异步社区出品图书的各种形式的盗版行为,包括对图书全部或部分内容的非授权传播,请您将怀疑有侵权行为的链接通过邮件发送给我们。您的这一举动是对作译者权益的保护,也是我们持续为您提供有价值的内容的动力之源。
关于异步社区和异步图书 “异步社区”是由人民邮电出版社创办的IT专业图书社区,于2015年8月上线运营,致力于优质内容的出版和分享,为读者提供高品质的学习内容,为作译者提供专业的出版服务,实现作译者与读者在线交流互动,以及传统出版与数字出版的融合发展。
“异步图书”是异步社区策划出版的精品IT图书的品牌,依托于人民邮电出版社在计算机图书领域30余年的发展与积淀。异步图书面向IT行业以及各行业使用IT的用户。
第一部分 线性代数前置知识 第1章 基础线性代数算法简介 随着计算机技术的飞速发展,人们对数据处理和分析的需求越来越大。在这种背景下,高性能计算成为实现大规模数据处理和科学计算的重要手段。基础线性代数算法库BLAS(basic linear algebra subprogram)作为高性能计算中使用频率非常高的基础软件库,随着计算机技术的发展而不断成熟。本章将介绍基础线性代数算法的发展,主要从以下3个方面进行讲解:高性能计算、高性能计算数学库和基础线性代数算法。
1.1 高性能计算高性能计算(high performance computing,HPC)是计算机技术的重要分支之一,它经历了数十年的演变过程。高性能计算的孵化可以追溯到20世纪50年代。当时,随着军方对科学和工程计算需求的不断增长,世界各国开始开发大型计算机。这些大型计算机拥有强大的计算能力和存储能力,可以完成大规模的数据处理和计算任务,成为高性能计算的基础。
在这些大型计算机中,比较有代表性的是美国计算机科学家西摩·克雷(Seymour Cray)在20世纪70年代发明的超级计算机——克雷机。克雷机的设计思想是采用大量的处理器和高速互联网络构成一个高效的并行计算系统。它在科学计算和工程领域得到了广泛的应用,成为高性能计算的代表之一。
时至今日,高性能计算作为一种解决大规模复杂计算问题的手段,已经成为科学研究、工程设计、医学诊断等领域不可或缺的工具。高性能计算的应用范围越来越广泛,包括天气预报、气候模拟、地震预测、能源开发以及生物医学、材料科学等领域。同时,随着大数据的普及和应用,高性能计算在数据分析、机器学习等领域扮演着越来越重要的角色。
在高性能计算领域,如何提高计算效率和性能是一个长期的研究课题。要提高计算效率和性能,一方面,需要不断发展新的算法和模型,以提高计算精度和速度;另一方面,需要构建高效的计算架构和系统,以提高计算并行度和吞吐量。近年来,随着硬件技术的发展,高性能计算系统的计算能力不断提高,计算节点的数量和互联网络的带宽也不断增加,这为高性能计算的应用提供了更加广阔的空间和更为丰富的可能。
然而,高性能计算的应用面临着许多挑战。首先,高性能计算系统的建设和运营成本较高,需要花费大量的资金,耗费大量的人力资源。其次,高性能计算系统的设计和优化需要充分考虑系统的可扩展性、可靠性、安全性等因素,这对计算机科学和工程领域的研究人员提出了非常高的要求。最后,要实现高性能计算的应用,研究人员需要充分理解数据的特点和规律,并结合领域专业知识和计算机科学技术,才能取得最佳的效果。
1.2 高性能计算数学库高性能计算往往需要依托一些高算力硬件才能发挥真正的实力。为了帮助用户更好地利用不同的硬件,将硬件性能“榨干”,往往需要专门的技术人员针对不同的硬件架构,对一些常用的数学运算进行定制化的开发,形成数学运算库。这些数学运算库就是高性能计算数学库。
1.2.1 高性能计算数学库简介 高性能计算数学库是一种专门用于解决数学问题的软件工具,其提供了丰富的数学函数和算法,可以用于高精度计算、线性代数、微积分等多个领域。随着计算机科学和工程技术的不断发展,高性能计算数学库的研究和应用得到了广泛关注。
高性能计算数学库的应用范围非常广泛,包括科学计算、工程设计、金融分析、数据挖掘等多个领域。在科学计算领域,高性能计算数学库可以用于求解微分方程、积分方程、偏微分方程等数学模型,为科学家提供强大的数值计算能力。在工程设计领域,高性能计算数学库可以用于模拟材料力学行为、分析结构动力学特性等,为工程师提供快速可靠的数值分析支持。在金融分析和数据挖掘领域,高性能计算数学库可以用于解决数据预处理、分类、回归、聚类等方面的问题,为分析师提供高效的金融分析和数据挖掘工具。
在高性能计算数学库的研究和开发中,最重要的目标是提高计算效率和性能。高性能计算数学库需要充分考虑计算复杂度和并行性,并优化算法和数据结构,以提高计算效率。同时,高性能计算数学库还需要充分利用计算机硬件的特性,以提高计算性能和并行度。近年来,随着计算机硬件技术的不断发展,高性能计算数学库的计算能力和性能得到了显著提高,为各个应用领域提供了更为强大的支持。
1.2.2 高性能计算数学库分类 针对不同的问题,高性能计算技术分别提供了不同的数学库,其中不仅包含比较传统的数学计算库,还有一些用于复杂的神经网络、音视频等的计算任务的数学库。本小节将列举其中比较有代表性的7种数学库。
1.稠密基础线性代数库——BLAS BLAS是一种用于线性代数计算的基本数学工具。它提供了一系列高效且可扩展的基本线性代数子程序,广泛应用于机器学习、数据处理、科学计算等领域。
BLAS数学库的主要特点是计算速度快、效率高。它采用高度优化的算法,使用机器级指令来实现计算,从而大大提高了计算速度。同时,BLAS数学库还支持多种矩阵存储格式,如行主序(row-major)、列主序(column-major)等,用户可以根据实际情况选择并使用。
在机器学习领域中,BLAS数学库可以用于进行矩阵乘法、矩阵向量乘法等计算,大大提高了计算效率;在数据处理领域中,BLAS数学库可以辅助对信号作傅里叶变换、滤波等操作,提高信号处理效率;在科学计算领域中,BLAS数学库可以用于求解线性方程组、特征值和特征向量等,提高了计算精度和速度。
2.稀疏基础线性代数库——Sparse Sparse是一种用于处理稀疏矩阵的高性能计算数学库。它提供了一系列快速、高效且可扩展的算法,能够处理大型稀疏矩阵,已在科学计算、图论、网络分析等领域得到广泛应用。Sparse数学库具有高效、可扩展和易用等特点,支持多种稀疏矩阵格式和自定义算法,同时提供简单易用的API(application program interface,应用程序接口)和丰富的示例程序与文档。Sparse数学库被广泛应用于大型科学计算和数据处理系统(如Spark、Hadoop等)中。
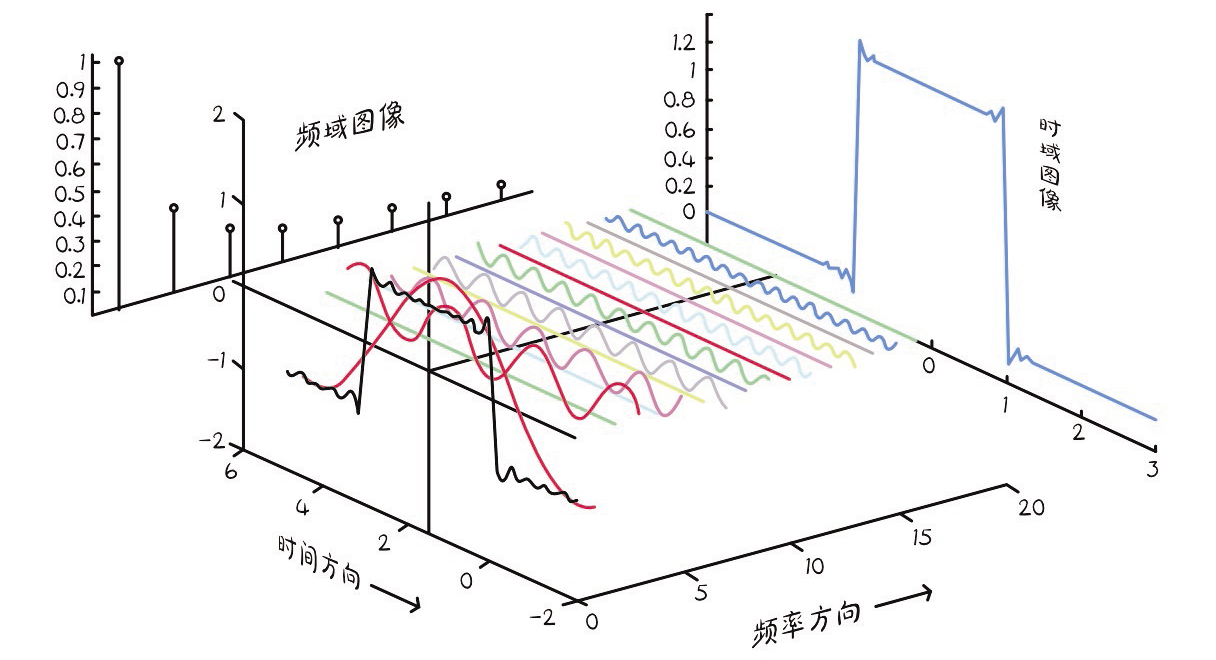
3.快速傅里叶变换库——FFT FFT(fast Fourier transform)数学库是一种用于计算DFT(discrete Fourier transform,离散傅里叶变换)和IDFT(inverse discrete Fourier transform,离散傅里叶逆变换)的数学工具。它提供了一系列高效且可扩展的算法,能够在较短的时间内处理大量数据的频域分析,广泛应用于音频处理、图像处理以及科学计算等领域。FFT原理示意如图1-1所示。
图1-1 FFT原理示意(图片来自TokyoChairman的知乎文章《浅谈傅里叶变换(一)》)
FFT数学库的主要特点是计算速度快、效率高。它采用分治法的思想,将一个大的DFT问题分解成许多小的DFT问题,并通过递归实现快速计算,从而大大提高了计算速度。同时,FFT数学库还支持多种DFT算法,用户可以选择能够满足自己需求的DFT算法。另外,FFT数学库还支持多种类型的数据,包括实数、复数、固定点数和浮点数等,用户可以根据实际情况选择并使用。
在音频处理中,FFT数学库可以用于音频信号的频域分析、滤波和谱估计等;在图像处理中,FFT数学库可以用于图像的变换、噪声消除、滤波和特征提取等;在科学计算中,FFT数学库可以用于求解微分方程、仿真模拟等。
4.深度神经网络库——DNN DNN(deep neural network)数学库是一种用于深度学习计算的数学工具。它提供了一系列高效且可扩展的算法,能够在较短的时间内处理大量的神经网络计算,广泛应用于计算机视觉、自然语言处理、语音识别等领域。
DNN数学库的主要特点是计算速度快、效率高。DNN数学库支持多种神经网络,如卷积神经网络、循环神经网络等,用户可以根据实际情况选择并使用。
在计算机视觉领域中,DNN数学库可以用于图像分类、目标检测、图像分割等;在自然语言处理领域中,DNN数学库可以用于语言模型构建、情感分析、机器翻译等;在语音识别领域中,DNN数学库可以用于语音识别、语音合成等。
5.高性能多媒体函数库——IPP IPP(integrated performance primitives)是Intel(英特尔)公司开发的一个高性能计算数学库,旨在提供一系列高效且可扩展的算法,能够在较短的时间内处理大量数据的数学计算,广泛应用于信号处理、通信等领域。
IPP数学库采用高度优化的算法和并行计算技术,使用CPU和GPU等硬件来实现计算,从而大大提高了计算速度。同时,IPP数学库还支持多种数据类型和存储格式,用户可以根据实际情况选择并使用。
在信号处理领域中,IPP数学库可以用于信号的滤波、降噪和谱估计等;在通信领域中,IPP数学库可以用于解调、调制和信道估计等。
6.向量数学库——VML VML(vector math library)是Intel公司开发的一套高性能计算数学库,旨在提供一系列高效且可扩展的向量计算函数和数学函数,能够在较短的时间内处理大量的向量计算和数学运算,广泛应用于科学计算、数据处理、图像处理等领域。
VML数学库的主要特点是性能优越,支持多种平台和处理器架构,而且提供了多种数学函数,如三角函数、指数函数、对数函数等,用户可以根据实际情况选择并使用。
在科学计算领域中,VML数学库可以用于矩阵运算、线性方程组求解和特征值计算等;在数据处理领域中,VML数学库可以用于向量运算、矩阵运算和统计分析等;在图像处理领域中,VML数学库可以用于图像变换、滤波和特征提取等。
7.向量统计学库——VSL VSL(vector statistical library)是Intel公司开发的一套高性能计算数学库,旨在提供一系列高效且可扩展的向量统计函数,能够在较短的时间内处理大量的向量统计计算,广泛应用于数据处理、金融分析、机器学习等领域。
VSL数学库提供了多种向量统计函数,可用于计算均值、方差、协方差、相关系数等,用户可以根据实际情况选择并使用。
在数据处理领域中,VSL数学库可以用于数据清洗、数据分析和数据可视化等;在金融分析领域中,VSL数学库可以用于风险评估、投资组合优化和金融工程等领域的数据分析;在机器学习领域中,VSL数学库可以用于特征提取、降维和分类等。
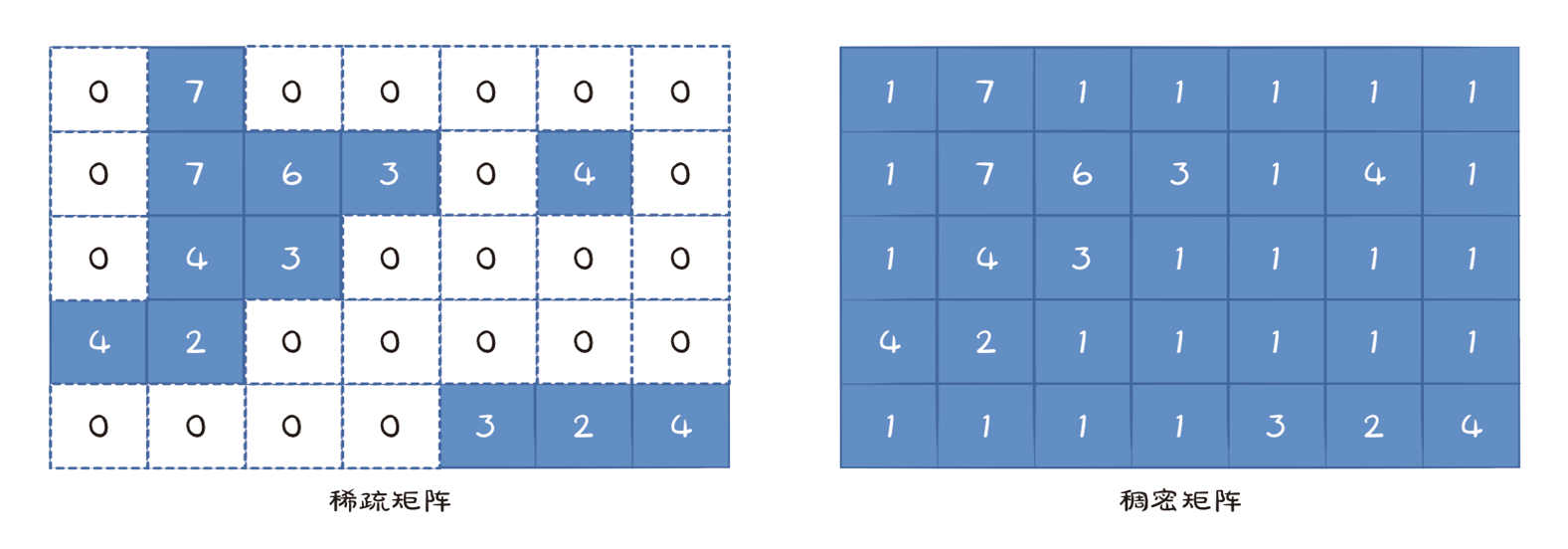
1.3 基础线性代数算法基础线性代数运算中涉及的矩阵有两种:稀疏矩阵(sparse matrix)和稠密矩阵(dense matrix)。这两种矩阵的示意如图1-2所示,其中,虚线白底的部分是被压缩的部分,其他部分都是在数据结构中完整保留的部分。针对这两种矩阵,衍生出了不同的线性代数算法。
图1-2 稀疏矩阵和稠密矩阵的示意(图片来自“小火箭”的博客文章《稀疏矩阵(Sparse Matrix)》)
1.3.1 稠密矩阵和稀疏矩阵 稀疏矩阵是指矩阵中大部分元素为0的矩阵。在实际应用中,大部分矩阵是稀疏的,例如文本数据中的词袋模型、社交网络中的关系矩阵等。稀疏矩阵可以使用压缩存储的方式来节省内存空间,提高计算效率。
稠密矩阵则是指矩阵中大部分元素不为0的矩阵。在实际应用中,一些数值计算问题,例如线性代数中的矩阵求逆、特征值分解等,需要使用稠密矩阵来解决。稠密矩阵需要存储大量的数据,因此需要使用更多的内存空间和计算资源。
在矩阵的表示方式方面,这两种矩阵有很大的不同。相对而言,稀疏矩阵的表示方式比较复杂,稠密矩阵的表示方式比较简单。
稀疏矩阵有多种格式,主要包括坐标格式、压缩稀疏行格式、压缩稀疏列格式,它们分别对应不同的矩阵表示方式。除了上述3种格式,还有块压缩稀疏行格式、对角存储格式、混合存储格式等,但它们在本书中不是重点,就不展开描述了。
坐标格式(coordinate format,COO格式):也称三元组格式,它将稀疏矩阵中的每个非零元素表示为一个三元组(i , j , v ),其中i 和j 分别表示该非零元素所在的行和列,v 表示该非零元素的值。具体示例如代码清单1-1所示。
代码清单1-1 COO格式的矩阵表示方式示例(C++语言)
#include <iostream>
#include <vector>
using namespace std;
/**
[6, 0, 8, 0],
[0, 7, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 5]
*/
//使用COO 格式表示的稀疏矩阵
vector<int> data = {6, 5, 7, 8}; // 非零元素的值
vector<int> row = {0, 3, 1, 0}; // 非零元素的行坐标
vector<int> col = {0, 3, 1, 2}; // 非零元素的列坐标 在上面的代码中,data数组存储了稀疏矩阵中的非零元素的值,row数组存储了这些非零元素的行坐标,col数组存储了这些非零元素的列坐标。COO格式易于构造,但是不便于进行矩阵运算。
压缩稀疏行(compressed sparse row,CSR)格式:它将稀疏矩阵的行压缩成一维数组,用3个数组来存储稀疏矩阵中的非零元素。具体示例如代码清单1-2所示。
代码清单1-2 CSR格式的矩阵表示方式示例(C++语言)
#include <iostream>
#include <vector>
using namespace std;
/**
[1, 0, 4],
[0, 0, 5],
[2, 3, 6]
*/
//使用CSR 格式表示的稀疏矩阵
vector<int> data = {1, 2, 3, 4, 5, 6}; // 非零元素的值
vector<int> col = {0, 2, 3, 6}; // 非零元素的列坐标
vector<int> row_ptr = {0, 2, 2, 0, 1, 2}; // 行指针 在上面的代码中,data数组存储了稀疏矩阵中的非零元素的值,col数组存储了这些非零元素的列坐标,row_ptr数组是一个行指针数组,其中row_ptr[i]存储了稀疏矩阵中第i行的第一个非零元素在data数组中的索引,row_ptr[i+1]存储了稀疏矩阵中第i+1行的第一个非零元素在data数组中的索引,这样就可以通过row_ptr数组来快速定位稀疏矩阵中每一行的非零元素。CSR格式在行向量的运算上效率很高,但在列向量的运算上效率不高。
压缩稀疏列(compressed sparse column,CSC)格式:它将稀疏矩阵的列压缩成一维数组,用3个数组来存储稀疏矩阵中的非零元素。具体示例如代码清单1-3所示。
代码清单1-3 CSC格式的矩阵表示方式示例(C++语言)
#include <iostream>
#include <vector>
using namespace std;
/**
[1, 0, 2],
[0, 0, 3],
[4, 5, 6]
*/
//使用CSC 格式表示的稀疏矩阵
vector<int> data = {1, 2, 3, 4, 5, 6}; // 非零元素的值
vector<int> row = {0, 2, 2, 0, 1, 2}; // 非零元素的行坐标
vector<int> col_ptr = {0, 2, 3, 6}; // 列指针 在上面的代码中,data数组存储了稀疏矩阵中的非零元素的值,row数组存储了这些非零元素的行坐标,col_ptr数组是一个列指针数组,其中col_ptr[j]存储了稀疏矩阵中第j列的第一个非零元素在data数组中的索引,col_ptr[j+1]存储了稀疏矩阵中第j+1列的第一个非零元素在data数组中的索引,这样就可以通过col_ptr数组来快速定位稀疏矩阵中每一列的非零元素。CSC格式在列向量的运算上效率很高,但在行向量的运算上效率不高。
稠密矩阵的表示方式相对来说比较统一,可以使用二维数组来表示。例如,下面的代码就演示了如何使用二维数组来表示一个3× 3的稠密矩阵。具体示例如代码清单1-4所示。
代码清单1-4 二维数组的矩阵表示方式示例(C++语言)
#include <iostream>
int dense_matrix[3][3] = {{1, 2, 3},
{4, 5, 6},
{7, 8, 9}}; 1.3.2 针对稠密矩阵的线性代数算法 稠密矩阵的表示更加规整,因此针对稠密矩阵的线性代数算法一般会更加直接。例如,在主要基于稠密矩阵和稠密向量的BLAS标准中,算法接口分为3个层级。
■ 1级:主要针对一维向量以及向量之间的运算。
■ 2级:主要针对一维向量以及二维矩阵之间的运算。
■ 3级:主要针对二维矩阵以及二维矩阵之间的运算。
上述提到的向量和矩阵均为稠密形式的。在使用这些算法的过程中,我们可以观察到,这些算法可以直接基于线性代数的基本公式来理解,相对比较简单。
在具体使用时,针对稠密矩阵的线性代数算法一般可以实现非常多样的功能,其中比较有代表性的有:
■ 通用矩阵和矩阵的乘法(general matrix multiply,GEMM);
■ 通用矩阵和向量的乘法(general matrix-vector multiply,GEMV);
■ 向量和向量的点积(dot product);
■ 线性方程组求解。
针对稠密矩阵的线性代数算法还能实现很多其他方面的功能,其中包括很多与复数矩阵相关的功能,本书后面章节会进行介绍。
1.3.3 针对稀疏矩阵的线性代数算法 相较于稠密矩阵,稀疏矩阵的表示方式更加复杂,因此针对稀疏矩阵的线性代数算法很多时候是在对稀疏矩阵本身的结构进行求解,对于矩阵本身的计算,反而没有稠密矩阵那么丰富,主要以矩阵和矩阵的乘法、矩阵和向量的乘法为主。
稀疏矩阵计算需要用到稀疏矩阵求解器(sparse solver),它是用于求解稀疏矩阵线性方程组的软件工具,其作用是实现高效的稀疏矩阵计算,提高计算效率和求解精度。
在实际应用中,稀疏矩阵的线性方程组求解是许多科学计算和工程计算中的重要问题之一,这些问题分布在结构力学、电力系统、流体力学等领域。传统的高斯消元法等方法在求解稀疏矩阵的线性方程组时,由于线性方程组中的大部分元素为0,计算量和存储空间开销都较大,因此需要使用一些专门的方法来求解稀疏矩阵的线性方程组,不过本书主要介绍稠密矩阵的计算方法,对稀疏矩阵的计算和优化方法不作详述。
1.4 本章小结本章作为本书开篇,首先从宏观角度介绍了高性能计算在整个计算机技术发展历程中扮演的角色。然后介绍了高性能计算中数学库的重要作用,以及目前高性能计算领域不同方向数学库的功能。最后聚焦在基础线性代数算法部分,为读者介绍了稠密矩阵和稀疏矩阵的区别,以及基于两者特性而衍生出来的不同线性代数算法。希望能够帮助读者了解BLAS库在整个计算机领域所处的位置,以便进一步学习和理解其原理。