版权信息 书名:AI驱动安全:技术原理与行业实践
ISBN:978-7-115-69056-2
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
版 权 主 编 范 渊 苗春雨 王 欣
责任编辑 单瑞婷
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线: (010)81055410
反盗版热线: (010)81055315
内 容 提 要 本书聚焦AI与网络安全的深度融合,系统介绍AI技术在网络安全领域的创新应用与实践路径,全面解析AI赋能安全的核心原理、关键技术及典型场景,旨在为应对智能时代的网络安全挑战提供理论支撑与实践指南。
全书共7章,内容包括AI的历史与发展趋势、AI技术的价值重构、大模型全链路解析、AI在网络安全领域的深度应用、AI安全风险与合规、构建安全可信的AI应用生态,以及总结与展望,覆盖理论知识、实践案例与前沿趋势。
本书适合AI与网络安全领域的从业人员阅读,也适合研究人员及高校师生参考。
编 委 会 主 编: 范 渊 苗春雨 王 欣
编 委: (按姓氏拼音排序)
陈 凯 杜廷龙 范 渊 符春辉 高学玲
黄 冲 姜翊杰 李华伟 刘 博 刘 苏
苗春雨 税雪飞 孙思明 孙伟峰 王 欣
吴东冬 吴思艺 杨 勃 杨绍波 姚龙飞
叶章龙 袁明坤 郑毓波 朱晓东
资源与支持 资源获取 本书提供如下资源:
• 本书思维导图;
• 异步社区7天VIP会员。
要获得以上资源,您可以扫描下方二维码,根据指引领取。
与我们联系 我们的联系邮箱是shanruiting@ptpress.com.cn。
如果您对本书有任何疑问、建议,或者发现本书中有任何错误,请您发邮件给我们,并请在邮件标题中注明本书书名,以便我们更高效地做出反馈。
如果您有兴趣出版图书、录制教学视频,或者参与图书翻译、技术审校等工作,可以发邮件给我们。
如果您所在的学校、培训机构或企业想批量购买本书或异步社区出版的其他图书,也可以发邮件给我们。
如果您在网上发现有针对异步社区出品图书的各种形式的盗版行为,包括对图书全部或部分内容的非授权传播,请您将怀疑有侵权行为的链接发邮件给我们。您的这一举动是对作者权益的保护,也是我们持续为您提供有价值的内容的动力之源。
关于异步社区和异步图书 “异步社区”(www.epubit.com)是由人民邮电出版社创办的IT专业图书社区,于2015年8月上线运营,致力于优质内容的出版和分享,为读者提供高品质的学习内容,为作译者提供专业的出版服务,实现作者与读者在线交流互动,以及传统出版与数字出版的融合发展。
“异步图书”是异步社区策划出版的精品IT图书的品牌,依托于人民邮电出版社在计算机图书领域多年的发展与积淀。异步图书面向IT行业以及各行业使用IT技术的用户。
推 荐 语 本书基于安恒信息公司在AI及网络安全领域的实践经验,系统介绍了AI发展历程、AI应用价值、大模型框架与组成要素、训练方法、部署方法与行业应用、AI在网络安全领域的典型应用场景及应用案例、AI主要风险及应对措施和AI可信生态构建等内容,对AI研究人员及网络安全从业者都具有很高的参考价值。
教育部高等学校网络空间安全专业教学指导委员会秘书长 封化民
本书按照“技术- 应用- 安全”三位一体的理念,重点介绍了AI关键技术、AI主要风险及应对措施、AI在网络安全领域的典型应用等内容。本书从价值驱动入手,将技术与产业深度融合,通过大量丰富的应用案例,将AI当前发展现状及未来发展趋势娓娓道来,堪称AI领域的必读之作。
北京航空航天大学网络空间安全学院原院长 刘建伟
本书是网络安全与AI领域一部极具价值的著作。无论你是对大模型技术怀有浓厚兴趣,还是希望在网络安全领域应用大模型技术,这本书都将是你不可或缺的指南。它不仅带你深入了解大模型的部署与应用的底层逻辑,更提供AI赋能网络数据安全的思路与方法,助你构建下一代智能化安全防御体系。
东南大学网络空间安全学院执行院长 程 光
本书是AI数智化转型时代的战略蓝图。本书深度剖析AI在威胁防御、安全治理等领域的创新范式,揭示从技术架构到生态重构的变革路径,助你构建安全与智能协同发展的未来生态。通过理论与实践结合的案例分析,助力安全人才掌握AI驱动安全的核心技能,适应数字化时代安全挑战,是AI安全人才培养的重要参考书。
西安电子科技大学网络与信息安全学院副院长 李兴华
本书以企业级安全实践为基石,将十余年攻防对抗经验凝练为AI驱动的网络安全产业变革方法论。在AI与网络安全深度交织的智变时代,作者团队融合技术洞见与产业实践,剖析生成式AI重塑安全边界的双重效应,提出可信AI治理框架与自适应防御体系。这是理解AI安全的必读之作,更是把握网络安全产业变革路线的技术指南。
中国现代国际关系研究院科技与网络安全研究所所长 李 艳
安恒信息公司是国内最早拥抱AI的安全公司之一,引领了大模型赋能数据分类分级的颠覆式创新,也是最早尝试开发安全智能体的企业。本书系统分享了安恒信息公司在大模型赋能网络安全产品方面的行业经验,并对AI自身安全的前沿问题展开了深入探讨。对于正在积极推进AI应用的各行业安全团队而言,这是一部及时而实用的佳作,具备很高的实践参考价值,推荐阅读!
北京赛博英杰科技有限公司创始人 谭晓生
本书以安恒信息公司十余年攻防实战经验为基石,系统擘画AI与网络安全融合的技术图谱与实践路径,从AI演进、大模型解析到防护体系构建,层层剖析AI赋能安全的核心逻辑,覆盖前沿技术原理,拆解多行业标杆案例。本书兼顾理论与实战,是AI时代网络安全从业者的权威读物,更是筑牢数字安全防线的必备指南。
科大讯飞安全负责人 沈明星
推荐序一 当历史的车轮驶入21世纪第三个十年,我们正在见证一场前所未有的智能革命。这场由人工智能(AI)驱动的产业变革,正在重塑全球经济的底层逻辑和运行范式。从早期的符号推理到如今的深度学习,从专家系统到大语言模型,AI的发展历程既蕴含着技术突破的必然,也充满了科学探索的艰辛。
从AlphaFold预测蛋白质结构到ChatGPT突破图灵测试,AI正在重构产业形态。例如,制造业涌现出自优化工厂,机器可实时优化流程设计;金融服务业实现风险评估与欺诈检测的精准化;医疗健康领域形成症状预测式干预体系。这些无不向世人昭示着:AI不仅是人类能力的延伸与增强,更是对脑力与智慧的补充乃至部分替代,甚至在某些方面已展现出超越人类的潜力。未来AI将突破单一模态限制,实现文本、图像、声音、触觉等多维数据的无缝融合。
本书恰逢其时地为我们提供了理解这一变革的独特视角,从网络安全这一关键领域切入,揭示AI技术如何成为推动产业升级的核心动能。
没有网络安全就没有国家安全。在AI时代,没有安全智能就没有可信智能,安全与智能的深度融合是确保技术健康发展的核心要求。传统的基于固定规则的防护手段,在AI驱动的可变性攻击面前几乎完全失效。AI技术正在破解安全运营领域的核心痛点:海量告警淹没、专家资源匮乏、未知威胁难以检测。通过复刻安全专家的研判思维和过程,AI能够实现威胁告警的自动化解读、降噪、溯源,甚至自主响应。从第一性原理出发,未来AI在安全应用领域,有望走向群体安全免疫、安全自治的更高阶段。
当推荐算法滋生“信息茧房”危机、大模型输出有偏见的内容时,可以通过对抗性去偏技术进行矫正。AI的发展和应用必须建立在AI向善的基础上,需要建立道德准则来指导和约束每一个算法,以确保公平、透明和有效问责。
本书以其独特的视角、深刻的洞察和务实的建议,为我们理解AI驱动的网络安全产业变革提供了宝贵的思想资源。相信本书可为政策制定者、企业领袖和技术专家提供重要参考,助力产业智能化走向更加安全、可信的未来。
当前,国家深入实施“人工智能+”行动,大力扶持AI产业发展,AI安全是确保AI健康、可持续发展的必要保障。在技术日新月异的今天,唯有通过持续的技术创新和开放的生态共创,才能在AI利用与保护之间找到最优的平衡点,最终共赢智能未来,真正实现技术赋能与社会福祉的辩证统一。
马琰铭
浙江大学校长、中国科学院院士
2025年10月
推荐序二 1956年的达特茅斯会议首次提出了“人工智能”这一概念,自此AI的发展伴随着算力、算法、编程语言以及数据处理技术的发展,经历了多个阶段。当ChatGPT-4o、Gemini、DeepSeek等AI应用涌入公众视野时,AI已经在深刻改变着人类社会的方方面面。
AI作为第四次工业革命的核心引擎,正在深刻重塑全球产业格局。这一革命以数据驱动和智能化技术为核心,通过机器学习、深度学习和自然语言处理等能力,实现了生产流程的自动化、决策的精准化和创新的加速化。在制造业领域,AI驱动的机器人优化了生产线效率,减少了人力成本;在能源和交通领域,AI驱动的大数据分析可以预测趋势、提升安全性,推动可持续发展。AI不仅提升了现有产业的竞争力,还催生了新业态(例如自动驾驶汽车和智能城市),成为推动经济转型和社会进步的核心动力。展望未来,AI的持续演进将释放更大潜力,引领人类步入一个更高效、更智能的新时代。
纵观人类科技发展史,每一次重大技术革命都对人类的生产力和生产关系产生了深刻影响,同时带来安全范式的重构。AI作为新一代通用目的技术,其特殊性在于它不仅是工具,更在某种程度上或者在不远的未来,具备相当的“主体”地位,可支配和控制现实世界。这种根本性转变,迫切要求建立新型安全观,应对AI发展带来的各种风险。
AI的安全问题引起了普遍关注。在此关键时期,本书的出版恰逢其时。
本书从数据、算法、算力三个维度,系统阐释了大模型的架构、技术原理与发展现状,并深入阐述了AI在网络安全领域的深度应用,包括智能安全运营、智能风险防御、威胁情报共享、智能数据保护以及AI驱动的安全新范式等,同时深入分析了AI自身的安全风险并提出了应对措施,从技术和管理两个维度构建了AI安全防护体系。
当前,国家实施“人工智能+”行动政策,大力扶持AI产业发展,AI安全是确保AI健康、可持续发展的必要保障。只要我们秉持“以人为本、安全可信”的理念,就一定能驾驭好AI这艘巨轮,驶向更加光明和智能的未来!
尹 浩
中国科学院院士
2025年10月
推荐序三 当前,AI技术发展迅猛,大模型、多模态技术不断突破,算力、算法、数据协同推进。AI的深入应用正引发多领域发生系统性变革。在经济领域,它重塑生产力逻辑,提升效率,开辟产业升级新维度,成为经济增长新动能;在教育领域,改变教学模式,助力个性化学习,促进教育生态重构;在社会治理中,提高决策科学性,优化公共服务。AI正加速向认知决策、多模态交互与人机协作方向不断深化发展;开源生态推动技术普惠,算力成本的持续降低,推动AI助力更多行业进行智能化转型。
同时,AI是一把“双刃剑”。在大模型应用场景下,数据安全、模型安全、应用安全等多方面的监管和实战都面临着新的安全挑战。建立科学治理机制,完善法律法规,强化技术监管,是保障AI健康发展、防范系统性风险的必然选择。
本书是一部极具价值的专业著作,系统阐述了AI在安全领域的核心应用,从威胁检测、自动化响应到智能化运营,深入解析了AI技术如何重塑安全防护体系。同时,通过金融、企业、网络安全等多行业实践案例,展现了AI在实际应用中的强大效能与创新价值。本书兼具理论深度与实践经验,为读者提供了从技术到落地的全方位视角。对于一线安全从业者、研究人员及企业决策者而言,本书是一部极具价值的参考书,助力读者把握AI驱动安全的未来趋势,构建更智能、更可靠的防护体系。
2025年8月,国务院印发的《关于深入实施“人工智能+”行动的意见》是在国家层面首次就AI与经济社会深度融合发布的系统性指导文件。“人工智能+”被视为重塑生产生活范式、促进生产力革命性跃迁的关键驱动力。在一系列的行动中,“人工智能+民生福祉”下的教育变革以及作为其基础支撑的“人工智能+人才培养”行动,占据了重要地位。
人才是AI创新发展的核心驱动力。技术突破靠人才、产业落地靠人才、生态构建靠人才。可以说,人才链的强度和长度,直接决定了创新链的高度和产业链的广度。如何利用AI推动教育范式从传统的“知识传授”向未来的“能力为本”深刻转变,并构建一个能够源源不断培养出适应乃至引领智能时代的创新人才体系,是决定“人工智能+”行动成败、关乎国家长远发展的基石性议题。
安恒信息公司以“构建安全可信的数字世界”为使命,将前沿AI技术与深厚实战能力深度融合,并创新性构建“学训赛一体”的实战教学体系,正是对国务院关于推动AI产业高质量发展、强化高水平人才队伍建设新政策精神的积极响应与生动实践。安恒信息公司探索培育既懂AI又精通网络安全的复合型、实战型人才,是企业积极履行社会责任、投身国家现代化教育体系建设的榜样,为筑牢数字中国的安全基石、推动新质生产力发展贡献了坚实力量。
叶美兰
南京邮电大学校长
2025年10月
前 言 AI作为新一轮科技革命和产业变革的核心驱动力,正深刻改变着人们的生产、生活和学习方式,引领人类社会迈向人机协同、跨界融合、共创分享的智能时代。当前AI不仅在通用应用方面遍地开花,而且在行业应用方面也在持续深化。在网络安全、数据安全领域,AI正在重构安全生态,引领网络安全产业和行业应用转型发展。
安恒信息公司依托多年来积累的技术和实践经验,在AI安全领域做了诸多有益探索。安恒信息公司自主研发的“恒脑”安全垂域大模型,已实现从1.0版本的安全垂域大模型持续迭代升级到3.0版本智能体,通过混合专家模型架构与全模态交互能力,“恒脑”安全垂域大模型不仅内嵌上百个针对数据治理、漏洞分析、威胁溯源等任务的安全智能体,还具备API(应用程序接口)聚合识别、自动流程绘制等复杂交互能力,覆盖数据治理、资产识别、漏洞检测、日志溯源、API安全等多个场景,在安全实践中发挥了重要作用。2023年,“恒脑”安全垂域大模型在杭州第19届亚洲运动会(以下简称杭州亚运会)期间得以大范围应用。安恒信息公司在2025年哈尔滨举行的第九届亚洲冬季运动会(以下简称哈尔滨亚冬会)筹备及举办期间,将安全智能体全面应用于安全保障,实现对赛事网络7×24小时全维度监测,保障了开闭幕式、赛事直播、场馆运营等核心场景安全,做到了万无一失。
本书基于安恒信息公司多年工作经验与产品成果,结合AI领域主要的理念、技术和应用编写而成。通过对本书的学习,读者能够了解和掌握AI关键技术与核心价值、面临的安全风险及治理措施,以及AI在网络安全领域的深度应用等相关知识。
本书既可作为AI、网络安全领域业务人员的技术参考书,也可作为AI安全咨询、测评认证、安全运维、安全建设、安全管理等专业人员的技术读物,还可作为高等院校AI与网络安全相关课程的教学参考书。
随着AI技术的不断创新和突破,AI将深度嵌入网络安全、数据安全的各个层面和环节,在保障国家关键信息基础设施安全、维护社会网络安全稳定等方面发挥更为重要的作用,成为捍卫数字世界安全的坚固壁垒。在国家政策大力扶持AI发展的背景下,网络安全行业应积极拥抱AI技术,加强技术研发和应用创新,培养相关专业人才,推动智能体在网络安全、数据安全防护中的广泛应用,为我国数字经济的健康发展和网络空间安全提供坚实保障。期望本书为你打开全新的AI安全视野,并为你的工作提供有益参考。
范 渊
2025年10月
第1章 AI的历史与发展趋势 自1956年达特茅斯会议提出人工智能(Artificial Intelligence,AI)的概念以来,AI经历了数十年的发展,已经比较成熟。自2023年ChatGPT爆火之后,AI吸引了全球的关注,其发展驶入快速车道。当前,AI应用已经非常普遍,常见的包括ChatGPT、DeepSeek、豆包、通义千问、文心一言、Gemini、Kimi、Grok等。然而,AI的发展演进之路并非一帆风顺,而是经历了多个历史阶段,其中也出现了一些具有代表性的关键技术,下面进行介绍。
1.1 技术演进及关键节点AI自诞生以来,已走过了波澜起伏的演进历程,从早期的理论奠基到多次高潮与低谷,再到当今的蓬勃发展,AI技术不断突破瓶颈、拓展应用边界。在这一过程中,不同时期的技术特点和关键节点值得梳理。从宏观上来说,我们可将AI技术的发展划分为奠基期、起步发展期、反思发展期、应用发展期、低迷发展期、稳步发展期和蓬勃发展期7个阶段。各阶段涌现出不同的研究范式,包括传统的符号主义(Symbolicism)、连接主义(Connectionism)、行为主义(Actionism)三大学派,以及不同时代兴起的代表性技术(如专家系统、机器学习、深度学习、大模型等)。本节将按时间脉络回顾AI技术的演进及关键节点,并结合其在网络安全领域的应用展开介绍。
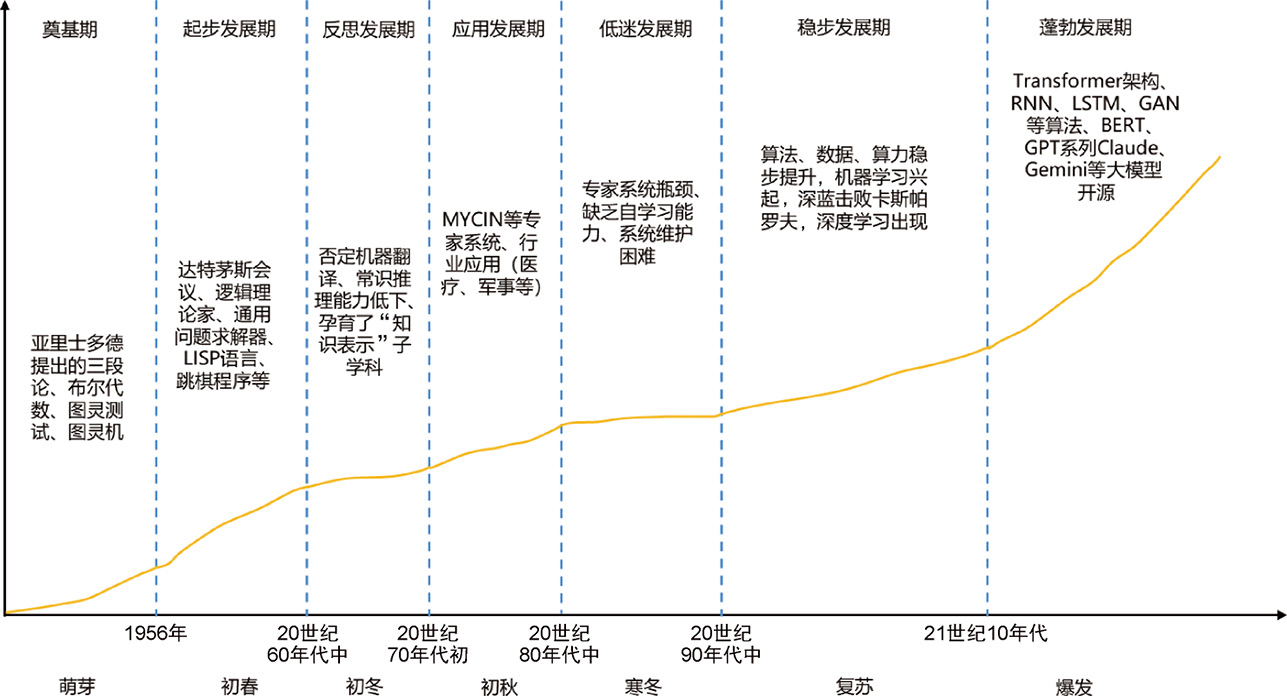
1.1.1 AI技术发展阶段 AI的发展经历了若干次高潮与低谷。学术界和产业界通常根据技术演进和行业动态,将AI的发展划分为7个主要阶段,如图1-1所示。
图1-1 AI发展历程
1.奠基期(1956年以前):概念孕育与理论奠基 AI并非始于工程实现,而是源自人类对“机器是否能思考”这一哲学问题的思考。在20世纪中叶以前,尽管“人工智能”尚未成为一门独立的学科,但关于智能本质的哲学探讨、形式逻辑的发展以及初步计算模型的构建,已为AI的诞生营造了思想和理论的沃土。这一时期的核心特征是对智能概念的形式化与对可计算性的探索,是AI从抽象构想走向技术体系的萌芽阶段。
最初的思想基础来自古希腊演绎推理体系,亚里士多德提出的三段论为结构化的推理形式提供了雏形。进入17世纪,莱布尼茨的“普遍演算”设想试图用符号运算模拟人类理性判断,已然具备原始的算法思维。到了19世纪中叶,布尔代数的创立进一步将逻辑操作转换为可供计算的数学表达。至此,智能被逐步还原为一系列符号与规则的组合过程。1943年,麦卡洛克与皮茨发表神经元模型论文,首次将神经活动建模为逻辑函数,并提出神经网络可以通过连接形成复杂逻辑运算,为日后深度学习的发展奠定了基础。“控制论之父”诺伯特·维纳在1948年提出了反馈与调节的控制机制理论,揭示了生物系统与电子系统之间的行为相似度,为后来的行为主义AI埋下了伏笔。
真正标志AI理论基础确立的是艾伦·图灵的两项核心贡献。其一是他于1936年提出的“图灵机”模型,它揭示了一种普适的计算方法,并证明任何可形式化表达的算法均可在图灵机上实现,为后来一切计算形式提供了理论上限。其二是他于1950年发表的《计算机器与智能》一文,其中提出了著名的图灵测试,首次以一种实用、可验证的方式界定机器是否具有“智能”。这一时期虽然缺乏复杂模型或系统应用,但构建了AI的哲学根基、逻辑范式与计算模型,为其后独立学科的形成提供了理论准备。
2.起步发展期(1956年—20世纪60年代中):学科奠基与初步智能的实现 AI在20世纪50年代中期完成学科化的转变。1956年,由约翰·麦卡锡、马文·明斯基等人发起的达特茅斯会议上,正式提出了“人工智能”这一术语,并首次将其定义为研究“如何使机器表现出智能行为”的独立学科,学术界普遍将这一年视为AI的真正诞生年。
达特茅斯会议之后,AI研究迅速发展,进入了所谓的“初春阶段”。这一时期的核心特征是高度乐观的预期与技术路线的明确确立,研究者相信只需10年便能实现通用AI。受符号主义思潮的主导,AI主要聚焦在逻辑推理、问题求解和自然语言初步处理等高阶认知任务,认为智能可通过操作抽象符号系统来模拟。多项具有里程碑意义的系统相继问世。由赫伯特·西蒙与艾伦·纽厄尔设计的“逻辑理论家”(Logic Theorist)程序可自动证明数学定理,其继任系统“通用问题求解器”(General Problem Solver,GPS)更试图将人类的解题策略形式化。与此同时,LISP语言的诞生极大地提高了符号处理效率,为AI系统的开发提供了核心工具。在应用探索上,亚瑟·塞缪尔的跳棋程序通过自我对弈改进策略,展示出早期“学习”能力,而ELIZA则首次模拟出类人对话,使“人机交互”成为AI研究的前沿课题。
然而,早期AI也面临计算资源不足、知识获取瓶颈以及对常识的处理能力低下等根本性挑战。大多系统仅能在封闭领域内有效运行,面对开放环境或模糊语言即失效。尽管如此,这一时期所确立的研究框架,如状态空间搜索、启发式方法、逻辑推理系统、模式匹配机制等,构成了AI基础技术体系的雏形,并成为日后机器学习和自然语言处理技术演进的底座。
3.反思发展期(20世纪60年代中—20世纪70年代初):技术瓶颈与范式危机 从20世纪60年代中期开始,AI研究进入技术与认知的双重低谷,曾经“十年内实现通用AI”的幻想被逐渐打破。在技术层面,最突出的挑战是组合爆炸问题的加剧。在自动定理证明方面,以状态空间搜索为核心的方法在问题规模稍微扩大后就迅速失效。此外,缺乏常识推理能力成为当时AI的致命短板,机器无法像人类一样灵活应对例外和隐含前提,导致诸多推理结果脱离语义和语境。
这一时期AI发展的“危机感”集中体现在几个标志性事件中。1966年,美国国家科学研究委员会发布的ALPAC报告对当时的机器翻译研究进行了全面否定,指出其进展远低于预期、投入与产出严重不对称,建议立即削减政府经费支持。该报告对整个AI领域的研究人员的信心造成重挫。1969年,明斯基与佩珀特合著的《感知机》一书对早期神经网络的理论能力进行了系统性质疑,指出单层感知机无法解决异或(XOR)问题,并缺乏对非线性边界的处理能力。这项理论结果导致连接主义研究几近停滞,神经网络在整个70年代基本被主流学术所摒弃。
但是危机之中也催生了反思。研究者开始意识到,通用AI的目标在当时过于理想化,需要将精力转向“可落地”的狭义智能。知识的系统建构与表达成为新的研究重点。这一转向孕育了“知识表示”的子领域,强调如何用形式逻辑、语义网络、框架结构等方法来表达专家知识。这为后来的专家系统技术奠定了方法论基础,也标志着AI从“算法驱动”转向“知识驱动”的探索。
4.应用发展期(20世纪70年代初—20世纪80年代中):专家系统崛起与知识驱动的产业黄金时代 应用发展期是AI第一次产业化浪潮的核心阶段。它标志着AI首次由“研究”向“产品”转型,进入了政企高度关注的黄金时期。此时的AI研究者逐渐放弃短期实现通用AI的目标,转而聚焦于可控、可解释的狭域智能任务,强调利用专家知识解决特定场景中的问题。由此催生的“专家系统”成为这一时期最具代表性的技术形式,也标志着AI从学术理论走向产业化应用。
专家系统的核心在于构建“知识库”与“推理引擎”,将人类专家在某一特定领域中的经验转换为机器可处理的规则集合。不同于此前依赖通用算法解决通用问题的方式,专家系统强调问题的结构化建模与规则推理逻辑,其设计目标更接近“人工辅助决策”而非“智能替代”。斯坦福大学开发的MYCIN系统是该时期的代表作之一,该系统能为血液细菌感染的诊断与治疗提供决策建议,虽然规则有限,但在小范围内表现出媲美人类医生的判断力。
与此同时,“知识工程”成为AI发展的技术主轴之一。研究者开始探索如何从专家口述、操作经验或文档中系统提取知识,如何表示事实与规则之间的因果关系,如何控制推理路径以避免规则冲突。形式化知识表示技术(如语义网络、产生式规则、框架表示)得到快速发展。这些技术日后广泛影响了信息安全规则库、威胁情报建模与安全策略制定等系统的设计。
AI的实际应用价值引发了多个国家的战略投入。1982年,日本启动“第五代计算机系统”(Fifth Generation Computer System,FGCS)计划,意图通过并行逻辑推理打造具备知识处理能力的新型机器。美国国防高级研究计划局(Defense Advanced Research Projects Agency,DARPA)则在战略计算项目中部署AI来进行自动决策、战场态势分析与敌情预判。这一阶段,AI首次被纳入国家安全与战略技术体系中,成为信息作战中的关键支撑力量之一。
然而,随着知识库规模的扩展与系统部署的复杂化,专家系统的局限性也逐步显现:知识获取成本高昂、规则冲突难以管理、环境变动造成系统性能大幅波动。“知识获取瓶颈”问题成为悬在头顶的“达摩克利斯之剑”,也为下一阶段的技术动荡埋下了伏笔。
5.低迷发展期(20世纪80年代中—20世纪90年代中):知识瓶颈冲击下的系统性退潮 自20世纪80年代中期开始,AI技术的发展进入长达10年的“寒冬”时段。AI在遭遇理论瓶颈、工程成本与预期落差的三重夹击中,陷入第二次学术与产业的全面低谷。
导致AI热潮降温的直接原因是专家系统大规模部署后的“知识获取瓶颈”与“系统维护危机”。专家系统构建极度依赖人工编码的规则库,缺乏自学习能力,且无法适应动态环境变更。一旦部署规模扩大,知识库冲突与冗余频发,系统更新维护成本高得惊人。例如数字设备公司(Digital Equipment Corporation,DEC)开发的XCON系统,尽管初期带来效益,但后期更新一条规则所需的人力成本甚至超过其所带来的收益。此外,专家系统的表现高度依赖领域边界,一旦超出预设情境,其推理结果迅速崩塌,暴露出脆弱的泛化能力。
AI产业链也因此受创严重。1987年,大批生产LISP专用AI工作站的公司相继破产,AI硬件市场崩溃,资本市场对“智能”概念的估值断崖式下跌,政府层面对大型AI计划逐步撤资。日本的第五代计算机系统项目在1992年宣告停摆,美国DARPA的战略计算计划亦于1993年提前终止,AI被逐步边缘化。
尽管表面进入低潮,AI内部却悄然发生了一场范式转移。1986年,鲁梅尔哈特与辛顿等提出反向传播(Back Propagation,BP)算法,成功训练出多层神经网络。虽然当时硬件性能尚不足以支撑深层网络,但这一理论创新为日后“深度学习”的崛起埋下种子。与此同时,贝叶斯网络、支持向量机(Support Vector Machine,SVM)、隐马尔可夫模型(Hidden Markov Model,HMM)等统计学习方法逐步进入主流,取代专家系统成为新一代AI算法体系的候选。
6.稳步发展期(20世纪90年代中—21世纪初):数据驱动与技术整合的再生阶段 AI自20世纪90年代中后期开始缓步回暖,进入“复苏”再生期。这一阶段AI技术开始从算法、数据、算力三个方面悄然聚合,逐步形成坚实的工程体系,AI实现了从专家系统的规则依赖向“数据驱动”范式的根本转型。
这一时期确立了机器学习(Machine Learning,ML)的主导地位。相较于此前人工编码规则的专家系统,机器学习强调从大规模数据中自动归纳规律,通过建模与训练获得通用的预测能力。20世纪90年代,大量高性能分类与回归算法,如SVM、决策树、k 近邻、随机森林等算法应运而生。与此同时,无监督学习(如聚类、降维)与概率模型(如贝叶斯网络、HMM)也在自然语言处理、行为建模等场景中得到广泛应用。
这一阶段的标志性事件是1997年IBM公司的深蓝系统击败国际象棋世界冠军卡斯帕罗夫。深蓝系统结合了高性能搜索算法与专家知识库,是符号主义与工程优化的产物。虽然不具备学习能力,但其成功向全球展示了AI在专业任务上超越人类的可能。这一事件不仅提振了学术界士气,也重塑了公众对AI能力边界的认知。
互联网的普及、传感器与数字设备的广泛部署,积累了大量结构化与非结构化数据,成为训练AI系统的养料。在图像、语音、日志等高维数据不断增长的背景下,研究者意识到传统模型的能力边界,开始尝试构建更深、更复杂的模型结构。尽管当时的计算资源尚无法支撑大规模神经网络的训练,但2006年辛顿等人提出的“深度信念网络”(Deep Belief Networks,DBN)标志着深度学习的预热阶段开始。
7.蓬勃发展期(21世纪10年代至今):深度智能与模型爆炸的时代转折 在这个时期,AI步入前所未有的“爆发”阶段,开启了其发展史上的“第三次高潮”。这一阶段最具决定性的技术突破是深度学习的全面崛起,它不仅在感知任务中超越人类能力,也重新定义了AI在语言理解、内容生成,乃至人类社会结构中的角色。AI不再是“辅助工具”,而是走向通用AI路径的关键动力。
2012年,加拿大多伦多大学辛顿团队提出的AlexNet模型在ImageNet图像识别竞赛中将错误率从26%骤降至15%,直接引爆了深度卷积神经网络(Deep Convolutional Neural Network,DCNN)的大规模研究热潮。自此,图像识别、语音识别、自动翻译、文本生成等任务在深度学习的加持下迅速取得突破,AI能力实现质变。循环神经网络(Recurent Neural Network,RNN)、长短期记忆(Long Short-Term Memory)网络、生成对抗网络(Generative Adversarial Network,GAN)、自注意力网络(Self-Attention Network)等网络结构层出不穷,为不同任务场景提供高效建模能力。
2017年,谷歌(Google)公司提出的Transformer架构彻底改变了自然语言处理的建模方式,形成了“预训练+微调”的新范式。这一范式催生了大模型时代。从BERT、GPT-2、GPT-3到GPT-4、Claude、Gemini等数百亿乃至万亿参数规模的模型接连涌现,AI在语言生成、编程、写作、知识问答等任务上达到前所未有的效果。
2022年,OpenAI公司推出ChatGPT,并引发全球范围内的应用浪潮,其用户量在上线两个月内突破1亿,成为历史上用户量增长最快的互联网产品。与此同时,开源社区也纷纷响应,Meta、Mistral、DeepSeek等发布多个开源大模型,加速了大模型技术的快速推广和应用。
蓬勃发展期不仅是AI技术的黄金时代,也开启了AI安全治理的新时代。大模型的力量昭示着通用AI的曙光,但其开放性、复杂性也要求我们重新构建技术、伦理、法律与治理的边界。在这一历史性转折中,网络安全不再是AI部署的配套工具,而成为保障其健康演化的核心支柱。
1.1.2 AI关键技术发展演进 经过7个时期的发展,从抽象的计算模型、早期符号推理系统到深度神经网络与大规模预训练模型,AI的每一次跃迁都伴随着方法论的更替与计算能力的飞跃。更重要的是,许多AI关键技术的进步不仅推动了学科本身的发展,也在网络安全、自动控制、医学、金融等行业产生广泛影响。
1.图灵机与图灵测试 图灵机是图灵在1936年提出的抽象计算模型,定义了一台理想化机器如何通过读写符号串来执行算法,使人们认识到任何复杂计算过程都可由简单读写动作组合而成,奠定了可计算性理论的基础,为电子计算机的发明提供了理论支撑。
基于图灵机模型,图灵在1950年的论文中设想了著名的图灵测试,提供了检验机器智能的操作性标准。虽然图灵测试并非严格定义智能的充分条件,但它直观地引发了后来大量关于AI能力评估的讨论。
图灵机体现了算法与计算模型的力量,而图灵测试则引发了机器智能判定的思想实验。这两项发明标志着AI技术起步阶段的思想精髓:一方面,将智能问题形式化为计算模型;另一方面,思考如何客观衡量机器的智能水平。
2.感知机 感知机由美国科学家弗兰克·罗森布拉特于1957年提出,被誉为最早的人工神经网络和机器学习模型之一。
感知机的基本原理是模拟生物神经元的线性加权求和并输出结果。简单来说,它接收多个输入信号,每个输入乘以对应的权重后求和,然后通过一个阶跃激活函数输出二分类结果(0或1)。感知机的学习算法是通过给模型提供带标签的样本,不断调整各输入权重,逐渐使输出结果逼近期望标签。这种自适应调整权重的规则是机器学习的雏形。1958年,罗森布拉特在IBM公司的资助下建造了Mark Ⅰ计算机。
感知机模型展示了机器可以通过训练数据自动改进的可能性。然而,感知机的局限也很明显。1969年,明斯基和佩珀特证明单层感知机无法处理XOR等线性不可分问题。由于当时多层网络和非线性激活的训练方法尚未出现,因此感知机研究在20世纪70年代陷入停滞。
感知机奠定了人工神经网络的基本框架和机器学习的基础,是后来连接主义和深度学习(Deep Learning,DL)的基础。其学习规则(感知机算法)也影响了后来的梯度下降法等优化算法的演进。
3.专家系统 专家系统的核心思想是将人类专家在特定领域的知识和决策策略以规则的形式编码进计算机系统,模拟专家解决问题的过程。典型的专家系统包含知识库(存储领域知识,如规则、事实)、推理机(依据知识库进行逻辑推理的引擎),以及人机交互界面等部分。专家系统通常采用产生式规则(IF-THEN规则)来表示知识,并通过正向推理或反向推理机制来得出结论。例如MYCIN系统中有规则“IF病人感染类型为细菌且白细胞计数>…THEN 建议抗生素X”,推理机根据患者数据匹配规则,从而推荐治疗方案。
从20世纪70年代到20世纪80年代,专家系统在矿产勘查、教学等多个领域得到广泛应用,证明了AI可以通过符号规则解决实际复杂问题,在工业界掀起热潮。
然而,专家系统也有固有缺陷,即知识获取难(需要专家将经验显性化,过程费时费力),缺乏自适应性(规则一旦写定不易修改,环境变化时系统性能下降),无法处理海量数据(规则过多时推理速度和一致性成问题)。随着应用拓展,这些问题日益凸显。但在解决这些问题的过程中,孕育了知识工程学科,推动了知识表示(如语义网、框架、知识图谱)等技术的发展。
4.机器学习技术 机器学习作为AI的关键技术之一,专注于研究如何让机器从数据中自动学习规律,在20世纪80年代中后期兴起并在90年代逐渐壮大。
机器学习技术通过算法从大规模样本数据中训练模型,使其能够对新数据进行预测或分类。机器学习技术涵盖监督学习、无监督学习和强化学习(Reinforcement Learning,RL)等范式。在监督学习方面,决策树(如ID3、C4.5算法)通过信息增益选择特征,自动归纳分类规则;支持向量机(SVM)可以在高维空间找到最大间隔超平面,具备优秀的分类性能;朴素贝叶斯分类利用概率统计为文本分类等问题提供了高效、简单的解决方案。此外,集成学习思想出现,通过Bagging、Boosting等方法集成多个弱模型提高精度,如随机森林和AdaBoost算法等。在无监督学习方面,聚类算法(例如k 均值算法)用于从未标记数据中发现模式,主成分分析(Principal Component Analysis,PCA)用于降维发掘数据主轴。HMM和条件随机场在语音识别、自然语言标注中发挥重要作用。
机器学习技术的引入,使AI系统能够更好地适应复杂、多变的数据,大幅提升了如语音识别、计算机视觉等领域的性能。例如,语音识别在20世纪90年代采用HMM和神经网络混合模型,错误率相比20世纪80年代降低了约一半;视觉领域的手写数字识别在LeNet网络和SVM等支持下,精度达到99%以上。在应用上,机器学习催生了推荐系统(利用协同过滤算法从用户行为中学习偏好)、垃圾邮件过滤(贝叶斯过滤)等,实实在在改善了信息服务质量。可以说,机器学习为AI带来了从经验中学习的能力,成为AI进入各行各业的核心驱动力之一。
5.深度学习 深度学习是近年来AI飞速发展的核心动力,其本质是多层人工神经网络的训练与应用,通过构建包含多隐层的网络结构来自动提取数据中的高层次抽象特征。
经典的深度学习模型包括卷积神经网络(Convolutional Neural Network,CNN)、RNN和Transformer模型等。CNN在图像处理上具有卓越表现;RNN及其改进LSTM/GRU,在序列数据(语音、文本)上效果显著;引入注意力机制的Transformer模型,在自然语言处理领域引发范式转变。这在许多应用领域带来质的飞跃。例如,在ImageNet图像识别中,深度CNN将错误率从26%降到3%以内;语音识别中,用深度神经网络取代GMM-HMM后错误率降低30%以上。深度学习的发展还推动了强化学习的突破,如AlphaGo结合深度网络评估棋局价值与策略。
深度学习已成为当前AI技术的基石,被广泛应用于自动驾驶、医疗影像、推荐系统、自然语言对话等各个领域,为AI赋能千行百业提供了强大工具。
6.大模型与GPT 2020年后,AI模型规模(参数量)呈现爆炸式增长,标志着进入了大模型时代。大模型通常指参数量达数十亿乃至上千亿级的AI模型,典型代表是各类大语言模型(Large Language Model,LLM)。
这些AI模型通过在海量语料上进行自监督预训练,学习到丰富的知识和语言模式,展现出惊人的内容生成和理解能力。以OpenAI公司的GPT系列为例,2018年的GPT-1只有1.17亿参数,2019年的GPT-2的参数增至15亿,引起关注;2020年的GPT-3飙升到1750亿参数,并凭借超大规模和强大的生成能力,在自然语言处理领域引发轰动。GPT-3能在零样本或小样本情况下(无须或仅需极少任务示例)完成各种自然语言处理任务,如写文章、问答、翻译、代码生成,展示出一种通用语言智能,被誉为自然语言处理领域的范式转变。之后,更强的模型不断出现,如谷歌公司的PaLM(5400亿参数)、OpenAI公司的GPT-4等性能进一步提升;2023年年初推出的ChatGPT-4(基于GPT-4),据估计参数量达到了1.8万亿,通过与人交互的指令微调,极大增强了对话效果,真正让大众体验到拟人对话AI的魅力。2023年Meta公司发布了Llama系列模型并提供给研究社区,使得开源大模型生态也蓬勃发展。不同版本的GPT参数量对比如表1-1所示。
表1-1 不同版本的GPT参数量对比
版本
GPT-1
GPT-2
GPT-3
GPT-4
发布日期
2018
2019
2020
2023
参数量
1.17亿
15亿
1750亿
约1.8万亿
大模型基于超大规模参数赋予模型对复杂模式的理解与表达能力、零样本/少样本学习能力,即使缺乏特定任务训练也能举一反三解决问题,被广泛应用于内容创作、智能客服、辅助编程、科研辅助等众多领域。
1.1.3 AI技术学派 AI作为交叉学科的产物,其研究方法和思想路径自诞生之初便呈现出多元并进的格局。根据思维建模方式与智能实现机制的不同,AI领域在发展过程中逐渐形成了三大学派:符号主义、连接主义和行为主义。
1.符号主义学派:逻辑推理的智能幻想 符号主义学派,又称逻辑主义或计算主义,是AI早期的奠基学派之一,主张以形式逻辑和符号操作来模拟人类的思维过程。该学派的核心观点是“物理符号系统假设”,由艾伦·纽厄尔与赫伯特·西蒙提出,认为任何智能系统都可通过对符号的物理操作实现。
在20世纪50年代至70年代,符号主义成为AI研究的主流,其代表性成果包括逻辑理论家、通用问题求解器(GPS)等,被广泛应用于证明、规划、博弈等复杂任务。约翰·麦卡锡发明的LISP语言更是成为符号主义编程的代名词。而专家系统的兴起,则使符号主义在20世纪80年代进入产业化高潮,典型代表如医学诊断系统MYCIN与计算机配置系统XCON。
然而,符号主义也面临重大挑战。其模型依赖人工编码的知识规则,难以适应动态复杂环境,尤其在面对海量非结构化数据与感知任务时表现乏力。这种局限在实际网络安全应用中尤为突出,例如面对高度变异的恶意样本、加密通信与多模态攻击路径,传统符号规则系统往往无能为力。尽管如此,符号主义在知识图谱、规划系统、语义推理等领域仍具深远影响。
2.连接主义学派:神经网络的复兴与主导 连接主义学派,又称仿生主义或神经计算学派,试图通过模拟生物神经元之间的连接来重现智能过程。其历史可追溯至1943年麦卡洛克与皮茨提出的神经元模型,该模型成为后续神经网络的理论基础。1957年,罗森布拉特提出感知机模型,揭示了机器可通过经验数据进行学习的可能性。
尽管感知机在1969年被指出存在严重的表达能力不足(无法解决非线性问题),导致连接主义陷入低谷,但20世纪80年代反向传播算法的提出极大地提升了多层神经网络的训练效率,使连接主义迎来复兴。此后,Hopfield网络、自组织映射(Self-Organizing Map,SOM)等模型陆续问世,构建了神经网络多样化发展的图景。
进入21世纪,深度学习技术的研究突破使连接主义成为主导AI发展的技术力量。尤其在图像识别、语音识别、自然语言处理等任务中,多层神经网络通过端到端训练展现出前所未有的性能,颠覆了传统特征工程范式。在网络安全领域,连接主义模型被广泛用于入侵检测、恶意样本识别与网络流量分析中,能够通过历史攻击行为数据进行自动特征提取与攻击预测,极大提升了检测系统的适应性与覆盖率。
代表人物如辛顿、杨立昆、约书亚·本吉奥因其对深度学习的奠基贡献获得图灵奖,进一步巩固了连接主义在当代AI发展中的中心地位。
3.行为主义学派:从环境交互中诞生智能 相较于关注认知结构与神经建模的符号主义和连接主义,行为主义学派强调智能是生物体在与环境交互过程中展现出来的适应行为。
真正将行为主义作为AI学派发扬光大的是罗德尼·布鲁克斯等人提出的“行为主义机器人学”思想。该理念反对中央控制与全局建模,主张通过模块化的感觉- 行动系统构建智能体,使其在无全局知识的情况下通过局部感知与响应完成复杂任务。这种思路催生了一系列生物启发式机器人,开创了现代机器人行为控制的新路径。
行为主义在强化学习与机器人技术中获得广泛应用。尤其在深度强化学习(如AlphaGo、Dota2AI)中,智能体通过与环境不断交互,在奖惩机制下自我调整策略,完成复杂任务。在网络安全中,行为主义理念亦体现在攻击模拟、对抗训练、策略优化等方面,AI系统通过与潜在威胁行为交互进行模拟博弈,优化防御响应策略。
总体而言,三大学派在理论建构、技术实现与应用推广层面各有侧重,互为补充,共同构成了AI多维发展的基础框架。在AI与网络安全深度融合的今天,符号主义提供可解释性基础,连接主义支撑智能感知与识别,行为主义则推动智能体的主动防御与自适应协同,为构建安全、可靠、强大的AI系统奠定了方法论根基。
1.2 AI技术发展趋势1.2.1 AI智能体从辅助工具到自主决策的跨越 AI智能体是在大模型基础上构建的自主决策系统,它是一种基于神经网络构建的多模态感知系统,具备环境感知、实时数据分析、动态行为策略生成等能力,支持复杂任务的自动化决策;AI智能体还可以建立用户模型,记录用户的偏好,学习历史交互信息,从而提供更加个性化的服务。本质上,AI智能体实现了从被动工具到主动执行体的跃迁,由单一任务执行到复杂系统协作的模式重构,实现了从响应指令到自主执行任务的范式升级。
1.决策机制升级 AI智能体决策机制升级的主要表现是从被动的指令执行升级到任务的主动规划与执行。在任务自主分解阶段,传统工具需要用户明确每一步操作,而AI智能体能自动解析复杂任务并拆解成为多个子任务。在动态策略调整方面,它能够基于实时环境反馈,优化任务执行方案。例如,百度智能云发布的营销供电方案智能体,其依赖历史数据沉淀与实时参数调整形成决策机制,通过意图识别、任务拆解,调用应用程序接口(Application Program Interface,API)等自动生成多套供电方案。
2.任务处理能力跃升 AI智能体任务处理能力跃升的核心在于分层规划、多模态感知与工具协同的技术融合。它通过规划模块将复杂任务拆解为多个可执行的子任务,集成外部API与物理设备控制能力,形成“感知- 决策- 执行”闭环,突破了传统的单一任务的执行模式。例如,在工业质检领域,针对产品或系统缺陷的位置、类型,以及量化等关键维度,工业质检智能体融合视觉识别与设备控制,能够在秒级时间内完成从检测到停机的决策,精准定位瑕疵,及时进行后期响应,极大推动质量控制从“事后拦截”转向“缺陷预防”。
3.环境交互进化:从预设场景到动态适应 AI智能体的环境交互进化能力正在从预设场景执行向开放环境动态适应跨越式发展。智能体一方面基于在线强化学习框架,通过实时环境反馈调整策略参数;另一方面通过多模态环境模型,构建可预测环境变化的神经网络引擎,使AI智能体完成“环境理解- 策略优化- 行为修正”的闭环适应力,并且几十倍地缩短新场景的适应时间。例如,搭载AI智能体的灾难救援机械狗可成为复杂环境下的全能救援尖兵,重新定义灾害救援范式。它具备多地形自适应能力,可实时识别斜坡、废墟、积水等复杂地形,动态调整步态,自主重构行动路径。
4.协作模式重构 AI智能体正推动协作模式从简单任务分配到复杂系统化协作的范式升级。基于分布式决策架构,智能体通过点对点通信实现动态任务分配与实时数据交换,还可以基于多角色协同机制,构建虚拟组织架构模拟人类分工,协同完成复杂任务。例如,智能仓储协同场景下的“货到人”拣选系统,通过视觉识别货箱,机械臂智能体与智能搬运智能体协同完成订单合并任务。
1.2.2 小模型的高效化与本地化应用 小模型与大模型的核心区别主要体现在参数规模、训练资源需求和应用场景3个维度。大模型通常具有千亿级参数,依赖海量数据和昂贵算力资源,适合开放场景下的复杂任务;而小模型参数规模则控制在百万至千万级别,训练成本低且部署灵活,更专注于垂直领域的特定需求。
1.高效化实现 小模型主要通过模型架构轻量化、训练优化技术、硬件协同优化、训练范式革新等技术手段来实现高效化。模型架构轻量化方面,通过深度可分离卷积、分组卷积来代替标准卷积,实现卷积结构创新;通过采用延迟下采样、小卷积核替代、动态稀疏计算来完成全局架构优化策略。在训练优化技术方面,小模型通过知识蒸馏、动态学习率调度、混合精度训练和参数高效微调(如LoRA)等技术,在减少计算资源消耗的同时保持或提升模型性能。在硬件协同优化方面,小模型通过算子融合、内存访问优化和硬件专用指令集(如神经网络处理器加速深度可分离卷积)实现计算效率倍增。在训练范式革新方面,通过联邦学习框架,实现多终端协同训练,垂直领域的小模型在保证隐私的前提下,准确率得到极大提升。
2.本地化部署实现 小模型本地化部署是指将轻量化AI模型直接部署在用户自有硬件设备(如本地服务器、边缘终端、个人计算机等)上运行,无须依赖外部网络或云平台,有效实现了所有输入数据在本地处理,结果直接输出,避免敏感数据外传,满足隐私合规要求。小模型针对特定任务(如客服问答、图像识别)进行轻量化设计和定制化训练,在参数量级较低(通常百万至十亿级)的情况下,通过裁剪、量化等压缩技术,可适配有限算力设备,在垂直领域私有环境中实现安全可控、高效低耗的智能应用。例如,深圳证券交易所(以下简称“深交所”)某机构基于Ollama本地私有云部署DeepSeek-R17B模型,集成AnythingLLM构建私有文档检索系统,实现合同条款秒级语义查询,完成客户交易数据本地闭环处理,满足PCIDSS合规要求。
3.本地化部署提升安全能力 (1)安全风险显著降低。小模型本地化部署通过数据物理隔离与自主管控显著降低安全风险。敏感数据全程存储于企业内网或私有服务器,规避云端多租户环境下的跨账户渗透风险;本地部署时可采用国产化硬件与开源框架(如Ollama+昇腾芯片),避免境外技术依赖及软硬件系统中网络后门的潜在风险。
(2)数据控制权大大提升。本地部署模式下,企业能完全掌控数据存储与访问权限,使得数据永不离开本地环境;可灵活定制数据隔离策略实现物理隔绝敏感数据。
(3)性能与稳定性得到有效保障。本地化部署能达到毫秒级响应(10 ms内),而且无网络传输瓶颈,非常适合工业质检、高频交易等实时场景;还能实现断网环境下持续运行(如关基设施、急救等场景),有效保障业务连续性。
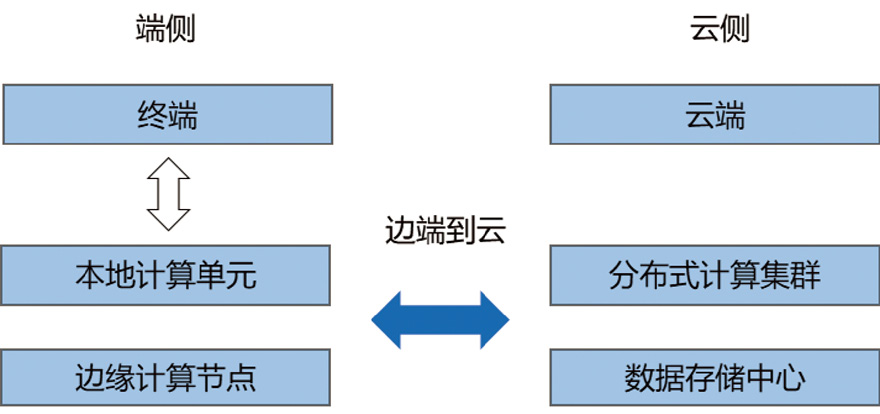
4.端云协同架构 端云协同架构是一种将终端设备(端)、边缘节点(边)与云端数据中心(云)的计算资源动态整合的分层智能体系,通过任务分流与数据联动实现高效能、低延迟的服务响应。端云协同架构如图1-2所示,它正成为小模型部署的主流范式。通过合理的任务切分与资源调度,企业可兼顾响应速度、数据安全与计算成本,实现智能化场景的规模化落地。
分层任务被分配时,在云侧让其承载复杂模型训练与全局优化(如语义解析、知识蒸馏),输出能力至边缘节点,而在端侧则执行实时感知与轻量化推理(如意图识别、图像预处理),响应速度达毫秒级。在动态资源协同方面,可根据任务复杂度,动态地将任务分配至终端/云端,实现智能化的算力调度。为加强数据流优化,可将数据在端侧预处理后只把关键数据上传,达到有效降低带宽消耗的目标。
图1-2 端云协同架构
1.2.3 生成式搜索重构信息获取模式 生成式搜索指基于大模型的智能信息检索范式,其核心在于理解用户意图并直接生成结构化答案,而非仅返回网页链接列表。它通过语义理解引擎突破关键词局限,基于动态知识整合实现跨模态信息合成,结合任务自治能力自动分解复杂指令,推动信息获取从“被动检索链接”向“主动生成答案”的范式跃迁。
1.交互模式变革 生成式搜索通过问答式交互取代关键词搜索,基于对话记忆实现多轮交互,同时拥有动态任务执行能力。传统搜索模式下,搜索返回的是网页链接列表,用户需主动点击筛选信息;而生成式搜索则直接输出结构化答案,并通过诸如步骤指南、对比表格等形式呈现。例如,在医疗搜索场景下,用户可实现提问症状就能即时获取诊断建议而非医学论文链接;在方案预算制定场景下,通过修改指令“刚才的方案追加预算限制”,系统会自动继承前序参数生成新方案,降低交互频次。
2.内容形态重构 AI智能体基于结构化答案、多模态形式与实时性信息等手段实现内容形态重构,其本质是从“静态信息堆砌”转向“动态知识服务”。生成式搜索通过动态知识图谱整合多源数据,将分散信息转换为搜索结果的结构化表达。同时,多模态融合升级内容载体,通过文本、图像、视频等形式来呈现结果。例如,通过智能体搜索“节日礼物”时,能同步生成产品的三维演示模型与价格对比表,极大提升用户决策准确率和效率。
3.技术架构跃迁 生成式搜索技术架构的重构,本质上是信息处理范式从“检索- 匹配”向“理解- 生成”的跃迁。传统搜索引擎通过“关键词倒排索引”来处理数据,通过“词频匹配”来进行意图解析,通过“链接列表排序”来生成结果;而生成式搜索架构则通过多模态语义理解与检索增强生成(Retrieval-Augmented Generation,RAG)技术处理数据,通过查询扩展(Query Expansion)技术动态拆解及解析复杂意图,输出多模态内容(文本、图像、视频)。
1.2.4 技术主权与算力基础设施的全球竞争 AI领域技术主权与算力基础设施的全球竞争,主要体现在国家战略、技术自主、能源协同和产业重构这4个方面。
1.国家战略 针对AI领域的全球竞争,我国正通过系统性国家战略和政策布局加速构建技术主权与算力优势。《新一代人工智能发展规划》作为首部国家级战略文件,明确将AI定位为经济发展的新引擎,以加快AI与经济、社会、国防深度融合为主线,以提升新一代人工智能科技创新能力为主攻方向,向“人工智能研发攻关、产品应用和产业培育‘三位一体’推进”,形成人工智能健康持续发展的战略路径。2025年8月,国务院正式印发《国务院关于深入实施“人工智能+”行动的意见》,将“人工智能+”作为一种新发展范式提升至国家战略高度,从顶层设计层面系统规划了各行业各领域人工智能应用的创新发展路径,明确提出了六大重点行动和八大支撑体系,推动AI与经济社会各行业各领域广泛深度融合,加快形成人机协同、跨界融合、共创分享的智能经济和智能社会新形态。
2.技术自主 美国通过颁布《芯片与科学法案》等法案,强化技术出口管制,限制高端芯片对华供应,并通过TensorFlow、PyTorch等深度学习框架掌握核心算法知识产权。我国AI产业需要进行芯片与算法的双重突围,以“芯片攻坚、算法开源、场景深耕”为核心驱动,从技术追赶到局部领先,逐步重构全球AI竞争格局。例如,寒武纪、壁仞科技等企业推出自主架构芯片,降低对国际巨头的依赖;DeepSeek-R1提出“动态稀疏注意力”机制,中文语义理解效率超越国际竞品。
3.能源协同 全球AI算力能耗占比预估将从2025年的3%升至2030年的15%,能源效率成为竞争关键。我国算力需求呈指数级增长趋势,带来数据中心能耗、成本以及碳排放的不断攀升,解决能源供给与实现低碳运行成为数据中心可持续发展的重要议题。当前,国家积极布局全国一体化算力网建设,实施“东数西算”工程,推动国家枢纽节点新增算力占全国新增算力的60%以上,构建“1 ms城市算力网、5 ms区域算力网、20 ms跨枢纽算力网”的时延分级体系。
4.产业重构 AI技术与产品的应用使得传统信息与通信技术(Information and Communications Technology,ICT)产业分层模式被打破,正深刻重构全球产业格局。头部企业如英伟达、华为等同时布局芯片设计、算法框架和云服务,形成“芯片- 软件- 算力”全栈能力,这些都带来了供应链的垂直整合。
1.3 AI发展过程中存在的争议在AI发展过程中,学术界和产业界在参数量与AI性能、开源与闭源以及集中式与分布式部署等方面,存在着争议。这些争议一方面推动了AI技术的发展,另一方面不同发展路径之间存在的竞争加快了AI技术到产业应用的步伐。
1.3.1 参数量与AI性能是否成正比 在AI发展过程中,AI模型参数的数量,一直是衡量模型能力的关键指标之一。模型的参数量与模型的性能和表现是否成正比,一直是一个热门话题。
(1)参数规模对AI性能的正向作用
在神经网络中,参数包括权重和偏置。通常来讲,参数越多,大模型能力越强。复杂大模型通常具有超大规模参数(超过10亿个),并基于Transformer架构,通过对海量数据的预训练来提升大模型的性能。超大规模参数(如万亿级)推动多模态理解、长文本推理等前沿进展。
(2)参数规模的局限性
尽管大规模参数被视为提升AI性能的关键(例如增强模型复杂度和任务处理能力),但也有一定的局限性:计算资源消耗巨大、训练效率低下以及潜在过拟合风险等问题。另外,大模型参数扩张遵循缩放定律,当参数量超过临界点后大模型性能可能会急剧衰减。例如,GPT-3(1750亿参数)对比GPT-2(15亿参数)性能飞跃;而GPT-4(约1.8万亿参数)对比GPT-3提升幅度显著缩小,训练成本却呈指数级增长。GPT-2、GPT-3、GPT-4的对比如表1-2所示。
表1-2 GPT-2、GPT-3、GPT-4的对比
指标
GPT-2
GPT-3
GPT-4
训练数据量
45 GB文本(以WebText数据集为主)
570 GB文本(约3000亿Token)
约13万亿Token
参数规模
(最大版本)
15亿参数
1750亿参数
约1.8万亿参数
训练成本
约10万美元
约140万美元
6300万~1亿美元
性能表现
基础文本生成
零样本学习准确率58.7%
多模态交互、复杂逻辑推理
(3)参数膨胀需“三重平衡”
未来大模型的核心竞争力在于算法及参数,而非单纯的参数量竞赛,因此,需要在参数规模、数据质量、任务需求之间做到三重平衡。基于任务需求驱动参数规模,以最小参数量承载最强任务泛化力,避免陷入“参数竞赛”陷阱。
1.3.2 AI未来的发展方向是开源还是闭源 在AI发展过程中,开源与闭源一直存在争议,两者是AI技术发展过程中的不同表现形态。
开源模型正驱动普惠与生态裂变,有效降低门槛,实现成本革命。开源模型(如DeepSeek、Llama 3.1)通过开放代码和参数,显著减少企业训练成本,单台服务器即可部署高级模型,推动中小企业和开发者快速创新。部分开源模型在基准测试中超越闭源对手,如Llama 3.1在推理任务中表现优于GPT-4,正加速跨行业应用落地。另外,开源模式通过社区协作(如GitHub)吸引全球开发者贡献代码,形成“开源引流、闭源变现”的良性循环。
闭源模型有助于构建护城河、技术壁垒及商业闭环。闭源模型(如GPT-4、Sora)依赖高质量数据和算力投入,通过API调用收费绑定用户。例如,百度、OpenAI等公司通过闭源强化高端市场竞争力,支撑长期商业收入。
开源与闭源模型在AI未来发展中将长期共存互补,各自服务于不同场景需求,而非单一主导。两者可专注于不同的业务领域。开源模型主导普惠层,教育、初创企业依赖开源降低门槛,推动技术民主化;而高价值行业(如生物医药)优先选择闭源模型,在满足业务需求的同时保障安全与合规。未来,它们将会一起在生态融合中演进,开源加速技术扩散,闭源提供深度服务,最终形成“基础开源+商业闭源”的混合生态。
1.3.3 AI系统形态分化:集中式与分布式 AI系统的部署主要包括集中式和分布式两种。AI系统架构正从传统集中式向分布式演进,两者的分化源于对效率、容错率和场景适配度的不同需求,核心差异在于决策控制、数据流与资源分配模式。
集中式AI系统的决策与处理高度依赖单一中心节点(如云端超级模型),数据集中汇聚,全局优化能力强。它通过统一控制,简化协调流程,确保输出一致性与政策合规性,适合高精度任务;并且通过算力集中调配降低冗余投资,在通用AI任务(如语言生成)中表现卓越。但在这种形态模式下,模型迭代需全量重训练,灵活性不足,且海量数据集中处理加剧隐私泄露风险。
分布式AI系统的决策由多个自治智能体(如边缘设备或专业模块)共同承载,它们借助本地化处理与点对点通信进行协作,以达成系统目标。它的优势是资源分散部署,具有高弹性与容错率、节点故障仅影响局部、实时响应强等优点。但在此模式下,跨节点通信开销大,全局目标协调困难,易导致决策冲突或资源浪费,并且分散结构难以整合海量数据,通用能力弱于集中式模型。
未来AI发展将呈现明显的场景分层趋势,集中式架构主导高价值专业领域,而分布式架构推动普惠应用,形成互补而非对立的格局。这种分层模式将优化资源配置,提高技术落地效率。另外,混合模式(如“基座模型+垂直域模型”)结合集中式的资源高效性与分布式的弹性优势,为AI应用提供了更灵活的解决方案。例如,在金融风控场景下,基座模型处理通用特征,垂直模型针对反欺诈规则微调,结合联邦学习满足数据隐私要求。